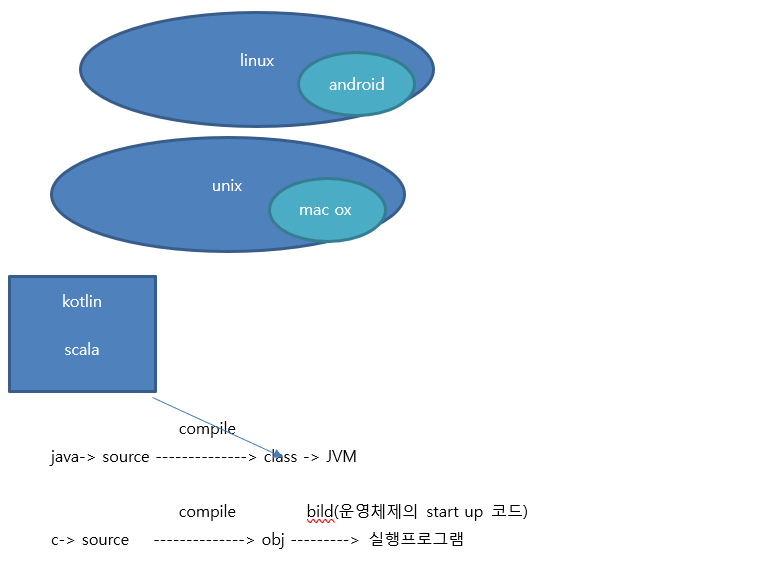
**일반적인 python이나 anaconda를 이용해서 설치한 파이썬 -C로 만들어진 PYTHON
=>C언어로만든 라이브러리를 파이썬에서 사용할 수 있음
=>C언어는 소스코드를 가지고 실행 파일을 만들어서 배포
실행 파일을 만들 때 운영체제의 start up코드가 포함되어야 합니다.
실행되는 프로그램이 운영체제마다 다릅니다.
=>windows에서 실행되는 c언어는 ms-c이고 이 언어로 프로그램을 만드느 대표적인 ide가 visual c++ 이고 이 visual c++로 만들어진 프고르램을 실행시키기 위해서 재배포 패키지나 build tool이 설치되어 있어야 합니다.
**windows애서 python t실행시 라이브러리가 설치되지 않는데
visual c++ 14.0이 설치되어 있어야 하는데 설치되어 잇지 않다는 에러 메시지가 출력되는 경우
-visual studio 2015 재배포 패키지 설치 : 설치해도 잘 안됨
-visual studio 2015 build tools 설치 : 설치해도 잘 안됨
-visual studio 최신 버전 설치 : visual studio community버전 다운로드
ar . vr 게임 등 관심있으면 unity
mmo rpg ->언니얼
microsoft vr tool -> 테이블 그래는 것 자동으로 하는 것
데이터 적을 때 는 오차 , 정밀도 , 재현울 , F1점수 roc 곡선 등
** 불균형한(개수가 다른 경우) 클래스의 데이터를 가지고 분석을 해야 하는 경우
=>샘플 자체의 개수가 작을 떄는 자료를 더 수집하는 것이 가장 좋은 방법
=>데이터 를 수집하는 것이 가능하지 않을 때는 데이터에 가중치를 적용해서 사용- 분류 알고리즘의 매개변수 중에서 weight가 있으면 이 매개변수가 데이터에 가중치를 적용할 수 있는 매개변수 입니다.
=>개수가 작은 데이터의 개수를 강제로 늘리거나 개수가 많은 데이터의 개수를 줄이는 업샘플링이나 다운 샘플링을 해서 알고리즘에 적용
=>평가지표를 다양하게 선택 - 정확도 대신에 재현율이나 F1 통계량 등을 이용
정확도 , 재현율 등 .. 어느 하나 선택할 때는 결과가 외곡 될 수 있다.
정확도 , 재현율 ,F1통계량 결정 계수 등 정확하게 뭘 의미하는 지 알아야 한다.
