본 내용은 fastcampus 딥러닝/인공지능 올인원 패키지 online을 정리한 것이다.
tensorflow 2.0 and Pytorch
tensorflow
1.x 에 비해 정말 쉬워졌다.
keras 인수
Numpy Array와 호환이 쉬움
TensorBoard, TFLite, TPU(구글)
많이 사용하지만 , 하지만 그 전에 많은 모델이 tensorflow 1.X에서 돌아간다.
예를 들어 : GAN
GPU를 먼저 할당하고 사용한다.
TFLite : 안드로이드
pytorch
Dynamic Graph & Define by Run
쉽고 빠르면 파이써닉하다.
어마어마한 성장률
pytorch 기준이 있다.
pytorch는 공부하는 목적에서 더 쉽다.
코드 간결하다.
현재 많은 데서 사용한다.
최근 trend에서는 논문에서 거의 pytorch를 사용한다.
파이써닉 파이썬 스러운 코드
tensorflow
numpy -> Tensor
np.array()
tensor
import tensorflow as tf
tensor = tf.constant([1,2,3] , dtype = tf.float32)
tensor
numpy array type 변경
import numpy as np
arr = np.array([1,2,3] , dtype = np.float32)
arrarr.astype(np.uint8)
tensorflow type 변경
tensorflow 는 unit8로 바꾸기
tf.cast(tensor, dtype=tf.uint8)
tensor to numpy
tensor.numpy()
np.array(tensor)
python 난수 생성
np.random.randn()
tensorflow
normal
uniform 불규칙하게 생성
mnist
(60000, 28, 28) => 60000만개 데이터
print(X_train.shape)
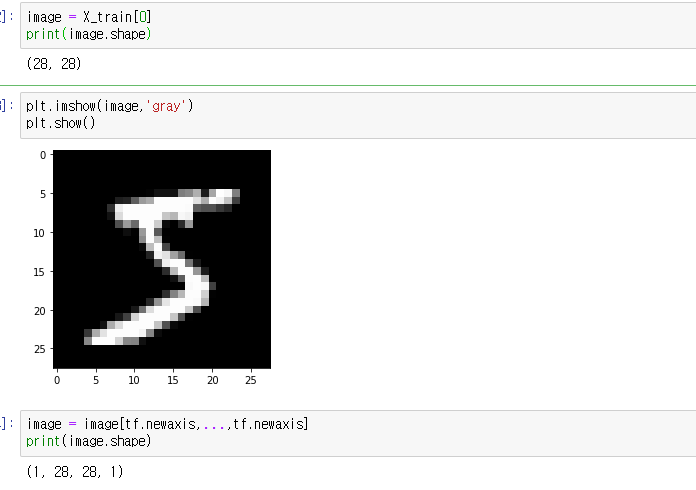
image = X_train[0]
plt.imshow(image,'gray')
plt.show()
3이 없으면 grayscale이라고 한다.
차원수 늘리기
1. np.expand_dims(X_train, -1) => 잴 마지막에 차원 늘린다.
reshape도 가능하다.
-1: 마지막에
0: 잴 앞에
차원 수 늘리고 싶으면 np.expand_dims(np.expand_dims(X_train, -1) ,0)
2. tensorflow tf.expand_dims
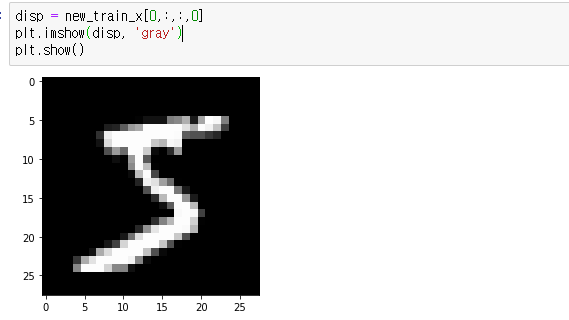
new_train_x = tf.expand_dims(X_train, -1)
print(new_train_x.shape)3. reshape
4. tf.newaxis
display 할때는 두개 있어야 한다.
shape를 줄이는 방식
np.squeeze() -> np.squeeze(new_train_x[0])
one-hot Encoding
from tensorflow.keras.utils import to_categorical
to_categorical(5, 10)
tensorflow layer
shape를 확인 먼저 하기
이미지 개수 , channel 등
[배치사이즈, height, width, channel]
feature extraction : 이미지가 가지는 것을 알아간다.
