**cartogram
=>데이터의 크기 등을 나타내기 위해서 지도의 면적을 왜곡해서 표현하는 그림
=>만드는 방식은 엑셀 등을 이용해서 지도를 그려내는 방식이 있고 일러스트레이터나 web의 svg(xml)를 이용해서 그린 후 svg를 추출하는 방법
**인구 소멸 지역을 나타내는 cartogram과 colorpleth( 단계구분도)
1.국가 통계 포털에서 인구정보를 다운로드
population_raw_data.xlsx
2.필요한 라이브러리를 import하고 그래프에서 한글을 사용하기 위한 설정을 하고 음수 표현을 위한 설정
#배열 자료구조(행렬 포함), 선형대구 ,과학 기술 계산을 위한 패키지
import numpy as np
#Series, DataFrame(자교구조), 기술 통계, 간단한 시각화를 위한 패키지
import pandas as pd
#시각화 기본 패키지
import matplotlib.pyplot as plt
#그래프에서 한글 처리를 위한 패키지
import platform
from matplotlib import font_manager, rc
#데이터 셋과 화려한 시각화를 위한 패키지
import seaborn as sns
#데이터 전처리를 위한 패키지
#sklearn 은 데이터셋과 전처리 그리고 머신러닝을 위한 패키지
from sklearn import preprocessing
#지도 시각화(단계 구분도 )를 위한 패키지
import folium
#그래프에서 한글 처리를 위한 설정
if platform.system() =='Windows':
font_name = font_manager.FontProperties(fname = 'c:/windows/fonts/malgun.ttf').get_name()
rc('font',family = font_name)
elif platform.system() == 'Darwin':
rc('font', family = 'AppleGothic')
#음수 하용을 위한 설정
#마이나스를 unicode로 하지 말라는 것이다.
plt.rcParams['axes.unicode_minus'] = False
3. 엑셀 파일의 내용을 읽기
엑셀 파일 읽을 경우 셀 병합이 있는지
#3. 엑셀 파일의 내용을 읽기
population = pd.read_excel('./Desktop/data/population_raw_data.xlsx', header = 1)
print(population.head())
population.info()
4.결측치(NA, None, NULL, np.NaN)처리
=>컬럼 자체를 제거 , NA인 행만 제거 ,다른 값으로 치환(이전값, 이후값, 중간값, 평균 ,최빈값, 머신러닝의 결과 ~ 가장 정확할 가능성이 높지만 시간이 오래 걸림)
#이 엑셀 파일에서는 위와 항목이름이 같은 경우가 Na
#d이전 값으로 NA를 채우기
population.fillna(method='ffill',inplace = True)
print(population.head())
population.info()
5.컬럼이름 변경
=>데이터를 직접 다운로드를 받으면 컬럼이름이 사용하기 어려운 경우가 많습니다.
성별은 보통 -> sex, gender
통계청에는 rc-1 , rc-2(직업)
자료랑 같이 보면서 해야 한다.컬럼이름을 확인해서 바꾸는 작업을 해야 한다.
통계 spss 등을 많이 사용한다. 한글 인식 잘 안되고 컬럼이름을 잘 확인하고 알기 쉬운 것으로 바꾸기
6.시도가 소계인 데이터를 제외하고 가져오기
#시도가 소계인 데이터를 제외
#제외를 할 때는 drop을 이용해서 삭제를 할 수 도 있고
#필터링을 할 수 도 있습니다.
# population['시도'] == '소계' 소계인것 찾아보기
# population['시도'] != '소계' 소계가 아닌 것 행을 삭제
population = population[(population['시도'] != '소계')]
print(population.head()) #소계가 없어진다.