분석은 어렵지 않다.그 결과를 판정하는 데 어렵고 뭐하는지 알아야 한다.
import numpy as np
import pandas as pd
#0이 10개이고 1이 90개 인 ndarray생성
list1 =[]
for i in range(0,10,1):
list1.append(0)
list2 =[]
for i in range(0,90,1):
list2.append(1)
#2개의 list를 가지고 하나이 array생성
target = np.array(list1+ list2)
#list더하기 하면 결합이고
#분석은 더하기 하면 더하기 이다.
print(target)
#분류 알고리즘에 위의 데이터를 이용하는 경우
#0: 10% 1 : 90%
from sklearn.ensemble import RandomForestClassifier
#데이터의 비율이 헌저하게 다르기 때문에 가중치 설정
weights = {0:0.9, 1:0.1}
#비율은 반대로 쓴다. 10%, 90%
#0.9 = .9
rfc = RandomForestClassifier(class_weight = weights)
print(rfc)
#assemble하고 down는 같이 하면 안된다.
#가중치를 직접 설정하지 않고 분류기에게 판단하도록 해주는 옵션
rfc = RandomForestClassifier(class_weight='balanced')
print(rfc)
#샘플링 비율 조건
#np.where(target == 0)
#target행렬에서 값이 0인 데이터의 행번호를 리턴
#(행번호행렬, 자료형)으로 결과를 리턴
#행번호행렬만 가져오기 위해서 [0]을 추가
class0 = np.where(target == 0)[0]
class1 = np.where(target == 1)[0]
print(len(class0))
print(len(class1))
#target이 1인 데이터에서 target이 0인 데이터만큼 다운 샘플링을 해서
#새로운 데이터 셋을 생성
#class1에서 class0의 데이터 개수 만큼 비복원 추출 (나온것은 제거)
#assembling랄 때는 복원 추축
downsample = np.random.choice(class1, size = len(class0) , replace= False)
result = np.hstack((target[class0], target[downsample]))
#0개에서는 90개 만들 수 없다.
#downsample = np.random.choice(class0, size = len(class1) , replace= True)
#result = np.hstack((target[class1], target[downsample]))
print(result)
** 다변량 분석에서 데이터의 상대적 크기 문제
=>다변량 분석 - 2개이상의 컬럼의 데이터를 가지고 분석
=>하나의 컬럼의 데이터는 값의 범위가 0-100이고 다른 컬럼의 데이터는 값이 범이가 0-1이라면 이 경우 2개의 데이터를 가지고 다변량 분석을 하게 되면 첫번째 컬럼의 영향을 받게 될 수 있습니다.
이런 경우에는 값의 범위를 일치시켜 주는 것이 좋습니다.
=>값의 범위는 같은데 분포가 다른 경우에도 분포를 기준으로 값을 조정할 필요가 있습니다.
최대값으로 나누거나 최대값 - 최소값을 분모로하고 해당값 - 최소값을 분자로 해서 값을 조정
=>이러한 값의 조정을 scalling이라고 합니다.
0-1 사이나 -1~1사이로 조정합니다.
더 큰 값으로 가능하지만 머신러닝 모델에서는 값으 크기가 커지면 정확도가 떨어집니다.
1.표준화
=>모든 값들의 표준 값을 정해서 그 값을 기준으로 차이를 구해서 비교하는 방법
1)표준값: (데이터- 평균) /표준편차 -표준 값의 평균은 50 (사람한테 줄 때 )
2)편차값: 표준값 * 10 + 50 -위의 숫자보다 큰 숫자로 변환
#표준화
#student.csv파일의 내용을 가져오기
#index로 이름을 설정
import os
print(os.getcwd())
#utf8이 아니다.
data = pd.read_csv('./Desktop/data/student.csv', index_col ='이름',encoding = 'cp949')
print(data)
#그래프에 한글을 출력하기 위한 설정
import matplotlib.pyplot as plt
import platform
from matplotlib import font_manager, rc
#매킨토시의 경우
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
#윈도우의 경우
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#인덱스를 기준으로 해서 막대 그래프 그리기
data.plot(kind='bar')
#표준값 - 작업
#평균을 표준 편차로 나누어서 계산
#각과목의 평균과 표준편차 구하기
kormean, korstd = data['국어'].mean(), data['국어'].std()
engmean, engstd = data['영어'].mean(), data['영어'].std()
matmean, matstd = data['수학'].mean(), data['수학'].std()
#표쥰값 구하기 -(자신의 값 - 평균 )/ 표준편차
#내가 0.0이면 중간
#편차값이 1.0이면 항상 상하위 15%
#2.0 상하위 1.1%
#음수가 있을 수 있다.
data['국어표준값'] = (data['국어']- kormean )/korstd
data['영어표준값'] = (data['영어']- engmean )/engstd
data['수학표준값'] = (data['수학']- matmean )/matstd
print(data[['국어표준값','영어표준값','수학표준값']])
#박지영은 국어는 영어보다 잘 한다. 수학은 못한다.
