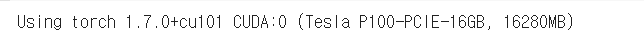import tensorflow as tf
from tensorflow.keras.utils import to_categorical
import numpy as np
from tensorflow.keras.layers import Conv2D,Dense,Flatten,Input,AveragePooling2D
from tensorflow.keras import Model
import numpy as np
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# check device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
with open("/content/yolov5/dataset/val.txt", "w") as f:
f.write('\n'.join(train_img_list) + '\n')
with open("/content/yolov5/dataset/train.txt", "w") as f:
f.write('\n'.join(val_img_list) + '\n')
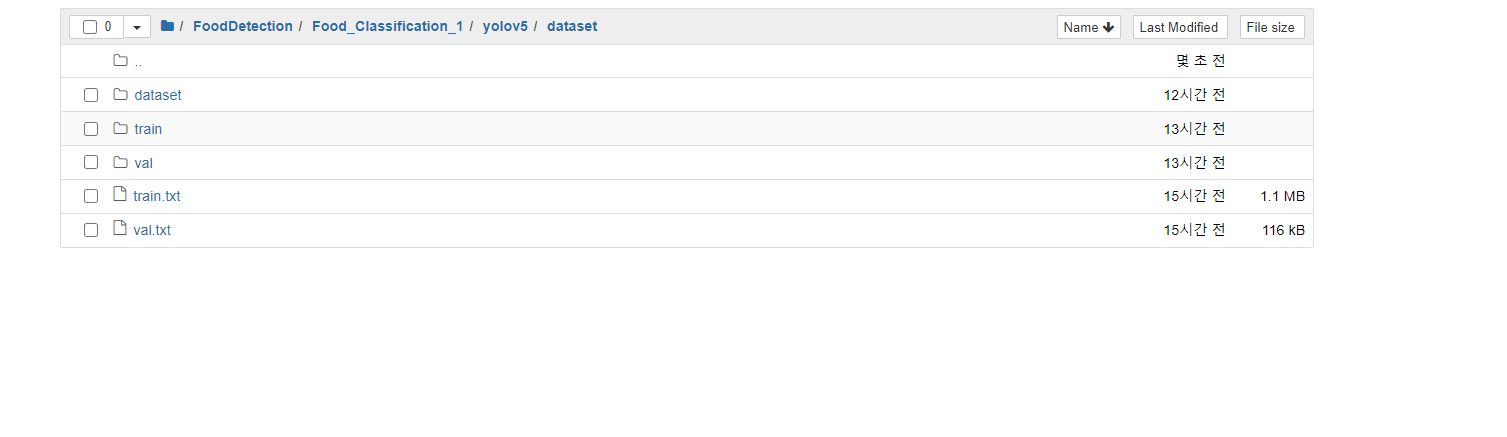
내용을 보면
이런식으로 하위에 생긴다.
이미지 들이 한줄 씩 저장되여 있다.
나눈후 위에 있었든 yaml 파일을 수정
import yaml
with open('/content/yolov5/data.yaml','r') as f:
data = yaml.load(f)
print(data)
json 불러오는 것과 동일하다.
data['train'] = '/content/yolov5/dataset/train.txt'
data['val'] = '/content/yolov5/dataset/val.txt'
with open('/content/dataset/data.yaml' ,'w') as f:
yaml.dump(data, f)
print(data)
format에 따라 바운딩 박스는 (x, y, w, h), x, y, x+w, y+h), (x_center, y_center, w, h) 등으로 표현됩니다. YOLO v5에서는 (x_center, y_center, w, h)의 형식을 따릅니다.
yolov5를 학습할 경우에는 정규화를 해야 한다. 0~1 사이로
def convert(size, box): # (XM, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin, xmin
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
x = (box[0] + box[1])/2.0 # The x coordinate of the center point of the object in the graph
y = (box[2] + box[3])/2.0 # The y coordinate of the center point of an object in a graph
w = box[1] - box[0] # Actual pixel width of object
h = box[3] - box[2] # Actual pixel height of object
x = x*dw # The coordinate ratio of the center point x of the object (equivalent to x / original image w)
w = w*dw # Width ratio of object width (equivalent to w / original image w)
y = y*dh # The coordinate ratio of the center point y of the object (equivalent to Y / original image h)
h = h*dh # Width ratio of object width (equivalent to h / original image h)
return (x, y, w, h) # Returns the x-coordinate ratio, y-coordinate ratio, width ratio, height ratio of the center point of the object relative to the original image, and the value range [0-1]
# Year = 2012 ', the id (file name) of the corresponding image
def convert_annotation(image_id):
'''
The xml File to label Documents, xml The file contains the corresponding bunding Box and picture length, size and other information,
Through the analysis, and then normalization, finally read label In the document, that is to say
One image file corresponds to one xml Then, through parsing and normalization, the corresponding information can be saved to a unique one label In the file
labal Format in file: calss x y w h At the same time, there are multiple categories corresponding to an image, so the correspondingbundingThere are also multiple messages
'''
# Find the corresponding folder through year and open the corresponding image_id, which corresponds to the bund file
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
# Prepare the corresponding image_ Write the corresponding label s in ID, which are
# <object-class> <x> <y> <width> <height>
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# Parsing xml file
tree = ET.parse(in_file)
# Get the corresponding key value pair
root = tree.getroot()
# Get the size of the picture
size = root.find('size')
# Get wide
w = int(size.find('width').text)
# Get high
h = int(size.find('height').text)
# Traverse obj
for obj in root.iter('object'):
# Get difficult??
difficult = obj.find('difficult').text
# Get category = string type
cls = obj.find('name').text
# If the category does not correspond to our scheduled class file, or difficult==1, skip
if cls not in classes or int(difficult) == 1:
continue
# id found by category name
cls_id = classes.index(cls)
# Find the bndbox object
xmlbox = obj.find('bndbox')
# Get the corresponding array of bndbox = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# Bring in for normalization operation
# w = width, h = height, B = array of bndbox = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb corresponds to normalized (x,y,w,h)
# Generate calss x y w h in the label file
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
- xmin: x-coordinate of the bottom left part of the image
- xmax: x-coordinate of the top right part of the image
- ymin: y-coordinate of the bottom left part of the image
- ymax: y-coordinate of the top right part of the image