** 스트림 api
=>java.io 패키지에 있는 스트림은 입출력을 위한 스트림
=>java.util.stream 패키지의 스트림은 Collection 에 대한 작업을 위한 스트림 -1.8 버전에 추가
=> 기존에는 동일한 자료형의 데이터 여러 개를 다룰 때 Collection 이나 배열을 이용
Collection 이나 배열을 이용하게 되면 코드가 길어지고 재사용성이 떨어집니다.
Collection 과 배열에 있는 동일한 작업을 수행하는 메소드가 이름은 같은데 사용방법이 조금씩 다릅니다.
예를 들면 LIst 의 정렬을 위한 sort 메소드는 instance 메소드인데 배열의 정렬을 위한 메소드는 Arrays 클래스의 SORT 라는 STATIC 메소드입니다.
배열의 데이터를 하나씩 가져올 때는 [ 인덱스] 를 이용하고 list 의 데이터는 get( 인덱스) 을 이용합니다.
=> 메소드의 매개변수로 인터페이스를 이용하는 경우에 별도의 클래스를 만들거나 anonymous class 를 이용해야 해서 코드가 길어지고 메모리 낭비가 발생했는데 스트림api 에서는 매개변수에 람다식을 사용해서 코드를 간결하게 만들 수 있습니다.
=> 병렬처리도 쉽게 할 수 있음
1. 배열의 데이터 접근
CollectionUse.java
public static void main(String[] args ) {
//List 의 데이터를 사용
// 배열을 이용해서 lIST 만들기
List<String> list = Arrays.asList ( "C" , "Python" , "Java" );
// 인덱스를 이용해서 하나씩 접근 - 배열이나 List 의 데이터 개수를 알아야 합니다.
System.out .println();
System.out .println( " 데이터를 인덱스를 이용해서 하나씩 접근" );
int length = list .size();
int i = 0;
//for 보다 while 이 좋다.
//for 은 집단으로 접근하는게 좋다.
while ( i < length ) {
String temp = list .get( i );
System.out .println( temp );
i ++;
}
System.out .println();
System.out .println( " 반복자(Iterator - Enumeration : __iter__:python) 을 이용해서 하나씩 접근" );
// 반복자는 데이터 개수를 알 필요가 없습니다.
Iterator<String> iterator = list .iterator();
// 다음 데이터 존재 여부를 확인하고 다음 데이터에 접근 - 데이터베이스에서는 Cursor 라고 합니다.
// 데이터베이스나 c++ 에서는 이런 방법으로 접근을 하지만 Java 나 Python
// 간경해졌고 길이를 알 필요없다.
while ( iterator .hasNext()) {
System.out .println( iterator .next());
}
System.out .println();
System.out .println( " 빠른 열거 (for-each) 를 이용하는 방법" );
// 반복자가 구현된 객체의 경우는 빠른 열거를 사용하는 것이 가능
// 예약어만 다른것이지 접근 방법은 똑 같다.
for (String temp : list ) {
System.out .println( temp );
}
System.out .println();
System.out .println( " 스트림을 이용하는 방법" );
// 스트림 생성
Stream<String> stream = list .stream();
// 람다식을 이용해서 메소드의 내용을 매개변수로 대입 - 함수형 프로그래밍
// 스트림을 만들때 사용한 Collection 의 데이터를 name {} 안의 내용을 수행
// 반복문을 사용하지 않아도 forEach 가 알아서 순서대로 실행
//python 에서의 numpy ndarray pandas 의 Series, DataFrame 등의 동작방식에 이와 동일
stream .forEach(( name ) -> {System. out .println( name );});
}
2. 스트림의 특징
1) 스트림은 데이터 소스를 변경하지 않습니다.
원본 데이터에 변경을 가하지 않습니다.
중간 연산한 결과를 별도로 저장할 수 있습니다.
2) 스트림은 일회용
=> 한 번 읽고 나면 재사용이 안되므로 다시 만들어서 사용
3) 스트림은 작업을 내부적으로 반복해서 처리
=> 반복문이 내부에 숨어있는 것 입니다.
=> 단순하게 스트림을 사용한다고 해서 실행 속도가 빨라지는 것은 아닙니다.