#음수를 잘 안보이기 때문에 우리가 자주사용하는 숫자로 변한다.
#표준값은 비교가 가능하기는 하지만 사람이 알아보기 불편
#표준값 * 10 + 50 을 해서 편차값을 만들어서 보고서를 만듬
data['국어표준값'] = data['국어표준값']* 10 + 50
data['영어표준값'] = data['영어표준값']* 10 + 50
data['수학표준값'] = data['수학표준값']* 10 + 50
print(data[['국어표준값','영어표준값','수학표준값']])
data[['국어표준값','영어표준값','수학표준값']].plot(kind='bar')
#최대값으로 나누어서 표준화 - 정규화로 많이 불리운다.
#자신의 값 - 최소값/ 최대값 - 최소값으로 하기도 함
#0.0 ~ 1.0 사이로 있다.
data['국어정규화1'] = data['국어'] / data['국어'].max()
data['국어정규화2'] =( data['국어']- data['국어'].min()) / (data['국어'].max()-data['국어'].min())
2.sklearn의 정규화
1)StandartScaler: 평균이 0이고 표준편차가 1이 되도록 변환
(백터- 평균) / 표준편차
주로 주성분분석에서 많이 이용
음수가 잇을 가능성 있다.
2)MinMaxScaler: 최대값이 1 최소값이 0 이 되도록 변환
(백터 - 최소값) /(최대값 - 최소값)
신경망에서 주로 이용 (cnn, rnn)
3)RobustScaler: 중앙값이 0 IQR(4분위수 )를 이용하는 방식
(백터 - 중간값) /( 75%- 255)
=>앞의 방식들은 outlier(이상치)에 영향을 많이 받습니다.
=>데이터의 분포가 불균형이거나 극단치가 존재하는 경우에 주로 이용
0 1 2 3 4 5 6 100->이상치가 있을 수 있다. 1),2) OUTLIER
그래서 75%의 값 25%의 값
그래서 최대값 최소값 영향을 받지않는다.
4)QuantileTransformer:데어터를 1000개의 분위로 나눈 후 0-1 사이에 고르게 분포시키는 방식
=>outlier 의 영향을 적게 받기 위해서 사용
0 ~ 100 사이의 데이터인데
17 27 25 16 41 33 27 -> 이렇게 된것은 표준화 하면 안좋다. 데이터의 분포가 작아서
표준화 하면 꼭 고려해야 할 두가지 데이터 분포 , outlier
아주 큰 값 있으면 하나 버리기
데이터 분포가 완전히 쏠려져 있을 경우에는 정규화를 하지 않는다.
변화 하면 fit_transform
모델에 적용하면 fit 이다.
표준화는 값만 가지고 해야 한다.
#표준화 작업
#sklearn을 이용한 scailing
from sklearn import preprocessing
#StandardScaler
#StandardScaler - 평균은 0 표준편차는 1이 되도록 표준화
scaler = preprocessing.StandardScaler()
#국어 점수만 이용하는 경우 data['국어'] 가 아닌고 data[['국어']]
#머신러닝의 데이터들은 행렬을 이용하는데 data['국어']하게 되면 컬럼이름이
#1개라서 하나의 열로 리턴되서 1차원 데이터가 됨
#data[['국어']] 하게 되면 list를 대입하기 때문에 datafrmae으로 리턴
result = scaler.fit_transform(data[['국어']].values)
print(result) #표준값 구한 것
print(np.mean(result)) #평균이 0에 가까워진다. 1.2335811384723961e-17 ->거의 0이다 e의 17승
print(np.std(result)) # 값이 1에 가까워진다.
#MinMaxScaler
#MinMaxScaler - 음수가 안나온다. 최대값 최소값 이용해서 하기 때문에
scaler = preprocessing.MinMaxScaler()
result = scaler.fit_transform(data[['국어']].values)
print(result)
print(np.mean(result))
print(np.std(result))
#RobustScaler
#RobustScaler - 음수가 나온다. 이상치 값이 있을 때 해결하기 위한 것
scaler = preprocessing.RobustScaler()
result = scaler.fit_transform(data[['국어']].values)
print(result)
print(np.mean(result))
print(np.std(result))
#QuantileTransformer
#QuantileTransformer - 음수가 나오지 않는다. 데어터 분포를 고려해야 한다. 데이터가 적으면 안된다.
scaler = preprocessing.QuantileTransformer()
result = scaler.fit_transform(data[['국어']].values)
print(result)
print(np.mean(result))
print(np.std(result))
**정규화
=>값의 범위를 0 -1 사이의 데이터로 변환
=>표쥰화는 일정한 범위 내로 데이터를 변환하는 것이고 정규화는 0-1 사이로 해야 합니다.