7.항목컬럼을 구분으로 변경
#항목 컬럼을 구분으로 변경
population.rename(columns = {'항목':'구분'},inplace = True)
#셀의 값 변경
#구분이 총인구수(명) -> 합계
#구분이 남자인구수(명) -> 남자
#구분이 여자인구수(명) ->여자
population.loc[population['구분'] == '총인구수 (명)','구분' ] ='합계'
population.loc[population['구분'] =='남자인구수 (명)','구분'] ='남자'
population.loc[population['구분'] =='여자인구수 (명)','구분'] ='여자'
print(population['구분'].head())
7.청년과 노년을 분리하기 위해서 20- 39 까지의 합계와 65-100+까지의 합계를 새로운 컬럼으로 추가
#청년과 노년 층으로 새로운 컬럼을 추가
population['청년'] = population['20 - 24세'] +population['25 - 29세']+population['30 - 34세'] +population['35 - 39세']
population['노년'] = population['65 - 69세']+population['70 - 74세']+population['75 - 79세'] + population['80 - 84세'] +population['80 - 84세'] +population['80 - 84세'] +population['85 - 89세']+population['90 - 94세'] +population['95 - 99세']
print(population['청년'].head())
print(population['노년'].head())
8.피봇 테이블(행과 열을 설정해서 데이터의 기술 통계값을 확인) 생성
#8.피봇 테이블(행과 열을 설정해서 데이터의 기술 통계값을 확인) 생성
#광역시도와 시도별 그리고 구분 별로 청년과 노년의 값 확인
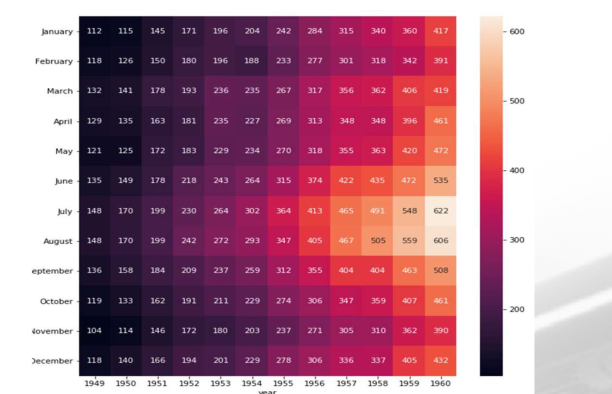
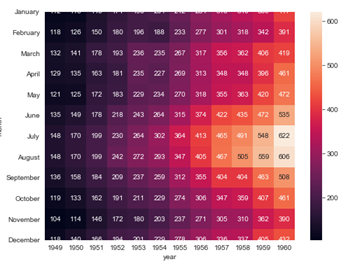
pop = pd.pivot_table(population, index = ['광역시도','시도'], columns ='구분', values=['인구수','청년','노년'])
print(pop.head())
9. 소별비율 컬럼을 생성해서 추가 - 청년층 여자 / 노년층 합계/ 2
#9. 소별비율 컬럼을 생성해서 추가 - 청년층 여자 / 노년층 합계/ 2
pop['소멸비율'] = pop['청년','여자'] /pop['노년','합계'] / 2
print(pop['소멸비율'].head())
10.소멸위기지역이라는 컬럼을 추가 - 소멸비율이 1.0 미만이면 True아니면 False
#소멸위기 지역이라는 컬럼을 추가 - 소멸비율 < 1.0 여부
pop['소멸위기지역'] = pop['소멸비율'] < 1.0
print(pop['소멸위기지역'])
print(pop[pop['소멸위기지역']==False].index.get_level_values(1))
계산식을 바뀌서 할 수 도 있다. ==============>
pop['소멸비율'] = pop['청년','여자'] / (pop['노년','합계'] / 2)
print(pop['소멸비율'].head())
#소멸위기 지역이라는 컬럼을 추가 - 소멸비율 < 1.0 여부
pop['소멸위기지역'] = pop['소멸비율'] < 1.0
print(pop['소멸위기지역'])
print(pop[pop['소멸위기지역']==False].index.get_level_values(1))
==================================
10 . 인덱스로 설정되어 있는 광역시도와 시도를 일반 컬럼으로 전환
=>인덱스를 컬럼으로 만들고자 할 때는 인덱스를 제거하면 됩니다.
#인덱스 제거
pop.reset_index(inplace = True)
print(pop.head())
11.2단으로 구성된 컬럼이름을 하나의 컬럼이름 만들기
광역시도와 시도를 합쳐서 하나의 컬럼 만들기
#컬럼이름 만들기 - 컬럼이름이 2래벨로 되여 있어서 위 아래 레벨을 합치느느 작업
#0번 레벨하고 1번 레벨의 데이터를 합치기
tmp_columns = [pop.columns.get_level_values(0)[n] +
pop.columns.get_level_values(1)[n]
for n in range(0, len(pop.columns.get_level_values(0)))]
print(tmp_columns)
pop.columns = tmp_columns
print(pop.head())

12. 시도이름 만들기
=>광역시는 구별로 분류가 도어 있는데 광역시가 아닌데 구를 가진 곳은 분류가 안되어 있음
=> 이 작업은 행정구역을 알아야 함
#광역시가 아닌 곳 중에서 구를 가지고 있는 곳의 딕셔너리 만들기
si_name = [None] * len(pop)
tmp_gu_dict = {'수원':['장안구', '권선구', '팔달구', '영통구'],
'성남':['수정구', '중원구', '분당구'],
'안양':['만안구', '동안구'],
'안산':['상록구', '단원구'],
'고양':['덕양구', '일산동구', '일산서구'],
'용인':['처인구', '기흥구', '수지구'],
'청주':['상당구', '서원구', '흥덕구', '청원구'],
'천안':['동남구', '서북구'],
'전주':['완산구', '덕진구'],
'포항':['남구', '북구'],
'창원':['의창구', '성산구', '진해구', '마산합포구', '마산회원구'],
'부천':['오정구', '원미구', '소사구']}
#고성에 대한 처리
for n in pop.index:
#광역시나 특별시 또는 자치시로 끝나지 않는
if pop['광역시도'][n][-3:] not in ['광역시','특별시','자치시']:
if pop['시도'][n][:-1] == '고성' and pop['광역시도'][n] =='강원도':
si_name[n] ='고성(강원)'
elif pop['시도'][n][:-1] == '고성' and pop['광역시도'][n] =='강원도':
