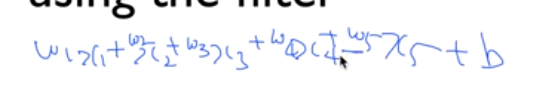728x90
반응형
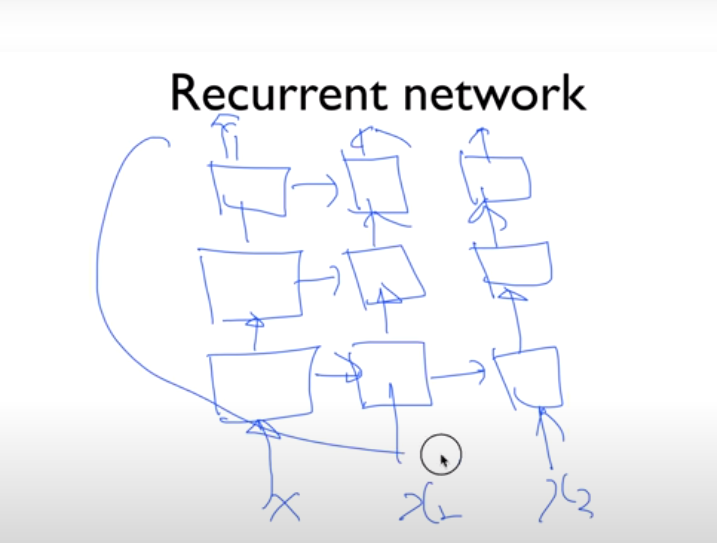
NN의 꽃 RNN 이야기
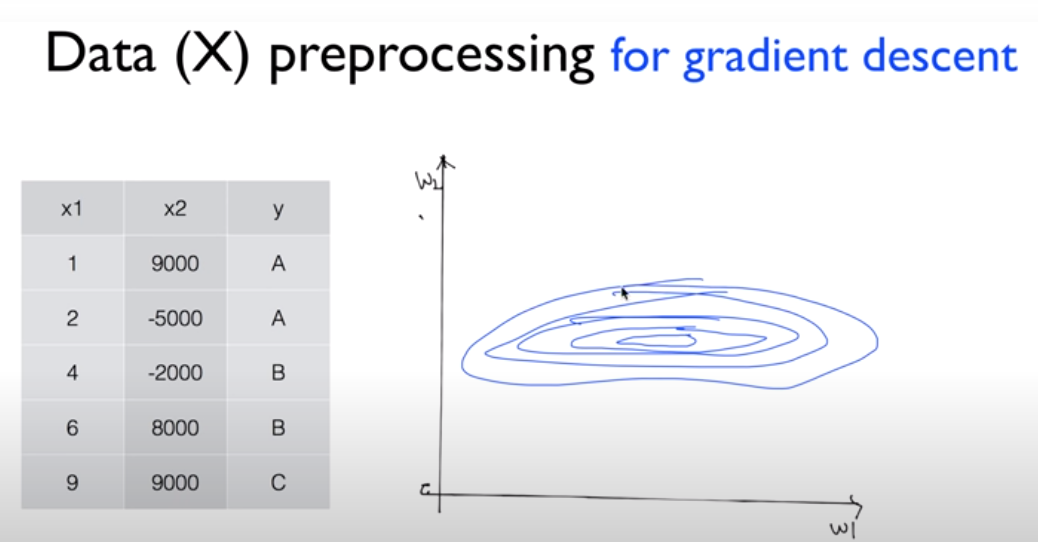
sequence data
nlp
음성
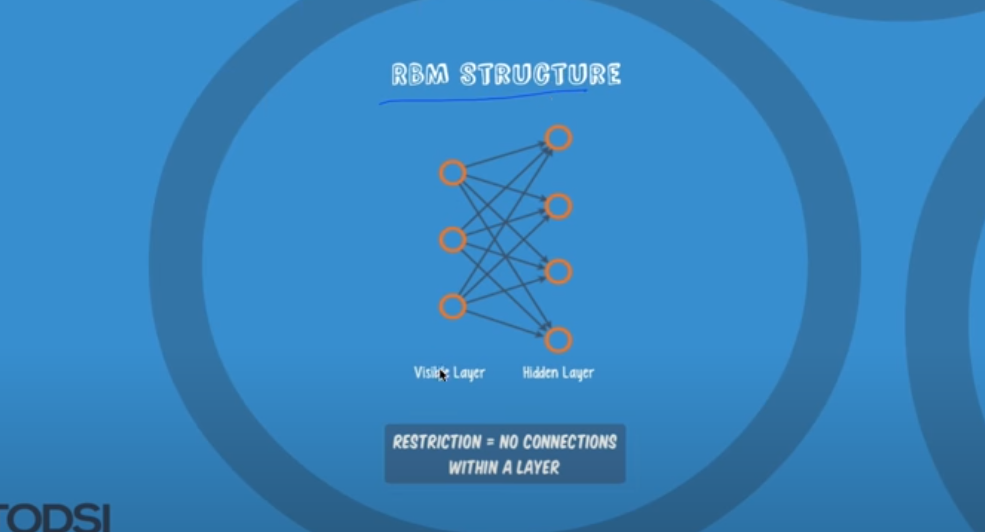
이전의 것이 현재에 영향을 미친다.