4) 다양한 기본 연산 제공
=> 중간 처리 ( 매핑 - 변환, 필터링, 정렬) 연산과 최종 처리( 반복 , 카운팅, 평균, 합계) 연산을 제공
5) 스트림의 연산은 지연된 연산
=> 중간 연산이 중간에 수행되는 것이 아니고 최종 연산을 수행하기 전에 수행
6)Fork & join 을 이용해서 병렬처리를 구현하는 것보다 휠씬 쉽게 병렬 처리를 구현
3.Stream 생성
1)Collection(List, Set) 을 가지고 생성
2) 배열을 가지고 생성
Arrays.stream( 배열)
3) 디렉토리 경로를 가지고 생성
Stream<Path> Files.list(Path path): path 에 있는 모든 디렉토리 및 파일에 접근할 수 있는 스트림
4) 텍스트 파일의 내용을 줄 단위로 접근
Stream<String> BufferedReader.lines()
5) 랜덤한 스트림
Random.doubles(), ints(), longs() 를 이용
6) 배열을 이용해서 스트림을 생성하고 모든 데이터 출력
똑같은 것을 여러개 할 수있다. 요즘에는 메모리를 많이 사용하지만 속도가 빠르다.
CollectionUse.java
// 현재 디렉토리에 있는 pl.csv 파일의 내용을 읽어서 문자열 배열 만들기
try {
// 파일을 읽을 수 있는 스트림을 생성
BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream( "C:\\project\\JAVA_PROJECT\\java\\src\\java\\pl.csv" )));
// 데이터 한 줄 읽기
String line = br .readLine();
//, 단위로 분할해서 문자열 배열로 만들기
String [] ar = line .split( "," );
Stream<String> stream1 = Arrays.stream ( ar );
// 출력
stream1 .forEach(System. out ::println); //System.out::println 메소드 이름 을 할 수 있는 것
br .close();
} catch (Exception e ) {
System.out .println( " 파일 내용 읽기 실패: " + e .getMessage());
}
텍스트 파일 데이터 읽어올때 발생하는 문제
123 건
처음에 1 을 읽는다.
su : 0 su * 10 +('1' - '0') => 1
su su * 10 + ('2'-'0') =>12
계산기를 이렇게 바꾼다. 그래서 숫자를 문자로 해서 한다. 숫자 입력이 안되면 계산이 안된다.
0-> 48 이다.
// 현재 디렉토리에 있는 pl.csv 파일의 내용을 읽어서 문자열 배열 만들기
try {
// 파일을 읽을 수 있는 스트림을 생성
BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream( "C:\\project\\JAVA_PROJECT\\java\\src\\java\\pl.csv" )));
// 데이터 한 줄 읽기
String line = br .readLine();
//, 단위로 분할해서 문자열 배열로 만들기
String [] ar = line .split( "," );
Stream<String> stream1 = Arrays.stream ( ar );
// 출력
stream1 .forEach(System. out ::println ); //System.out::println 메소드 이름 을 할 수 있는 것
br .close();
//ar [3] 에는 12345 건이라는 문자열에 존재 - 12345 라는 정수로 변환
int su =0;
for ( i = 0; i < ar [3].length(); i ++) {
// 한글 자씩 가져오기
char ch = ar [3].charAt( i );
// 숫자인지 확인
if ( ch >= '0' && ch <= '9' ) {
su = su * 10 +( ch - '0' );
}else {
break ; //, 콤마 있을 때 빼기
}
}
System.out .println( su );
} catch (Exception e ) {
System.out .println( " 파일 내용 읽기 실패 : " + e .getMessage());
}
4. 스트림의 중간 연산(Reduction)
map reduce 비슷한 것이다.
=> 데이터를 변환, 필터링, 정렬, 그룹화 하는 것 등이 있습니다.
1)distinct(): 중복 제거 - 요소의 equals 메소드를 가지고 비교해서 equals 가 true
2)Filter(): 조건에 맞는 데이터만 필터링
=> 하나의 매개변수를 받아서 boolean 을 리턴하는 메소드를 대입
=> 스트림의 모든 데이터를 매개변수에 대입해서 true 리턴한 데이터만 골라서 Stream 으로 리턴
3)map() ; 데이터를 변환
=> 하나의 매개변수를 받아서 리턴을 해주는 메소드를 대입
하나받아서 바꿔야 하나깐 리턴해야 한다.