=>Normalizer클래스를 이용해서 transform메소드에 데이터를 대입하면 됩니다.
이 때 norm매개변수에 옵션을 설정할 수 있는데 l1, l2, max등의 값을 설정할 수 있습니다.
max는 최대값으로 나누는 방식
l1과 l2는 거리 계산 방식
l1- 맨하턴 거리를 이용하고 l2는 유클리드 거리를 이용
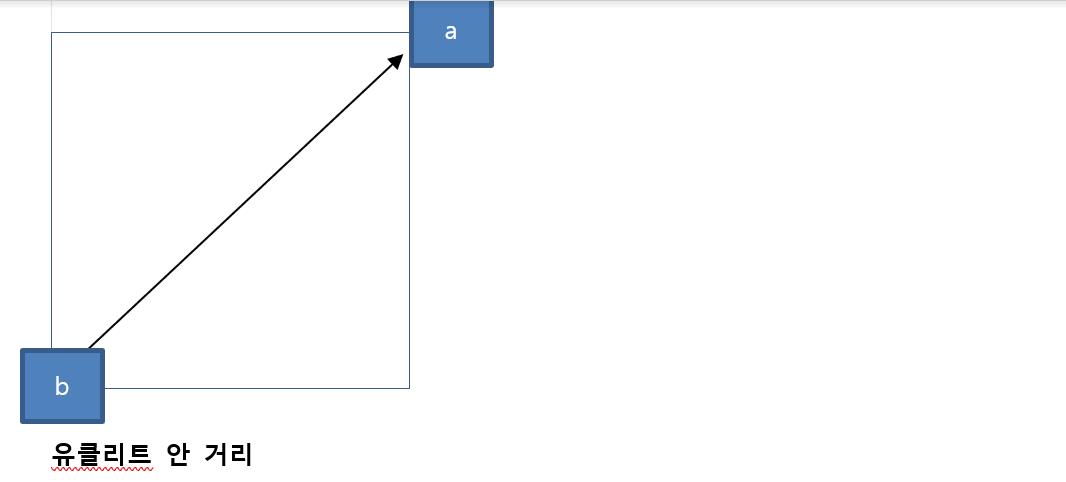
맨하탄 거리 -> 장애물이 있을 경우에는 직접 못간다.'
이 두개 크기 자체는 별로 차이 안나는데 계산 방식이 다르다.
게임 shoting게임 할 때 사용한다.
A 과 B 거리 계산 할때 거리 계산한다. 거리가 멀면 시간이 오래 걸린다.
ping할 때 ttl ->라우터의 계수
#이차원 행렬을 생성
matrix = data[['국어','영어']].values
print(matrix)
matrix = np.array([[30,20],[10,30],[30,40]])
print(matrix)
from sklearn import preprocessing
#l1- 맨하턴 거리를 이용하고 l2는 유클리드 거리를 이용
#정규화 객체 생성 - 유클리디안 거리를 사용
norm = preprocessing.Normalizer(norm = 'l2')
print(norm.transform(matrix))
# 30 / 30의 2승 + 40의 2승 에 root => 30 / 50
#합을 가지고 나누느 방식
norm = preprocessing.Normalizer(norm = 'l1')
print(norm.transform(matrix))
# 30 / 50 20/50
#큰값을 가지고 나누는 방식
norm = preprocessing.Normalizer(norm = 'max')
print(norm.transform(matrix))
#30/40 40/40
** 다항과 교차항 특성
=>기존 데이터에 데이터들을 곱하고 제곱을 해서 데이터를 추가하는 것
=>특성과 타겟 사이에 비선형 관계과 존재할 때 사용하는 방식
=>비선형 관계는 2개의 관계가 직선의 형태가 아니고 곡선의 형태인것
=>각 특성이 다른 특성에 영향을 줄 때 각 특성을 곱할 교차형을 가지고 인코딩
=>다변량 분석(2개 이상의 컬럼을 가지고 분석) 을 할 때 2개의 컬럼 사이에 상관관계가 있는 경우가 있는데 이런 경우 2개의 컬럼 모두를 가지고 분석을 하게 되면 다중공선성 문제가 발생할 수 있습니다.