si_name[n] ='고성(경남)'
else:
si_name[n] = pop['시도'][n][:-1]
#왕역시나 특셜시 차지시가 아닌데 구를 가지고 있는 것 처리
for keys, values in tmp_gu_dict.items():
if pop['시도'][n] in values:
if len(pop['시도'][n]) == 2:
si_name[n] = keys + ' '+ pop['시도'][n]
elif pop['시도'][n] in ['마산함포구','마산회원구'] :
si_name[n] = keys + ' ' + pop['시도'][n][2:-1] #앞에 두글자 빼기
else:
si_name[n] = keys + ' ' + pop['시도'][n][:-1]
elif pop['광역시도'][n] == '세종특별자치시':
si_name[n] = '세종'
else:
if len(pop['시도'][n]) == 2 :
si_name[n] = pop['광역시도'][n][:2] + '' + pop['시도'][n]
else:
si_name[n] = pop['광역시도'][n][:2] + '' +pop['시도'][n][:-1]
print(si_name)
13.도시 이름을 pop에 새로운 컬럼으로 추가
pop['ID'] = si_name
#시도 이름을 pop에 새로운 컬럼으로 추가
pop['ID'] = si_name
print(pop['ID'])
#현재 상태 확인
print(pop.head())
print(pop.info())
14. 지도 정보를 저장한 엑셀 파일 읽기
#지도 정보를 가진 Excel 파일 읽기
draw_korea_draw = pd.read_excel('./Desktop/data/draw_korea_raw.xlsx')
print(draw_korea_draw)
15. 각 셀의 위치를 좌표로 만들기
#컬럼이름이 일련번호로 되어 있습니다.
#STACK함수를 일용해서 컬럼이름을 인덱스로 만들기
draw_korea_raw_stacked = pd.DataFrame(draw_korea_draw.stack())
print(draw_korea_raw_stacked)
#좌표로 사용하기 위해서 커럶 이름 변경
draw_korea_raw_stacked.rename(columns = {'level_0' :'y','level_1':'x',0:'ID'},inplace = True)
print(draw_korea_raw_stacked)
16. 지도 그리기
1)경계선 만들기 위한 좌표 생성
#경계선 생성을 위한 조료 그리기
BORDER_LINES = [
[(5, 1), (5,2), (7,2), (7,3), (11,3), (11,0)], # 인천
[(5,4), (5,5), (2,5), (2,7), (4,7), (4,9), (7,9),
(7,7), (9,7), (9,5), (10,5), (10,4), (5,4)], # 서울
[(1,7), (1,8), (3,8), (3,10), (10,10), (10,7),
(12,7), (12,6), (11,6), (11,5), (12, 5), (12,4),
(11,4), (11,3)], # 경기도
[(8,10), (8,11), (6,11), (6,12)], # 강원도
[(12,5), (13,5), (13,4), (14,4), (14,5), (15,5),
(15,4), (16,4), (16,2)], # 충청북도
[(16,4), (17,4), (17,5), (16,5), (16,6), (19,6),
(19,5), (20,5), (20,4), (21,4), (21,3), (19,3), (19,1)], # 전라북도
[(13,5), (13,6), (16,6)], # 대전시
[(13,5), (14,5)], #세종시
[(21,2), (21,3), (22,3), (22,4), (24,4), (24,2), (21,2)], #광주
[(20,5), (21,5), (21,6), (23,6)], #전라남도
[(10,8), (12,8), (12,9), (14,9), (14,8), (16,8), (16,6)], #충청북도
[(14,9), (14,11), (14,12), (13,12), (13,13)], #경상북도
[(15,8), (17,8), (17,10), (16,10), (16,11), (14,11)], #대구
[(17,9), (18,9), (18,8), (19,8), (19,9), (20,9), (20,10), (21,10)], #부산
[(16,11), (16,13)], #울산
# [(9,14), (9,15)],
[(27,5), (27,6), (25,6)],
]
2)지도 그리기
plt.figure(figsize = (8,12))
#지역이름 표시
#행단위로 읽어오기
for idx, row in draw_korea_raw_stacked.iterrows():
#공백을 기준으로 2개로 나누어 진다면 줄바꿈을 해서 출력
if len(row['ID'].split()) == 2:
dispname = '{}\n{}'.format(row['ID'].split()[0],row['ID'].split()[1])
#마지막 2글자가 고성이라면 고성이라고 출력
elif row['ID'][:2] =='고성':
dispname ='고성'
else:
dispname = row['ID']
#3글자가 넘으면 폰트를 줄여서 출력
if len(dispname.splitlines()[-1]) >= 3 :
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
#글자 작성
plt.annotate(dispname,(row['x']+0.5, row['y']+0.5),
weight ='bold',
fontsize = fontsize, ha ='center',va ='center',
linespacing= linespacing)
#경계선 그리기
for path in BORDER_LINES:
ys, xs = zip(*path)
plt.plot(xs,ys, c = 'black',lw=1.5)
#상하 뒤집기 - 엑셀은 하단으로 갈때 좌표가 증가하지만
#모티너는 상단으로 갈 때 좌표가 증가합니다.