4)sorted() : 데이터를 정렬
=> 매개변수가 없으면 Comparable 인터페이스의 compareTo 메소드를 이용해서 비교한 후 오름차순 정렬행
=> 매개변수로 Comparator 인터페이스를 구현한 객체나 2 개의 매개변수를 받아서 정수를 리턴하는 람다식을 대입하면 대입된 객체나 람다식에 의해서 오름차순 정렬
앞의 데이터가 크다라고 할때는 양수를 리턴하면 되고 같으면 0 뒤의 데이터가 클 때는 음수를 리턴
5)peek(): 모든 데이터를 순회하면서 작업을 수행
=> 매개변수로 1 개의 데이터를 설정하고 return 이 없는 메소드를 대입
5. 중간 연산 실습
1) 변호, 이름 , 성별 , 나이 , 점수를 소유한 dto(Data Transfer Object -VO) 크래스르 생성
Student.java
private int num ;
private String name ;
private String gender ;
private int age ;
private int score ;
// 데이터가 없는 경웨 사용할 생성자
public Student() {
super ();
}
// 데이터가 제공되는 경웨 사용할 생성자 - 테스트 할 때 데이터를 빠르게 입력해서 확인하기 위해서 생성
public Student( int num , String name , String gender , int age , int score ) {
super ();
this . num = num ;
this . name = name ;
this . gender = gender ;
this . age = age ;
this . score = score ;
}
// 접근자 메소드
public int getNum() {
return num ;
}
public void setNum( int num ) {
this . num = num ;
}
public String getName() {
return name ;
}
public void setName(String name ) {
this . name = name ;
}
public String getGender() {
return gender ;
}
public void setGender(String gender ) {
this . gender = gender ;
}
public int getAge() {
return age ;
}
public void setAge( int age ) {
this . age = age ;
}
public int getScore() {
return score ;
}
public void setScore( int score ) {
this . score = score ;
}
// 데이터를 빠르게 확인하기 위한 메소드
@Override
public String toString() {
return "Student [num=" + num + ", name=" + name + ", gender=" + gender + ", age=" + age + ", score=" + score
+ "]" ;
}
2)main 메소드 를 소유한 main 메소드 생성
stream 사용하고있을경우오류가난다 .
ReductionMain.java
c++ 은 예약어가 거의 없다.
public static void main(String[] args ) {
// 샘플 데이터 작성
Student student1 = new Student(1, " 강좌진 " , " 남 " ,28, 98);
Student student2 = new Student(2, " 유관순 " , " 여 " ,19, 89);
Student student3 = new Student(3, " 김구 " , " 남 " ,38, 99);
Student student4 = new Student(4, " 안중근 " , " 남 " ,29, 100);
Student student5 = new Student(5, " 남자현 " , " 여 " ,25,97);
ArrayList<Student> list = new ArrayList<Student>();
list .add( student1 );
list .add( student2 );
list .add( student3 );
list .add( student4 );
list .add( student5 );
//distinct- 중복을 제거해주는 메소드
String[] ar = { " 데니스 리치히 " , " 귀도 반 로섬 " , " 제임스 고스링 " , " 데니스 리치히 " };
Stream<String> arStream =Arrays.stream ( ar );
arStream .distinct().forEach(System. out ::println);
//filter 는 원하는 데이터만 골라내는 것이다 .
//fileter - 조건에 맞는 데이터만 추출하는 중간 연산
//fileter 에는 매개변수 1 개를 갖고 boolean 을 리턴하는 람다식을 대입
Stream<Student> stream = list .stream();
//score 가 90 보다 큰 데이터만 추출해서 출력
//stream.filter((student)->{return student.getScore()>= 90;}).forEach(System.out::println );
//gender 가 여인 데이터만 추출해서 출력
stream .filter(( student )->{ return student .getGender().equals( " 여 " );}).forEach(System. out ::println);
//filter 는 한번에 한번 밖에 안된다 .
//boolean 만 리턴한면 된다 .
// 변환을 하는 것이고
//return 을 꼭 해줘야 한다 .
//map() 은 데이터를 변환할 때 사용하는 메소드
// 숫자 -> 문자열 , 문자열 -> 숫자 , 날짜 -> 문자열 , 인스턴스 -> 기본형
//Student 를 score 로 변환
System.out .println();
stream = list .stream(); // 스트림은 한 법 사용하면 소멸되기 때문에 다시 사용할 떄는 새로 생성해야 합니다 .
// 어떤 메소드를 수행만 하는 경우에는 클래스이름 :: 메소드이름만 입력해도 됩니다 .
//stream.mapToInt((student)->{return student.getScore();}).forEach(System.out::println );
// 함수형 프로그래밍
stream .mapToInt(Student::getScore).forEach(System. out ::println);
// 합계 등 구하기 편하다 . 점수만 출력 된다 .
System.out .println();
// 정렬 sorted
// 데이터 정렬은 sorted 메소들 이용
// 각 요소가 크기 비교가 가능하다면 바로 오름차순 정렬을 수행
// 요소가 크기비교가 불가능하다면 크기 비교가 가능한 메소드를 대입해야 합니다 .
// 크기비교가 가능한 데이터는 속성을 하나만 가진 데이터들입니다 .
// 기본 자료형 , 문자열 , 날짜 정도가 하나의 데이터만을 가진 자료형입니다 .