어떤 컬럼의 값을 알면 다른 컬럼의 값을 예측할 수 있는 경우 발생할 수 있는 문제입니다.
이런 경우에는 2개의 컬럼을 1개의 컬럼으로 변환하는 작업을 해야 하는데 (차원축소) 이런 경우 더하거나 거나 제곱해서 새로운 값을 만들어냅니다ㅣ.
=>PolynomialFeatures 클래스를 이용하는데 몇 차 항 까지 생성할 것인지 degree에 설정
첫번 떄 데이터로 1을 추가할 지 여부를 include_bias에 설정
=>연산식의 순서는 get_features_names메소드를 이용해서 확인 가능
[ 1 , 2 ] degree = 2 제곱 까지 만 한다.
[1 , 2 , 1의 제곱 1, 1 * 2 = 2, 2의 제곱 = 4 ]
2를 적용하면 5개 데이터를 만든다.
[4,7]
[4, 7, 16, 28, 49 ]
degree = 3
[4, 7, 16, 28, 49 , 64, .......]
[[ 4. 7. 16. 28. 49. 64. 112. 196. 343.]]
차원 축소 할 때 데이터를 만들어 낸다.
4의 2승 * 7 ,
28 * 6 * 7 = 196
matrix = np.array([[30,20],[10,30],[30,40]])
print(matrix)
#다항과 교차항을 만들어주는 객체를 생성
#include_bias = False 첫번 때 0을 안 집어 여겠다.
# degree = 2: 제곱한 것 까지 생성
polynomial = preprocessing.PolynomialFeatures(degree = 2, include_bias = False)
result = polynomial.fit_transform(matrix)
print(result )
matrix = np.array([[4,7]])
print(matrix)
polynomial = preprocessing.PolynomialFeatures(degree = 3, include_bias = False)
result = polynomial.fit_transform(matrix)
print(result )
**표준화나 정규화는 직접 하는 경우가 많지만 다항식을 만드는 것은 머신러닝 알고리즘에서 자체적으로 처리하는 경우가 많음
**특성 변환
=>데이터에 동일한 함수를 적용해서 다른 데이터로 직접 변환하는 것
=>pandas에서는 apply메소드를 이용하고 sklean에서는 preprocessing.FunctionTransformer나 ColumnTransformer클래스를 이용ㅇ
=>FunctionTransformer는 모든 열에 동일한 함수를 적용하고 ColumnTransformer는 서로 다른 함수를 적용할 수 있습니다.
객체를 생성할 때 적용할 함수를 설정해서 만들고 transform 메소드에 데이터를 대입하면 됩니다.
import numpy as np
from sklearn import preprocessing
#함수 적용하기
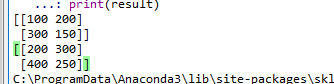
matrix = np.array([[100,200],[300,150]])
print(matrix)
#위 데이터를 정수로 변환하기
#100을 결합하기
def intconvert(x):
return x + 100
#행렬을 변환해서 리턴해준다.
transformer = preprocessing.FunctionTransformer(intconvert)
result = transformer.fit_transform(matrix)
print(result)
print(data['국어'])
print(data['국어'].apply(intconvert))
**Outlier 감지
=>Outlier 이상치나 극단치 , 일반적인 데이터의 범위를 넘어선 값
1.z점수를 이용하는 방법 : 중앙값을 기준으로 표준편차가 3 또는 -3 범위의 바깥똑에 있는 데이터를 Outlier 로 간주
2.z점수의 보정 :z 점수는 데이터가 12개 이하이면 감지를 못함
넘 작으면 표준편차가 잡지 못하기 때문에
편차의 범위를 3.5로 늘리고 0.6745를 곱한 값을 이용
3.IOR(3사분위수 - 1사 분위수)이용: 1사분위수 (25%)보다 1.5 IQR 작은 값이나 3사분위수(75%) 보다 1.5IQR 큰 데이터를 outlier 로 간주
1,2,3 10004
10010/4
1,2,3 10004 , 10004 => 이 경우에는 outlier가 알될수 도 있다. 많이 적으면 outlier가 나올 수 있다.