분류가 되는 것이아니고
convolution에서는 이미지가 들어간다. weigtht를 쌓으면서 한다.
filters: filter 개수만큼 channel 수가 생긴다. 지금은 채널을 한개 받았다. 몇개 채널이 나오게 되는지
weights, filters, channels
kernel_size :
strides: 몇번 겉이냐 strides 1이면 이미지 전체 사이즈에 변화가 없지만 2이면 절반 줄어들고 한다.
padding : SAME으로 하면 CONVOLUTION을 걸쳐도 이미지 사이즈에 변화가 없다. ZERO PADDING
VALID ZERO PADDING 없이 사이즈에 영향을 준다.
activation function : 없으면 none으로 생각한다.
tf.keras.layers.Conv2D(filters = 3, kernel_size=(3,3), strides=(1,1) , padding = 'SAME' , activation='relu')tf.keras.layers.Conv2D(3, 3, 1 , padding = 'SAME' , activation='relu')dtype = tf.float32로 해야 한다. int일 경우 오류가 난다.
from tensorflow.keras import datasets
(X_train, y_train),(X_test, y_test) = datasets.mnist.load_data()
image = X_train[0]
image = image[tf.newaxis, ... , tf.newaxis]
print(image.shape)
image = tf.cast(image,dtype = tf.float32)
layer = tf.keras.layers.Conv2D(3, 3, 1 , padding = 'same')
output = layer(image)
outputimage가 int일 경우 오류가 나서
image = tf.cast(image,dtype = tf.float32)
바꾸고 해야 한다.
layer weight 가져오기
weight = layer.get_weights()
weightweight = layer.get_weights()
print (weight[ 0 ].shape) #weight
print (weight[ 1 ].shape) #bias
activation
act_layer = tf.keras.layers.ReLU()
act_outpout = act_layer(output)
act_outpout
#shape가 그대로 유지되였다.
np. min (act_outpout), np. max (act_outpout)
relu는 0이하이면 0으로 된다.
pooling
이미지를 반으로 쪼개서 압축하는 것만
압축해서 강조 되게 한다.
fully connected
하나하나씩 연결한다.
flatten() -> 사이즈는 그데로 유지하면서 쭉 펼쳐진다.
y = wx+b
TensorShape(1,100)
1: 배치 사이즈
위에 까지 펼쳐졌다.
Dense()
하나씩 연결하겠다는 것이다.
units 개수를 말한다.
몇개 노드를 만들 것인가
Droupout() -> 연결을 끊게 한다.
overfitting되여서 자동으로 끊어준다.
비율을 주면서 한다.
학습이 안되는 것은 골고루 학습하게 한다.
학습 할때는 dropout로 되지만 evaluation할때는 원 상태로 한다.
학습할때만 잠간 끊어주는 것이다.
build model:
input_shape, num_classes 먼저 지정해주는 것이 좋다.
loss = 'binary_crossentropy'
loss = 'categorical_crossentropy'
tf.losses.sparse_categorical_crossentropy
tf.losses.categorical_crossentropy #one-hot encoding 줬을 때
tf.losses.binary_crossentropy
metrics
accuracy를 측정
rescaping
X_train = X_train/255 => 0~ 1사이
학습할 때 shuffle = True하는게 좋다.
아니면 overfitting 나올 가능성이 있다.
tensorflow 데이터 활용
import tensorflow as tf
train_ds = tf.data.Dataset.from_tensor_slices((X_train,y_train))
# train_ds iteration 하면 하나하나 나온다.
train_ds = train_ds.shuffle(1000) # buffer size
train_ds = train_ds.batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((X_test,y_test))
test_ds = test_ds.batch(32)train_ds.take( 2 ) => 2개 가져온다.
Cannot convert '' to EagerTensor of dtype uint8
import matplotlib.pyplot as plt
for image, label in train_ds.take(2):
plt.title(str(label[0]))
plt.imshow(image[0,:,:,0],'gray')
plt.show()
tensorflow 2.0에서는 @tf.function을 사용하면 속도가 빨라진다.
evaluation & prediction
np.argmax() => 잴 큰 값
pytorch 기초
import torch
nums = torch.arange(9)
numsnumpy() 로 변환이 가능하고
reshape도 가능하다.
view가 reshape로 변ㅎ하고 있다.
AutoGrad 기울기를 준다.