// 항상 예외가 되는 언어가 있다 . c 언어이다 .
//c 언어는 stack .linkedList 만들어서 해야 한다 . doubleLinekedList 로 3000 라인 작성하면 된다 .
arStream = Arrays.stream ( ar );
//string 은 크기 비교가 가능하기 때문에 바로 오름차순 정렬
arStream .sorted().forEach(System. out ::println);
//arStream.distinct().sorted().forEach(System.out::println );
System.out .println();
stream = list .stream();
//student 여러개의 항목을 소유하고 있기 때문에 어떤 항목으로 크기 비료를 할 지 알지 못하기 때문에 예외가 발생
//stream.sorted().forEach(System.out::println );
// 크기 비교하는 메소드를 만들어서 정렬
// 크기 비교를 할 때는 2 개의 매개변수를 가지고 정수를 리턴하는 메소드를 만들면 됩니다 .
// 양수를 리턴하면 앞에것이 크다고 간주하고 0 이면 같다고 음수이며 뒤의 데이터가 크다고 간주
// 123 < 65 로 잘못 될수 있다 .
// 점수의 오름차순
// 숫자 데이터를 이용해서 비교하는 경우 - 오름차순
//stream.sorted((a,b)->{return a.getScore()- b.getScore();}).forEach(System.out::println );
// 문자열인 경우는 compareTo 를 이용 - 앞 뒤 순서를 변경하면 내림차순
stream .sorted(( a , b )->{ return b .getName().compareTo( a .getName());}).forEach(System. out ::println);
}
3) 중간 연산 메소드는 여러 연속해서 사용 가능
6. 최종 연산 메소드
=> 마지막에 한번만 사용가능한 메소드
( 여러번 사용할 수 가 없다. 한번만 사용하는 것이다.)
1) 매칭관 관련된 메소드
=> 모두 boolean 을 리턴
allMatch()
anyMatch()
noneMatch()
=>3 가지 메소드 모두 filter 와 동일한 메소드를 매개변수로 받아서 전부 true 또는 하나 이상 true 또는 모두 false 로 리턴하는지 알려지는 메소드
2) 데이터 개수
long count()
3) 데이터 합계
int, long ,double sum()
4) 평균
OptionalDouble average()
=>Optional 은 nulll 을 저장할 수 있는 자료형을 최근에는 optional 이라고 합니다.
평균은 null 이 있을수 있다. 그래서 데이터 확인하고 해야 한다.
5) 최대값 및 최소값
OptionalXXX max()
OptionalXXX min()
6) 누적 연산
OptionalXXX reduce()
현재 파이썬에서 동작하면 오류 난다. 버전 확인해야 한다.
7) 모든 요소에게 메소드 수행
forEach()
8) 결과를 저장
R collect()
자바도 , 딥러닝 가능하는데 만들어진 것이 적어서 python 등으로 한다.
7.Optional
=> 어떤 클래스의 객체를 감싸는 클래스
=>null 이 리턴될 가능성이 있을 때 이 데이터를 바로 사용하면 예외가 발생할 가능성이 존재하기 때문에 null 여부를 확인하고 사용해야 합니다.
자바는 Optional 이라는 자료형을 이용해서 null 인 경우 다른 데이터로 치환할 수 있는 메소드를 제공합니다.