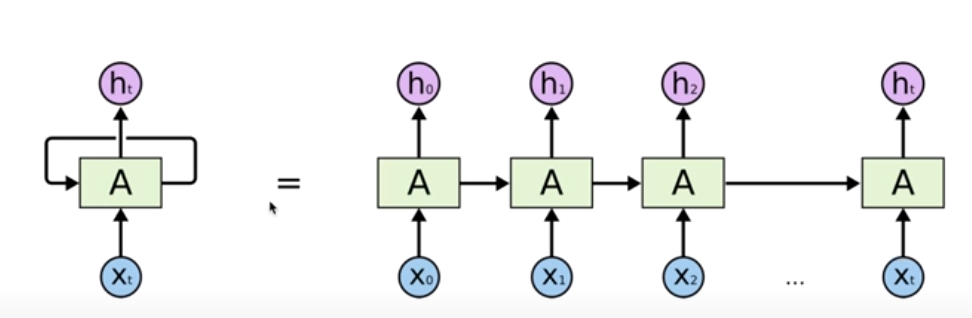

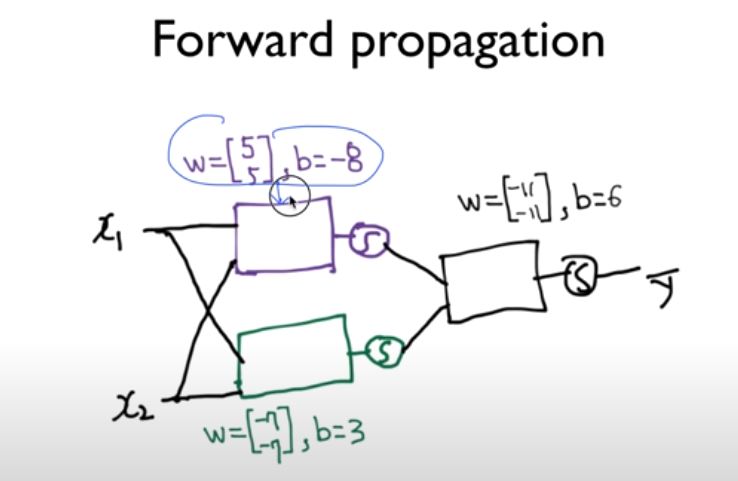
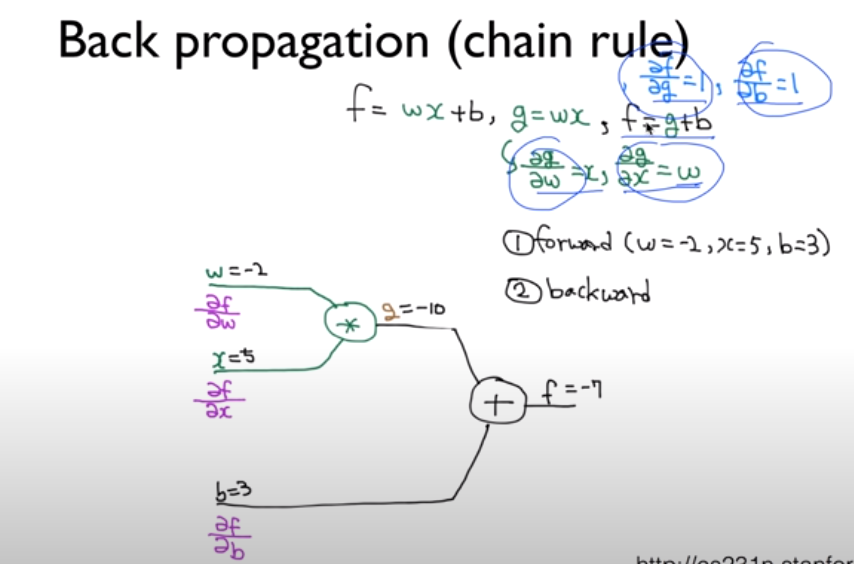
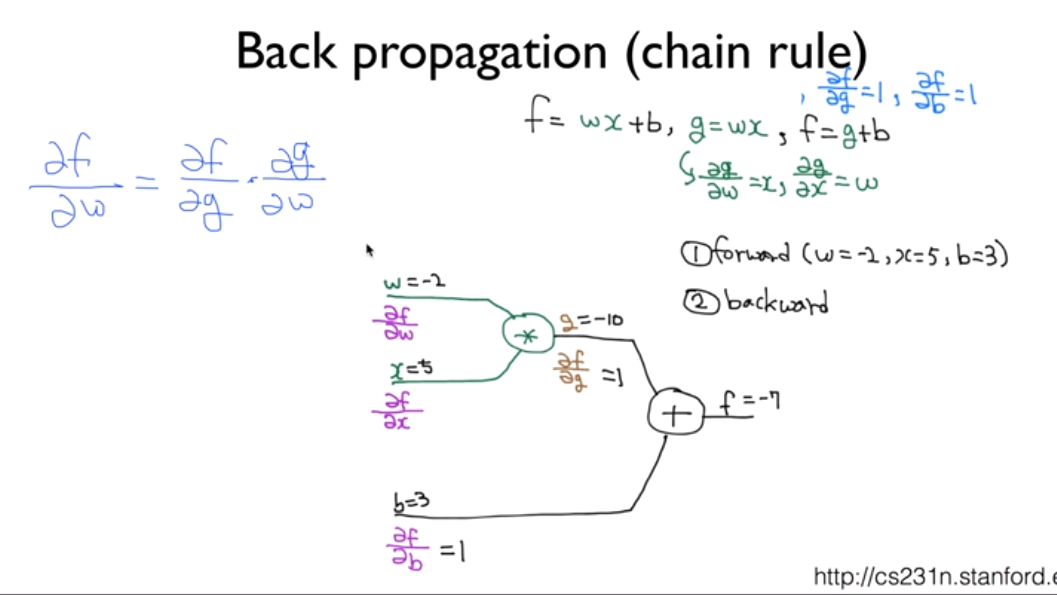
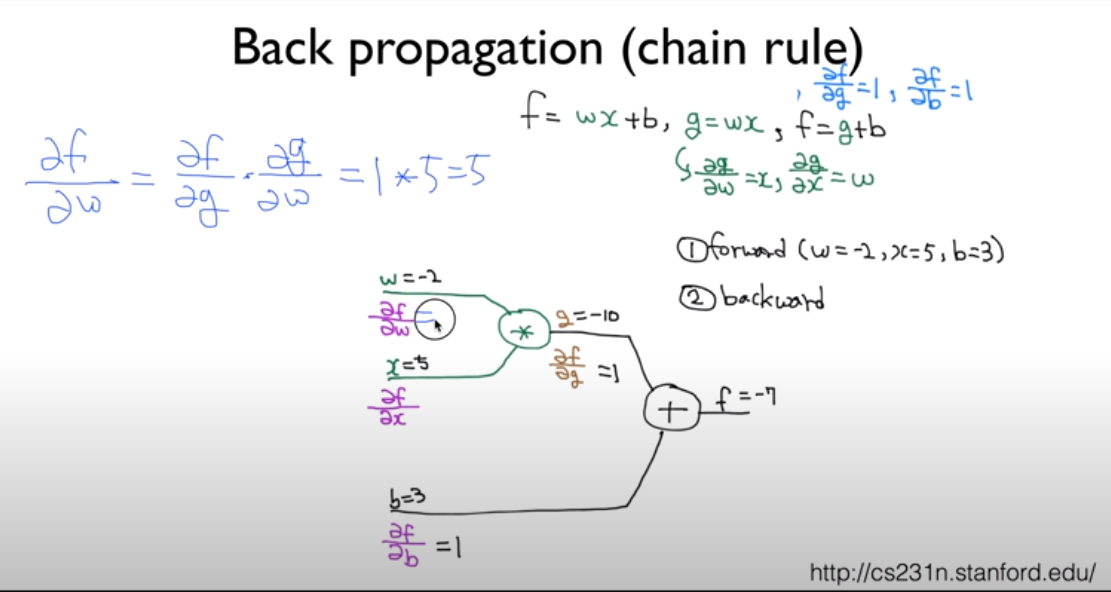