plt.gca().invert_yaxis()
#축 제거
plt.axis('off')
plt.show()

plt.gca().invert_yaxis()
위아래 뒤집어 졌다,



17.pop의 시도 이름과 draw_korea_raw_stacked의 id 일치시기키
=>set은 합집합 , 교집합 , 차집합 ,여집합을 계산할 수 있음
merge해서 id inner join
굳이 merge할 필요 없을 때는 set()을 기억하는 것이 좋다.
set -> 합집합 , 교집합 , 차집합 ,여집합
#pop의 ID와 draw_korea_raw_stacke의 ID 불일치 찾기
print(set(draw_korea_raw_stacked['ID'].unique())-set(pop['ID'].unique()))
print(set(pop['ID'].unique())-set(draw_korea_raw_stacked['ID'].unique()))
#서로 다른 것은 list로 만드다.
#pop에는 있는데 draw에는 없는 데이터 제거할 리스트 만들기
del_list = list(set(pop['ID'].unique())- set(draw_korea_raw_stacked['ID'].unique()))
print(del_list)
for rownum in del_list:
pop = pop.drop(pop[pop['ID']==rownum].index)
#리스트를 순회하면서 데이터를 제거
print(set(pop['ID'].unique())-set(draw_korea_raw_stacked['ID'].unique()))
18.pop와 draw_korea_raw_stacked을 join
#pop와 draw_korea_raw_stacked을 join
pop = pd.merge(pop, draw_korea_raw_stacked , how='inner', on =['ID'])
pop.info()
19.좌표와 인구수를 이용해서 pivot 테이블을 생성
#좌표와 인구수를 이용해서 pivot 테이블을 생성
mapdata = pop.pivot_table(index ='y', columns = 'x' , values ='인구수합계')
print(mapdata)
#NaN 제거를 위한 작업
#NaN데이터는 --로 변환
masked_mapdata = np.ma.masked_where(np.isnan(mapdata),mapdata)
print(masked_mapdata)
#NaN을 -- 로 바꿔졌다.
20.컬럼이름과 datarame그리고 색상 이름을 대입하면 catogram을 그려주는 함수 만들기
#컬럼이름을 문자열로 설정하고 데이터프레임을 대입하고 색상을
def drawKorea(targetData, blockedMap, cmapname):
gamma = 0.75
#인구수 데이터의 크고 낮음을 분류하기 위한 값 만들기
whitelabelmin = (max(blockedMap[targetData]) -
min(blockedMap[targetData]))*0.25 + \
min(blockedMap[targetData])
#컬럼이름을 대입하기
datalabel = targetData
#최대값과 최소값 구하기
vmin = min(blockedMap[targetData])
vmax = max(blockedMap[targetData])
#x 와 y를 가지고 피봇 테이블 만들기
mapdata = blockedMap.pivot_table(index='y', columns='x', values=targetData)
#데이터가 존재하는 것 골라내기
masked_mapdata = np.ma.masked_where(np.isnan(mapdata), mapdata)
#그래프 영역 크기 만들기
plt.figure(figsize=(9, 11))
#색상 설정
#지도에 색상을 설정
plt.pcolor(masked_mapdata, vmin=vmin, vmax=vmax, cmap=cmapname,
edgecolor='#aaaaaa', linewidth=0.5)
# 지역 이름 표시
for idx, row in blockedMap.iterrows():
# 광역시는 구 이름이 겹치는 경우가 많아서 시단위 이름도 같이 표시
#(중구, 서구)
if len(row['ID'].split())==2:
dispname = '{}\n{}'.format(row['ID'].split()[0], row['ID'].split()[1])
elif row['ID'][:2]=='고성':
dispname = '고성'
else:
dispname = row['ID']
# 서대문구, 서귀포시 같이 이름이 3자 이상인 경우에 작은 글자로 표시
if len(dispname.splitlines()[-1]) >= 3:
fontsize, linespacing = 10.0, 1.1
else:
fontsize, linespacing = 11, 1.