T get(): 값을 가져오고 null 이면 예외 발생
T orElse(T 기본값 ): 결과가 null 이면 기본값을 리턴
boolean isPresent(): null 이면 false 그렇지 않으면 true 리턴
=> 변형으로는 OptionInt, OptionalLong, OptionalDouble
LastMain.java
public static void main(String[] args ) {
// 문자열 배열을 이용해서 스트림을 생성
String [] ar = { "Python" , "Java" , "Closure" , "Scala" , "Kotlin" , "Swift" , "C#" , "C&C++" , "JavaScript" };
Stream<String> asStream = Arrays.stream ( ar );
//match - 판별하는 것
// 배열의 모든 데이터가 3 글자 이상인지 확인 - C# 때문에 false
//anyMatch 는 ture -any 는 하나라도 만족하면 true
//noneMathc 는 false - 하나도 만족하는게 없으면 true
boolean r = asStream .allMatch(( language )->{ return language .length() >3;});
System.out .println( r );
System.out .println();
// 집계 함수를 사용
// 글자가 5 자 이상이인 데이터의 개수를 파악
// 샘플 데이터 작성
Student student1 = new Student(1, " 강좌진 " , " 남 " ,28, 98);
Student student2 = new Student(2, " 유관순 " , " 여 " ,19, 89);
Student student3 = new Student(3, " 김구 " , " 남 " ,38, 99);
Student student4 = new Student(4, " 안중근 " , " 남 " ,29, 100);
Student student5 = new Student(5, " 남자현 " , " 여 " ,25,97);
ArrayList<Student> list = new ArrayList<Student>();
list .add( student1 );
list .add( student2 );
list .add( student3 );
list .add( student4 );
list .add( student5 );
Stream<Student> stream = list .stream();
// 점수의 합계 구하기
int tot = stream .mapToInt(Student::getScore).sum();
System.out .println( "score 합계 :" + tot );
System.out .println();
// 남자 나이 합계
stream = list .stream();
tot = stream .filter(( student )->{ return student .getGender().equals( " 남 " );}).mapToInt(Student::getAge).sum();
System.out .println( " 남자 나이 합계 : " + tot );
System.out .println();
stream = list .stream();
long cnt = stream .filter(( student )->{ return student .getGender().equals( " 여 " );}).mapToInt(Student::getAge).count();
System.out .println( " 데이터 개수 : " + cnt );
System.out .println();
//gender 가 여 인 데이터의 score 평균
//optional 은 기존 자료형의 데이터를 warping 한 자료형
stream = list .stream();
OptionalDouble avg = stream .filter(( student )->{ return student .getGender().equals( " 여 " );}).mapToInt(Student::getScore).average();
//getAsDouble 로 가져오면 결과가 null 일 때 예외가 발생
//orElse 에서 기본값을 설정하면 결과가 null 일 때 기본값을 리턴
System.out .println( " 여자 score 평균 " + avg .orElse(0));
System.out .println();
//max 나 min 은 comparator.comparing 자료형 ( 비교형 데이터의 메소드 ) 를 대입하면 Optional< 제너릭 > 으로 결과를 리턴
//Score 의 최대값
stream = list .stream();
Optional<Student> re = stream .filter(( student )->{ return student .getGender().equals( " 남 " );}).max(Comparator.comparingInt (Student::getScore));
System.out .println( "score 의 최대값 :" + re .get());
stream = list .stream();
Optional<Student> result = stream .filter(( student )->{ return student .getGender().equals( " 남 " );}).min(Comparator.comparingInt (Student::getScore));
System.out .println( " 남자의 최저 점수 :" + result .get());
}
9.collect
=>collect 를 이용해서 중간 결과를 List 나 Set 으로 리턴받고자 하면 이 때는 Collect 에 매개변수로 Collectors.toList 또는 toSet 을 대입하면 됩니다.
=> 결과를 Map 으로 저장하고자 하면 Collector.toMap( 키로 사용할 데이터를 리턴해주는 메소드, 매개변수 1 개를 가지고 리턴하는 메소드) 를 대입하면 됩니다.
앞의 메소드 결과로 key 를 만들고 뒤의 메소드 결과를 value 를 만듭니다.
=>toList() 대신에 counting() 을 설정하면 long 타입의 데이터 개수를 리턴
=>summingInt 나 summingDouble 메소드에 mapToInt 나 mapToDouble 을 대입하면 합계를 리턴
=>averagingInt 나 averagingDouble 메소드에 mapToInt 나 mapToDouble 을 대입하면 평균을 리턴
=>maxBy 나 minBy 메소드에 비교하는 메소드를 대입하면 최대값이나 최소값을 리턴
최대나 최소는 실제 값이 아니고 최대값이나 최소값을 가진 데이터를 리턴
CollectorMain.java
public static void main(String[] args ) {
// 집계 함수를 사용
// 글자가 5 자 이상이인 데이터의 개수를 파악
// 샘플 데이터 작성
Student student1 = new Student(1, " 강좌진 " , " 남 " , 28, 98);
Student student2 = new Student(2, " 유관순 " , " 여 " , 19, 89);
Student student3 = new Student(3, " 김구 " , " 남 " , 38, 99);
Student student4 = new Student(4, " 안중근 " , " 남 " , 29, 100);
Student student5 = new Student(5, " 남자현 " , " 여 " , 25, 97);
ArrayList<Student> list = new ArrayList<Student>();
list .add( student1 );
list .add( student2 );
list .add( student3 );
list .add( student4 );
list .add( student5 );
Stream<Student> stream = list .stream();
//gender 의 값이 남인 데이터만 가지고 List 를 생성
List<Student> manList = stream .filter(( student )->{ return student .getGender().equals( " 남 " );}).collect(Collectors.toList ());
for (Student temp : manList ) {
System.out .println( temp );
}
//gender 의 값이 여인 데이터를 가지고 name 을 key 로 하고 전체를 value 로 하는 mAP 을 생성
stream = list .stream();
Map<String,Student> womanMap = stream .filter(( student )->{ return student .getGender().equals( " 여 " );})
.collect(Collectors.toMap (Student::getName, (student )->{ return student ;}));
//Map 의 모든 데이터 출력
Set<String> keys = womanMap .keySet();
for (String key : keys ) {
System.out .println( key + " : " + womanMap .get( key ));
}
// 결과를 저장하는 것이 collector 이다 .