기울기를 줘서 학습한다.
requires_grad = True =>기울기 구한다.
backward() => 역전파
with torch.no_grad() => 기울기를 구하지 않는다. test할 때
torchvision 으로
tensorflow (batch_size, height, width , channel)
pytorch (batch_size , channel
torch.squeeze(image[0]) => 잴 처음에것 없에준다.
layer = nn.Conv2d(in_channels = 1, out_channels = 20, kernel_size = 5, stride = 1)
layer.weight
nn는 안에 weight가 있고
function 은 안에 weight가 없다.
nn.Linear()
pytorch parameters확인
params= list(model.parameters())
for i in range(8):
print(params[i].size )
optimizer.zero_grad() =>optimizer clear해준다.
모델 안에 데이터 여주고 예측 한다.
loss 함수
F.nll_loss()
기울기 계산
loss.backward()
optimizer update
optimizer.step()
학습 할때 train 모델로 바꿔야 한다.
model.train()
evaluation
model.eval()
test 모델일 경우에는
with torch.no_grad():
tensorflow 와 pytorch code 차이
tensorflow
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import datasets
from tensorflow.keras.layers import Input, Conv2D, Activation, MaxPooling2D,Dropout , Flatten, Dense
from tensorflow.keras import Model
from tensorflow.keras.optimizers import Adam
(X_train , y_train),(X_test, y_test ) = datasets.mnist.load_data()
X_train = X_train[..., tf.newaxis]
X_test = X_test[..., tf.newaxis]
X_train = X_train/ 255.
X_test = X_test/255.
print(X_train.shape)
input_shape = (28,28,1)
classes = 10
lr_rate = 0.001
inputs = Input(input_shape)
outputs = Conv2D(32, (3,3) , padding = 'SAME')(inputs)
outputs = Activation('relu')(outputs)
outputs = Conv2D(32, (3,3) , padding = 'SAME')(outputs)
outputs = Activation('relu')(outputs)
outputs = MaxPooling2D(pool_size =(2,2))(outputs)
outputs = Dropout(0.5)(outputs)
outputs = Conv2D(64, (3,3) , padding = 'SAME')(outputs)
outputs = Activation('relu')(outputs)
outputs = Conv2D(64, (3,3) , padding = 'SAME')(outputs)
outputs = Activation('relu')(outputs)
outputs = MaxPooling2D(pool_size =(2,2))(outputs)
outputs = Dropout(0.5)(outputs)
outputs = Flatten()(outputs)
outputs = Dense(512)(outputs)
outputs = Activation('relu')(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Dense(classes)(outputs)
outputs = Activation('softmax')(outputs)
model = Model(inputs = inputs, outputs = outputs )
model.compile(optimizer = Adam(lr_rate) , loss = 'sparse_categorical_crossentropy', metrics=['accuracy'])
epochs= 1
batch_size = 32
model.fit(X_train, y_train, batch_size = batch_size, shuffle = True, verbose = 1)
model.evaluate(X_test, y_test, batch_size = batch_size)
pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
seed = 1
lr_rate = 0.001
momentum = 0.5
batch_size = 32
test_batch_size = 32
epochs =1
log_interval = 100
no_cuda= False
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = nn.Conv2d(1,20,5,1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
output = F.relu(self.conv1(x))
output = F.max_pool2d(output,2,2)
output = F.relu(self.conv2(output))
output = F.max_pool2d(output,2,2)
output = output.view(-1, 4*4*50)
output = F.relu(self.fc1(output))
output = self.fc2(output)
return F.log_softmax(output, dim=1)
train_set = datasets.MNIST('./dataset' , train = True, download = True,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3801,))]))
test_set = datasets.MNIST('./dataset' , train = False,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3801,))]))
torch.manual_seed(seed)
use_cuda = not no_cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {"num_workers" :1, "pin_memory" : True} if use_cuda else{}
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size = batch_size, shuffle = True, **kwargs
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size = batch_size, shuffle = True, **kwargs
)
model = SimpleModel().to(device)
optimizer = optim.SGD(model.parameters(), lr = lr_rate, momentum = momentum)
for epoch in range(epochs):
model.train()
for batch_idx, (data,target) in enumerate(train_loader):
data,target = data.to(device) , target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print("train epoch: {} [{}/{} ({:.0f}%)]\Loss{:.4f}".format(epoch+1, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader) , loss.item()))
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data,target = data.to(device) , target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target , reduction = 'sum').item()
pred = output.argmax(dim = 1, keepdim = True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test epoch:average loss {:.4f} , accuracy {}/{} ({:.0f}%)\n".format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader) , loss.item()))