#글자색상 만들기
#글자 색상ㅇ을 다르게 한다.
#while 아니면 블랙
annocolor = 'white' if row[targetData] > whitelabelmin else 'black'
#텍스트 출력하기
plt.annotate(dispname, (row['x']+0.5, row['y']+0.5), weight='bold',
fontsize=fontsize, ha='center', va='center', color=annocolor,
linespacing=linespacing)
# 시도 경계 그리기
for path in BORDER_LINES:
ys, xs = zip(*path)
plt.plot(xs, ys, c='black', lw=2)
plt.gca().invert_yaxis()
plt.axis('off')
cb = plt.colorbar(shrink=.1, aspect=10)
cb.set_label(datalabel)
plt.tight_layout()
plt.show()
21.인구 수 합계 이용해서 그리기
#그리기
drawKorea('인구수합계', pop, 'Blues')
22.소멸위기 지역 그리기
print(pop.head())
#소멸위기지역을 수치 데이터로 변환 -True:1, False :0
pop['소멸위기지역'] = [1 if imsi else 0 for imsi in pop['소멸위기지역']]
drawKorea('소멸위기지역', pop, 'Blues')
**위의 데이터를 이용해서 단계구분도(colorpleth)그리기
=>단계구분도를 그릴때는 그리고자 하는 지도의 경계를 나타내는 json파일이 있어야 합니다.
=>우리나라 데이터는 southkorea-maps를 검색하면 github에서 제공
#단계구분도를 위한 라이브러리
import folium
import json
#데이터에서 지역이름을 인덱스로 설정
pop_folium = pop.set_index('ID')
print(pop_folium)
#표기하고자하는 지도의 경계선 데이터를 가져옵니다.
geo_str = json.load(open('./Desktop/data/korea_geo_simple.json',encoding='utf-8'))
print(geo_str)
#지도 출력
map = folium.Map(location=[36.2003,127.0541],zoom_start = 7)
map.choropleth(geo_data=geo_str,data = pop_folium['인구수합계'],fill_color='YlGnBu',key_on ='feature.id',
columns =[pop_folium.index,pop_folium['인구수합계']])
map.save('pop.html')
print(pop_folium.index)
print(pop[pop['광역시도'] == '서울특별시'])
#지도 출력
map = folium.Map(location=[36.2003,127.0541],zoom_start = 7)
map.choropleth(geo_data=geo_str,data = pop_folium['소멸위기지역'],fill_color='YlGnBu',key_on ='feature.id',
columns =[pop_folium.index,pop_folium['소멸위기지역']])
map.save('pop.html')
**기술통계
=>논리적 사고와 객관적인 사실에 따르며 일반적이고 확률적 결정론에 따라 인과관계를 규명
=>수집된 자료의 특성을 쉽게 파악하기 위해서 대표값이나 표 또는 그래프로 요약하는 기술통계학과 모집단에서 추출한 정보를 이용해서 다양한 특성을 과학적으로 추론하는 추론 통계학(검정, 분산분석 , 회귀분석)으로 나
눔
**기술통계
=>자료를 요약하는 기초적인 통계량
=>모집단의 특성을 유추
=>빈도분석 : 개수 파악
=>기술통계분석 : 평균이나 합계 등을 구하는 것
1.기술통계함수
=>numpy에서 numpy가 기술 통계함수를 소유 : numpy.mean(데이터)
=>pandas에서는 Series나 DataFrame이 기술 통계함수를 소유: DataFrame객체.mean()
DataFrame.mean(데이터프레임)
=>count, min,max, sum, std, var, median , mean(평균)
=>argmin,argmax, idxmin, idxmax(최대값을 가진 데이터의 위치)
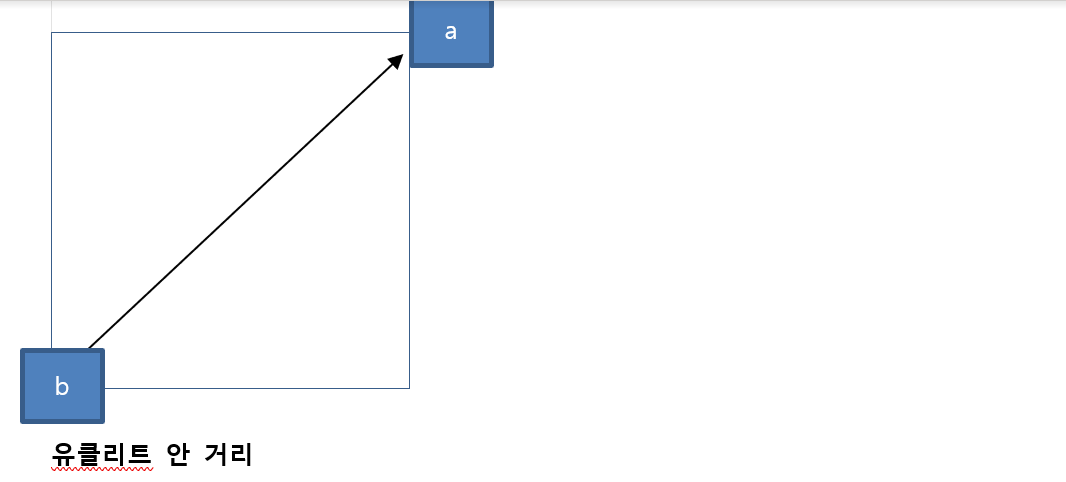
6과 차이가 가장 작은 수
1 5 3 9
5 1 3 3
결국에 찾아야 하는 것이 차이값의 위치 의 값 을 찾아야 한다. 5
차이가 최소 찾을 때 index를 찾아야 한다.