System.out .println();
stream = list .stream();
long count = stream .filter(( student ) ->{ return student .getGender().equals( " 여 " );}).collect(Collectors.counting ());
System.out .println( " 여자 인원수 :" + count );
}
10.grouping 이 가능
=>collect 메소드에 Collectors.groupingBy() 를 이용해서 그룹화가 가능
어떤 메소드의 결과로 그룹화 할 것인지를 설정하면 됩니다.
=> 두번째 매개변수로 구하고자 하는 집계함수를 설정하면 그룹화 한 후 집계도 가능
counting(),averagingDouble(),maxBy(),minBy(), summingInt(),summingLong(), summingDouble() 등으로 합계도 구할 수 있음
=> 결과는 그룹화 하는 함수의 결과를 key 로 해서 Map 으로 리턴합니다.
=> 데이터들만 규격화가 잘 되어 있다면 데이터베이스의 sql 을 사용하는 것처럼 사용이 가능
11. 그룹화 실습
GroupingMain.java
public static void main(String[] args ) {
// 집계 함수를 사용
// 글자가 5 자 이상이인 데이터의 개수를 파악
// 샘플 데이터 작성
Student student1 = new Student(1, " 강좌진 " , " 남 " , 28, 98);
Student student2 = new Student(2, " 유관순 " , " 여 " , 19, 89);
Student student3 = new Student(3, " 김구 " , " 남 " , 38, 99);
Student student4 = new Student(4, " 안중근 " , " 남 " , 29, 100);
Student student5 = new Student(5, " 남자현 " , " 여 " , 25, 97);
ArrayList<Student> list = new ArrayList<Student>();
list .add( student1 );
list .add( student2 );
list .add( student3 );
list .add( student4 );
list .add( student5 );
//List 를 Stream 으로 변환
Stream<Student> stream = list .stream();
//stream 으로 그룹화
Map<String,List<Student>> map = stream .collect(Collectors.groupingBy (Student::getGender));
Set<String> keys = map .keySet();
for (String key : keys ) {
System.out .println( key + ":" + map .get( key ));
}
System.out .println();
// 스르팀은 한번 소모하면 소멸됩니다 .
// 새로운 작업을 수행할 때 만다 스트림은 다시 생성
stream = list .stream();
//gender 별로 그룹화 한 후 score의 평균 구하기
Map<String,Double> result = stream .collect(Collectors.groupingBy (Student::getGender,Collectors.averagingDouble (Student::getScore)));
keys = result .keySet();
for (String key : keys ) {
System.out .println( key + ":" + result .get( key ));
}
System.out .println();
stream = list .stream();
// 그룹화는 존재하는 메소드를 이용해도 되지만 람다로 직접 만들어도 됩니다 .
// 하나의 매개벼수 ( 스트림의 제너리 ) 를 받아서 데이터를 리턴하는 람다 식이면 됩니다 .
Map<String,Integer> result1 =
stream .collect(Collectors.groupingBy (( student ) ->{ return student .getName();},
Collectors.summingInt (Student::getScore)));
keys = result1 .keySet();
for (String key : keys ) {
System.out .println( key + ":" + result1 .get( key ));
}
System.out .println();
// 성별 최대인 데이터를 추출
stream = list .stream();
Map<String,Optional<Student>> result2 =
stream .collect(Collectors.groupingBy (Student::getGender,
Collectors.maxBy (Comparator.comparingInt (Student::getScore))));
keys = result2 .keySet();
//Optional 은 출력할 때 Optional 과 함께 출력하기 때문에 이를 벗겨내기 위해서는 get() 이나 orElse() 를 이용
for (String key : keys ) {
System.out .println( key + ":" + result2 .get( key ).get());
}
}
12. 병렬 스트림
=>java 1.8 이전 까지는 데이터의 모임에 병렬처리를 할려면 fork&join API 를 사용
이 API 사용이 어려움
=>Stream api 에서는 병렬 스트림을 만들기만 하면 자동으로 병렬 처리를 수행
스트림을 만들 때 stream() 메소드 대신에 parallelStream() 메소드를 호출하면 병렬 스트림이 됩니다 .