함수를 가지고 계산한다.

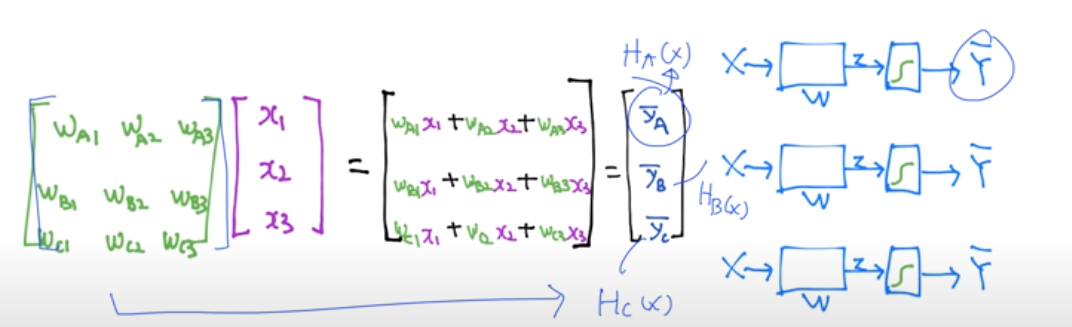
각각의 weight를 더한다.
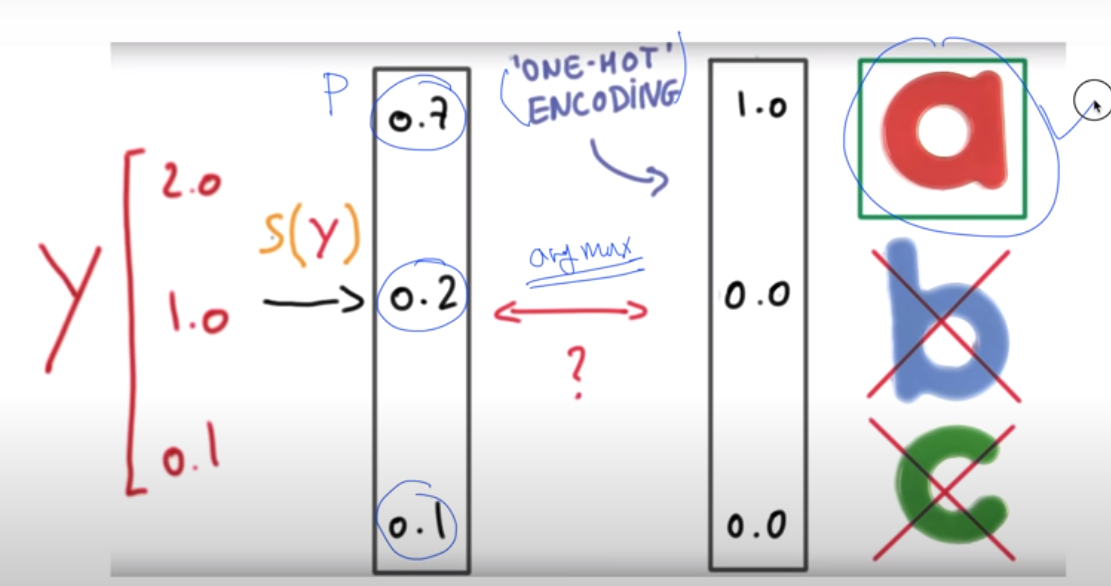
one-hot encoding
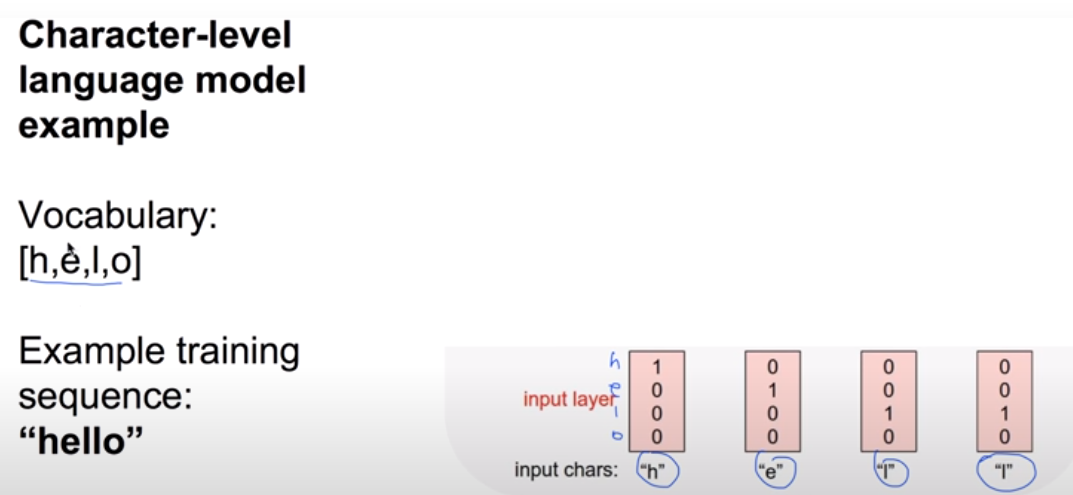

마지막 비디오 같은 경우
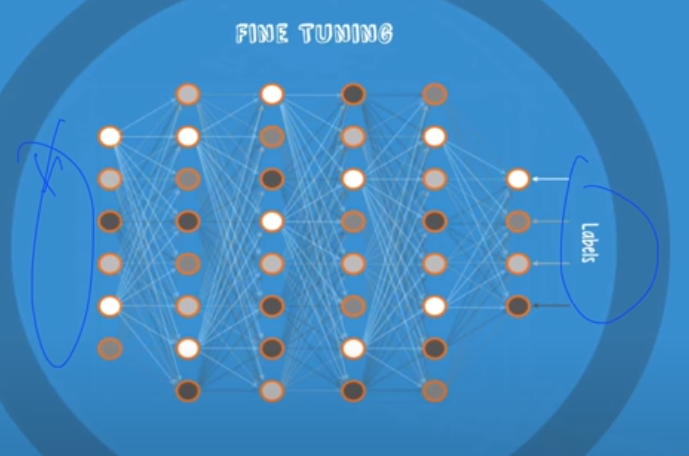
layer를 여러개 쓸 수 있다.
복잡한 학습이 가능하다.
반응형
'Machine Learning > 머신러닝과 딥러닝 BASIC' 카테고리의 다른 글
| Convolutional Neural Networks (0) | 2021.07.06 |
|---|---|
| Neural Network 2: ReLU and 초기값 정하기 (2006/2007 breakthrough) (0) | 2021.07.06 |
| Neural Network 1: XOR 문제와 학습방법, Backpropagation (0) | 2021.07.04 |
| Neural Network 1: XOR 문제와 학습방법, Backpropagation (0) | 2021.07.04 |
| 딥러닝의 기본 개념과, 문제, 그리고 해결 (0) | 2021.07.04 |