import numpy as np
import pandas as pd
#array를 입력받아서 z 점수(표준편차의 3배) 밖에 있는 데이터를 리턴해주는 함수
def z_score_outlier(ar):
threshold = 3
#평균 가져오기
meandata = np.mean(ar)
stdevdata = np.std(ar)
#stdevdata for y in ar의 요소를 y에 하나씩 대입하고 앞에 수식을 적용해서 결과를 가지고
#다시 list를 만드는 것
z_scores = [(y-meandata) / stdevdata for y in ar]
return np.where(np.abs(z_scores) > threshold)
#샘플 데이터 생성
#features = np.array([[10,30,13,-20,4,12],[20000,3,5,4,2,1]])
#features = np.array([[10,30,1003,-20,4,12],[2,30,5,4,2,1]])
#(array([0], dtype=int64), array([2], dtype=int64)) 0에 2번
#features = np.array([[10,30,13,-20,4,12],[2,9,5,4,2,10]])#없다.
features = np.array([[10,30,13,-2000000,4, 12, 10,30, 13, 11, 4, 12,10,30,13,20,4,2,4,2],
[2,9,5,4,2,2000000,10,30,13,20,4,12,10,30,13,20,4,2,4,2]])
#(array([0, 1], dtype=int64), array([3, 5], dtype=int64))
#0번에 3 1번에 5
result = z_score_outlier(features)
print(result)
#z score 보정 -범위를 3.5배로 널리고 표준편차 0.6875를 곱해줍니다.
def modify_z_score_outlier(ar):
threshold = 3.5
#평균 가져오기
meandata = np.mean(ar)
stdevdata = np.std(ar)
#stdevdata for y in ar의 요소를 y에 하나씩 대입하고 앞에 수식을 적용해서 결과를 가지고
#다시 list를 만드는 것
z_scores = [0.6875 * (y-meandata) / stdevdata for y in ar]
return np.where(np.abs(z_scores) > threshold)
#샘플 데이터 생성
features = np.array([[10,30,13,-20,4, 12, 10,30, 13, 11, 4, 12,10,30,13,20,4,2,4,2],
[2,9,5,4,2,2000000,10,30,13,20,4,12,10,30,13,20,4,2,4,2]])
#(array([0, 1], dtype=int64), array([3, 5], dtype=int64))
result = modify_z_score_outlier(features)
print(result)
#iqr이용 : 3 사분위수 - 1사분위의 +- 1.5 배이상 차이나면 이상치로 간주
def iqr_outlier(ar):
#25%와 75%의 값 찾기
q1 ,q3 = np.percentile(ar,[25,75])
#iqr값 찾기
iqr = q3- q1
#25% 값과 .5 iqr보다 작은 값 찾기
lower = q1- iqr*1.5
upper = q3 + iqr* 1.5
return np.where( (ar > upper )| (ar < lower))
#샘플 데이터 생성
features = np.array([[10,30,13,-20,4, 12, 10,30, 13, 11, 4, 12,10,30,13,20,4,2,4,2],
[2,9,5,4,2,2000000,10,30,13,20,4,12,10,30,13,20,4,2,4,2]])
result = iqr_outlier(features)
print(result)
**Outlier처리
1.제거
=>설문조사를 했는데 이상한 데이터가 입력된 것 같은 경우
=>분석 목적에 맞지 않는 데이터인 경우
2.이상한 데이터로 표현해두고 특성의 하나로 간주
이상한 상황을 없에면 안되고 특수한 상황으로 해야 한다.
3. outlier의 영향이 줄어돌도록 특성을 변환 - 값의 범위를 줄임(표준화, 정규화 등)
=> 표준화 할 때는 RobustScalar를 이용하는 것이 좋음
house = pd.DataFrame()
house['price'] = [100000,200000,150000,10000000]
house['rooms'] = [1,3,2,100]
house['square'] = [11,23, 16, 1200]
print(house)
#이상한 데이터 제거 : 방이 5개 이상 제거
print(house[house['rooms'] < 6])
#이상한 데이터를 별도로 표시
house['outlier'] = np.where(house['rooms'] < 6 , 0,1)
print(house)
#값의 범위 줄이기 -np.log는 자연 로그를 계산
house['log'] = [np.log(x) for x in house['rooms']]
print(house)
** 시계열 데이터
=>날짜 및 시간에 관련된 데이터
1.pandas의 시계열 자료형
=>datatime64 : 부등호를 이용해서 크기비교를 할 수 있고 - 를 이용해서 뺄셈을 할 수 있음
=>Period:두개의 날 짜 사이의 간격을 나타내기 위한 자료형
=>시계열 자료형을 별도로 구성하는 이유는 일정한 패턴을 만들기 쉽도록 하기 위해서
2. 생성
=>문자열 데이터를 시계열로 변경 : pandas.to_datetime()이용
날짜 형식의 문자열과 format매개변수에 날짜 형식을 대입
#문자 데이터를 pandas의 시계열 데이터로 만들기
df = pd.read_csv('./Desktop/data/stock-data.csv')
print(df)
#자료형 확인
print(df.info())
#Date 컬럼의 값을 시계열로 변경해서 추가
df['newDate'] = pd.to_datetime(df['Date'])
print(df.info())
#위와 같은 데이터프레임에서는
#날짜를 index로 설정하는 경우가 많습니다.