Stream API 는 데이터 병렬성으로 구현
데이터들을 작은 데이터로 분할해서 작업하는 형태
=> 작업의 병렬성
여러 작업의 요청이 올 때 작업들을 개별 스레드로 만들어서 병렬 처리하는 방식으로 웹 서버가 대표적인 작업의 병렬성을 구현한 예 :
ParallelMain.java
// 문자열을 매개변수로 받아서 2 초 후에 출력하는 메소드
public static void work(String str ) {
try {
Thread.sleep (2000);
System.out .println( str );
} catch (InterruptedException e ) {
// TODO Auto-generated catch block
e .printStackTrace();
}
}
public static void main(String[] args ) {
String[] ar = { " 일 " , " 이 " , " 삼 " , " 사 " , " 오 " };
List<String> list = Arrays.asList ( ar );
Stream<String> arStream = list .stream();
// 일반 스트림을 생성해서 ar 에 work 를 수행 - 10 초 정도 소요
long start = System.currentTimeMillis ();
arStream .forEach(( data ) -> {
work (data );
});
long end = System.currentTimeMillis ();
System.out .println( " 순차 처리 :" + ( end - start ));
// 병렬 스트림을 생성해서 work 를 수행 -cpu 코더 개수에 따라 걸리는 시간이 다름
//5 개 이상이여서 5 개가 한번에 돈다 .
// 코어가 5 개 이상이면 한 번에 수행하므로 2 초 ㅅ = 정도 소모
// 데이터 의 모임을 가지고 작업을 수행하는 경우 다른 영향을 전혀 받지 않고 수행되는 경우에는 병렬처리르 하는 것이 시간으로 이득
// 앞의 데이터의 연산결과를 가지고 다음 작업을 수행하는 작업은 병렬처리를 하는 것이 곤란
// 필터링 같은 경우는 병렬처리를 수행하기 좋은 작업 - 이러한 처리 방식을 Map - Reduce 라고 합니다 .
// 각각의 데이터에서 작업을 처리한 후 그 결과를 모아서 리턴
Stream<String> paralleStream = list .parallelStream();
// 일반 스트림을 생성해서 ar 에 work 를 수행 - 10 초 정도 소요
start = System.currentTimeMillis ();
paralleStream .forEach(( data ) -> {
work (data );
});
end = System.currentTimeMillis ();
System.out .println ( " 순차 처리 :" + ( end - start ));
}
** 최근 언어의 자료형 구분
예전에는 value 형과 reference 형으로 구분( 이것이 c 언어일 경우)
수정 가능 여부에 따른 구분(mutable 과 immutable)
scala 와 vector 구분( 데이터 개수를 구분)
null 저장 가능 여부(Optional 과 nonOptional) (null 을 저장할 수 있는 가 없는것인가)
객체지향언어에서 python 에서 등에서는
a.b() -> 이것하지 말라고 한다. . 점이 있음녀 참조형이라고 한다. 데이터의 참조를 하고 있다가 찾아간다.
a 가 null 이고 None nil => NullPointerException
그래서 참조형으로 할때 이렇게 쓰지 말라고 한다.
java 에서는
if( a ! = null){ //null 인지 확인한다.
a.b();
}
참조형은 항상 null 인지 물어봐야 한다.
optional : null 저장 가능
NonOptional :null 저장 못함
var a = new A();->NonOptional 일경우 null 체크 할 필요없다.
나누기 일 경우 문제가 생긴다. infinite 등 문제 가 생긴다.
legacy - 전통적인 , 예전에 방식
변수를 선언할 때 뒤에 ! 를 붙이면 null 저장가능
String temp; // 에러 ! 표가 없기 때문에 그래서 값을 줘야 한다. => String temp ="Hello";// 초기관을 설정하지 않으면 에러
String n! ;// 초기값을 설정하지 않으면 null - 이 데이터는 사용할 때 null 여부를 확인해야 합니다.
UML
시스템에 대한 지식을 찾고 표현하기 위한 언어
시스템을 개발하기 위한 탐구 도구
비주얼 모델링 도구
근거가 잘 정리된 가이드 라인
분석, 설계 작업의 마일스톤
실용적 표준
비주얼 프로그래밍 언어나 데이터베이스 표현도구 아님
개발 프로세스나 품질 보증 방안이 아님
가이드 라인이 있어서 작업할 때 편해진다.
base drived
파생 클래스
static 은 밑줄을 건다. eclipse 는 기울러져 있다.
보통 자료형을 쓰고 이름을 쓰는데
uml 에서는 반대이다.
class A{
String B ;//외부에서 받아서 사용했다.