유클리티 거리 , 맨하튼 거리 거리의 가까운 것의 거리를 찾는 것이다.
=>quantile(사분위수) : IQR(75%에서 25% 뺀것 이상치 찾는 것 )
표준화 할 때도 필요 SCALLER할 때
STANDARD scaller
minmax scaller -> min max 극단치 가능성이 있다. 극단치가 너무 좌우가 된다.
그래서 robus scaller를 사용한다.
=>describe: 최대 , 최소 , 평균 ,중간값 , 4분위수를 리턴
=>diff(이전 항과의 차), pct_change(이전 항과의 비율)
=>하나의 컬럼에만 사용 가능한 함수 : unique()-유일한 값들 리턴 , value _count() - 각 데이터의 개수
2.평균(mean)
1) 산술 평균 :데이터의 총합을 데이터의 개수로 나눈 값
2)기하 평균 : 평균 비율을 구할 때 사용
매출액이 100인 회사에서 다음 해에 매출액이 110이 되었고 그 다음해에 107.8을 기록했다면 평균 성장률은?
첫해에 105증가했고 그다음해에 2% 로 감소했으므로 평균 성장률은 (10-2) / 2 = 4 % ? 이렇게 하면 안된다.
1.1 * 0.98의 제곱근
3) 조화평균: 2개의 값의 곱에 2를 곱한 후 2개의 수를 더한 값으로 나누는 것
동일한 거리를 시곡 100km 로 가고 한번은 60km로 갔을 때 평균 속도는 ?
300km을 갔다고 했을 때 평균속도는 ?
(2 * 100 * 60 ) / (100+60)
4).단순 이동 평균
=>모든 데이터의 평균을 구하는 것이 아니고 최근의 데이터 몇 개의 평균만 구하는 것
=>pandas의 Series를 가지고 rolling 메소드에 window에 데이터 개수를 설정해서 호출
5)지수 이동 평균
=>최근의 데이터에 가중치를 부여해서 평균을 구하는 것
=>pandas의 Series 를 가지고 ewm 메소드에 span 매개변수를 이용해서 데이터 개수를 설정해서 호출
6) 주가를 가지고 회귀를 할 때는 단순 이동평균이나 지수 이동평균을 사용해야 합니다.
(최근데이터 + (1-알파)이전데이터 + (1-알파)제곱 * 이전의 이전데이터)/(1+(1-일파) +(1-알파)제곱)
###평균 그하기
s = pd.Series([10,11,10,78])
#비율 평균을 산출 평균으로 구하기
print(s.pct_change().mean())
import math
#평균 비율울 구할 때는 기하 평균을 사용
print(math.sqrt((11/10)*(10.78/11)) - 1)
#속도의 경우는 조화 평균을 사용
#동일한 거리르 100km 의 60km 로 달린 경우
print(2* 100* 60/(100+60))
#단순 이동 평균
print(s.rolling(window = 2))
#지수이동 평균 가중치를 0.5가지고 한다.
print(s.ewm(span= 2))
절사 평균 :양 극단치의 데이터를 제거하고 평균을 구하는 것
3. 중간 값(median)
=>데어터를 정렬했을 때 가장 중앙에 있는 값
=>데이터가 짝수인 경우는 중앙의 좌우값 평균을 이용
1 2 3 4 5: 중간값 - 3
1 2 3 4 5 6 : 중간ㄱ밧 - 3.5
=>중간값 데이터는 데이터 그룹에 없을 수도 있음
평균은 극단치에 매우 민감합니다.
극단치가 있을 때는 중간값이나 최빈값을 모집단을 대표하는 값으로 사용하는 것이 좋습니다.
시애틀에서 메디나와 원더미어 주변의 소득을 비교하는 경우 메디나에 빌게이츠가 삽니다.
평균을 가지고 비교하면 메디나 높게 나을 가능성이 높습니다.
이런 경우에는 중간값이나 최빈값을 모집단을 대표하는 값으로 사용하는 것이 좋습니다.
**척도
=>변수 , 변량, 컬럼 ,열 이라고도 부르는 테이블에서의 열
1.descriptive.csv
=>부모의 학력 수준에 따른 자녀의 대학진학 합격 여부를 조사한 데이터 셋
=>300개의 행과 8개의 열로 구성
=>열의 으미
resident: 거주지역(1,2,3 - 서울 , 광역시 ,시군구)
gender: 성별(1,2, - 남자,여자)
age:나이
level: 부모의 학력 수준(1,2,3 ~ 고졸 ,대졸 ,대학원졸 이상)
cost: 생활비
type: 학교 유형 (1,2 ~-4년제 , 4년제 미만)
survey: 만족도(1-2)
pass: 합격여부(1,2 ~ 합격 , 불합격)
#descriptive.csv파일 읽기
df = pd.read_csv('./Desktop/data/descriptive.csv')
print(df.head()) #데이터가 읽어지는 지 확인
df.info() # 데이터의 특성 확인 , 개수,
print(df.describe())#기술 통곟 확인
2. 명목 적도
=>구분 만을 위해서 의미없는 숫자로 만든 데이터 : 범주형이라고 하기도 합니다
=>거주지역이나 성별처럼 특별한 의미없이 구분만을 위해서 만든 척도
=>기술통계량을 구하는 것이 아무런 의미가 없음
=>이런 데이터는 비율만 확인하는 것이 일반적
=>막대 그래프나 원 그래프를 그려서 크기를 확인
=>이 척도가 분규의 타겟으로 사용이 된다면 비율이 거의 같은 것이 올바른 결과를 유추할 가능성이 높아집니다.
차이가 많이 나면 데이터를 더 수집하거나 다운샘플링이나 업샘풀링 등을 해주어야 한다.
#gender 값의 개수만 확인
df['gender'].value_counts().plot.bar(color='k')
#0하고 5 도 있다.
#이상한 데이터 확인 - 0, 5
df = df[(df['gender'] == 1 )| (df['gender'] == 2)]
df['gender'].value_counts().plot.bar(color='k')
3. 서열 척도
=>구분 뿐 아니라 순위를 표현하는 숫자로 만든 데이터 : 범주형
=>학력 수준이나 학교에서의 성적 순위 같은 데이터
=>명목 척도 처럼 기술 통계는 별 의미가 없고 비율만 확인하는 것이 일반적
=>순서는 명확하지만 순서마다 차이는 일정하지 않고 알기가 어려움
4.등간 척도
=>범주형으로 구분, 순위 그리고 각 값의 간격이 일정한 데이터
=>학교에서의 점수 , (90점하고 80점은 10점 더 잘 했다. ) ,및 설문 조사에서의 만족도
=>이 경우 부터는 기술 통계량이 의미를 갖음
5. 비율적도
=>연속형 데이터로 만들어진 데이터
=>사용자의 입력으로 만들어지는 데이터
=>기술 통계값이 의미를 갖음
=>빈도 분석할 때 주의 해야 합니다.
빈도 분석을 하게되면 너무 많은 항목이 만들어질 수 있습니다.
bining(구간 분할)을 해서 빈도 분석을 하는 것이 일반적입니다.
**표본 추출
=>전수 조사와 표본 조사
=>전수 조사는 모집단 내의 모든 대상을 상대로 조사하는 것
모집단의 특성을 정확하게 반영
비용과 기간이 많이 소모
=>표본조사는 모집단에서 일정한 대상을 샘플링해서 조사하는 것
전수조사의 단점을 보완할 수 있지만 잘못된 샘플링을 하게 됨녀 모집단의 특성을 정확하게 반영할 수 없습니다.
=>모수는 모집단의 특성을 나타내는 수치를 의미하고 통계량은 표본의 특성을 나타내는 것
통계량이 모수의 특성을 얼마나 잘 나타낼 수 있는가 ?
값이 얼마나 비슷한가
=>sample(표본) : 큰 데이터 집합으로부터의 부분 집합
=>population (모집단) : 데이터 전체 대상
=>N(n) : 모집단의 개수
=>랜덤 표본 추출 : 무작위 표본
(안에 아래 두개 있ㄷ.)