}
List<String> ->string 의 집한으로 이것이 aggregation 이다.
Frame = new Frame():
Panel = new Panel();
Button = new Button();
button 은 단독으로 만들 수 없다. buttond 는 panel 이나 frame 으로 해야 한다.
panel 도 frame 없으면 안된다.
frame 아니면 보여질 수 없다.
Layout : container
widget 단독으로 사용불가
class 의 상속 , interface 는 .. 이다.
RectangularShape 에 shape 라는 interface 를 구현 한 것이다.
student 는 studentiD CARD 를 한계 가지고 있다.
대각선 적으로 바라봐야 한다.
분석 -> UML ->-> 구현
UML 은 안하고 클래스 그냥 한다.
나중에는
분석 -> -> 구현
설계 정보가 없다. 유지보수 할 경우 코드를 봐야 한다.
최근에는 역공학을 많이 사용한다. 나중에 하는 것이다.
eclipse 에서 python 이 가능하다.
eclipse 와 vs code 조금 다르다.
vs code 는 editor
eclipse 는 id 로
python 설치하고 설정해야 한다.
설치 다되면 ECLIPSE RESTART 해야 된다.
그림파일이 만들어 질려면 체크해야 한다.
소스 코드 내부는 잘 안보고
상속이나 디자인 패턴이 잘 되여있는 지만 확인한다.
** 디자인 패턴
Design Pattern
=> 인스턴스의 사용용도에 따라 클래스의 모양을 만드는 것
GoF 디자인 패턴
runtime class 의 생성자가 없다가 아니고 생성자가 안보인다. private 로 만들어서 안보인다.
실글 패턴
보는 순간 실글 톤이고 인스턴스를 하나밖에 안된다.
날자를 설정할 경우 두개가 동시에 진행하면 안되서 하나가지고 순차적으로 해야 한다
entry point 는 하나인게 좋다 그래야 제어가 쉽다.
1. 생성에 관련된 패턴
1)Singelton Pattern
=> 인스턴스를 1 개만 생성해서 사용하는 패턴
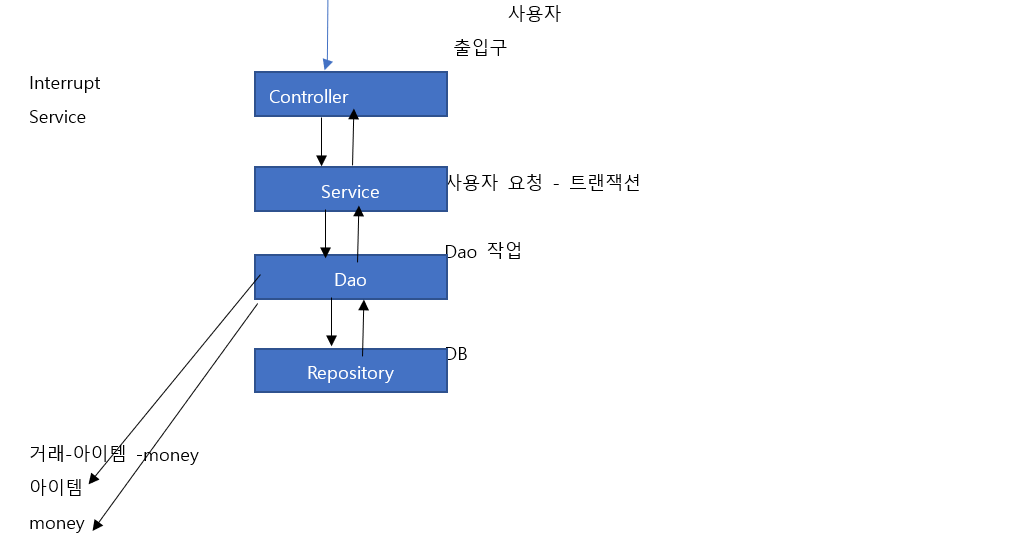
=> 관리자 클래스(Controller) 나 공유 데이터를 소유한 클래스 또는 서버에서 클라이언트의 요청을 처리하는 클래스 등에 적용
=>Java Server 를 만들기 위한 Framework 인 Spring 은 기본적으로 클래스를 디자인해서 인스턴스를 만들면 Singelton Patternd 으로 사용
python 바이블인가 ? 이런것 봐야 한다.
jump to python
main 이 static 으로 반든것이다 아무데에서도 부른 것이다.
메소드는 아무데에서나 부를 목적이고
변수는 하나만 만들어서 공유할 목적이다.





















































{kind=link}