=>층화 표본 추출 : 모집단을 층으로 나눈 뒤 각 층에서 무작위로 데이터를 추출하는 것
=>단순 랜덤 추출 : 층화없이 표본을 추출하는 것
=>복원추출 : 이전에 추출된 데이터를 다시 모집단에 넣고 추출 (주사위 )
=>비복원 추출: 이전에 추출된 데이터를 모집단에서 제거하고 추출 (로또 )
=>표본 편향 : 잘못된 표본 (여론 조사하는데 단순 랜덤 추출하면 표본 편향이다.)
시청률이 높다고 해서 이슈화 되지 않는다. 20~30대 얼마 시청 했는냐 ? 화재성 여론조사는 단순 랜덤 추출하면 안되고 층화 표분 추출해야 한다.
=>추정
-점 추정 : 하나의 값과 일치하는 지 추정
-구간 추정: 범위를 가지고 추정
-신뢰수전 :계산된 구간이 모수를 포함할 확률 을 의미하면 보통 90% , 95% , 99% 를 사용
-유의수준(머신러닝할 경우 대부분 이것을 본다.) : 계산된 구간이 우연히 모수의 특성을 포함할 확률 0.1 . 0.05, 0.01을 사용
이름은 p-value
유의수준과 신뢰수준은 반대이다.
<= 0.05 우연히 나올 확률은 그것 밖에 안된다.
특정 유의 수준을 설정하고 그 유의 수준보다 낮게 나오면 기각 한다던가 채택을 합니다.
-신뢰구간: 모수를 포함할 상한값과 하한값
-표본오차(잔차): 모집단에서 추출한 표본이 모집단의 특성과 정확히 일치하지 않아서 발생하는 확률의 차이
-대통령 후보의 지지율 여론조사에서 후보의 지지율이 95%신뢰수준에서 표본오차 +- 3%범위 내에서 32.4%로 조사 되었다는 의미는
지지율이 29.4 ~ 35.4 %가 나올 확률이 95%라는 의미입니다.
5%는 틀릴 수도 있다.
1.단순 임의 추출
=>파이썬에서의 random모듈이 제공
random.random()을 이용하면 복원 추출
random.sample()을 이용하면 비복원 추출
random.shuffle(시퀀스 자료형): 을 이용하면 시퀀스 자료형을 랜덤하게 섞음
random()함수는 0과 1사이의 실수를 리턴
randrange(시작숫자, 종료숫자)를 이용하면 범위를 변경
randint(시작숫자, 종료숫자)
import random
li = list(range(1,40,1))
print(li)
print(random.shuffle(li))#섞어 버렸다.
print(li)
#비복원 추출
print(random.sample(li, k = 4))
#할 때마다 다른 것 나온다.
2.가중치를 설정한 추출
=>numpy의 choice메소드를 이용하면 가중치를 설정해서 추출이 가능
=>choice(배열 , size = 추출할 개수 , replace =복원추출여부 ,p =[확률])
=>데이터의 비율이 동일하지 않을 떄는 확률을 설정해서 추출해야 합니다.
0-10
1-90
결과가 외곡 할 수 있다. 단순 랜덤 추출하면 1이 70개 나올 수 있다.
그래서 비율로 나와야 한다.
0-50
1-30
2-20
테스트 데이터 7:4 는 같기 때문이다.
iris -> 5:5:5같기 같기 떄문에
li = ['라투','오미크론','다크스펙터','나이즈']
print(np.random.choice(li, 4)) #동일한 비율로 추출
print(np.random.choice(li, 4, p = [0.05, 0.3, 0.15, 0.5])) #나이즈 나올 확률이 높아진다.
3.pandas의 랜덤한 행 추출
=>Series나 DataFrame의 sample메소드
n: 추출한 데이터 개수
frac: 전체 개수에서 추출할 비율 -n과 Frac은 같이 설정 불가
replace: 복원 추출 여부로 기본값은 False
weight: 가중치
random_state: 시드 번호 - 계속 나오는 매개변수 중의 하나
머신러닝할 때 이 옵션의 값을 변경하면서 수행
axis: 추출할 방향으로 기본은 행 단위로 추출
4.scikit-learn 라이브러리의 model_selection 클래스의 train_test_split()이용
=>샘플링할 때 가장 많이 사용하는 함수
=>무작위 샘플링을 할 떄는 shuffle
=>
=>test_size옵션
overfit(과적합)
=>훈련 데이터에는 잘 맞는데 시험데이터에 잘 안맞는 경우
=>훈련데이터가 너무 많거나 변수가 너무 많을 때
두개를 하나로 만들어는 것 고유백터 교차 항
**python에서 인스턴스 메소드 호출
클래스.메소드이름(인스턴스) -unbound호출
인스턴스.메소드이름() -bound호출
class X:
def funct(self):
print('인스턴스 메소드')
x = X()
x.func() -bound호출
X.func(x) ->unbound호출










































{kind=link}