df.set_index('newDate',inplace = True)
df.drop('Date',axis = 1 , inplace = True)
print(df.head())
3.Period 간격을 나타낸다.
=>pandas.to_period 함수를 이용해서 datatime을 period로 생성
freq 옵션에 기준이 되는 기간을 설정
=>freq옵션
D: 1일
W: 1주
M 1개월 (월말 기준)
MS: 1개월 (월초 기준)
Q: 분기말
QS : 분기초
A:연말
AS:초
B: 휴일제외
H,T,S,L,U,N: 시간 , 분 , 초 , 밀리초 , 마이코로초 , 나노초
#일정한 간격을 갖는 날짜 만들기
dates = ['2017-03-01','2017-06-01','2019-12-01']
print(dates)
#날짜로 변경
pddates = pd.to_datetime(dates)
print(pddates)# DatetimeIndex로 바꿔졌다.
#Period로 변환
pdperiod = pddates.to_period(freq = 'D')
print(pdperiod)
#PeriodIndex(['2017-03-01', '2017-06-01', '2019-12-01'], dtype='period[D]', freq='D')
pdperiod = pddates.to_period(freq = 'M')
print(pdperiod)
#PeriodIndex(['2017-03', '2017-06', '2019-12'], dtype='period[M]', freq='M')
pdperiod = pddates.to_period(freq = 'Q')
print(pdperiod)
pdperiod = pddates.to_period(freq = 'A')
print(pdperiod)
5.date_range()
=>일정한 간격을 소유한 날짜 데이터의 집합을 생성
=>매개변수
start: 시작 날짜
end: 종료 날짜
periods: 생성할 날짜 개수
freq: 간격
tx: 시간대
#일정한 간격을 가진 날짜 데이터 생성
ts_ms = pd.date_range(start = '2018-01-01',end = None, periods = 12, freq = 'M')
print(ts_ms)
ts_ms = pd.date_range(start = '2018-01-01',end = None, periods = 12, freq = 'D')
print(ts_ms)
#2H ->2시간씩
ts_ms = pd.date_range(start = '2018-01-01',end = None, periods = 12, freq = '2H')
print(ts_ms)
6.날짜 데이터에서 필요한 부분 추출하기
=>dt.year, dt.month, dt.day...
=>요일은 dt.weekday_name은 문자열로 dt.weekday하면 숫자로 리턴 (월요일이 0)
화면에 출력할 때는 문자열로 하고 머신러닝을 사용할 때는 숫자로 리턴 받습니다.
ts_year = df['newDate'].dt.year
print(ts_year)
df['year'] = df['newDate'].dt.year
print(df['year'])
7.python에서는 날짜는 datetime패키지의 datetime으로 제공
=>날짜 형식의 문자열을 가지고 날짜 형식의 데이터를 생성
8.shift함수를 이용하면 기존 날짜를 이동시키는 것이 가능
=>freq 매개변수에 간격을 설정할 수 있습니다.
#python의날짜 패키지
from datetime import datetime
dates = [datetime(2017,1,1),datetime(2017,1,4),datetime(2017,1,7)]
ts = pd.Series(np.random.randn(3) , index = dates)
print(ts)
print(ts.shift()) #데이터를 하나씩 민다. 아래쪽으로
print(ts.shift(1)) #데이터를 하나씩 민다. 아래쪽으로
print(ts.shift(-1)) #데이터를 하나씩 반대로 민다. 위로
9.resampling
=>시계열의 빈도를 변환하는 것
=>상위 빈도의 데이터를 하위 빈도의 데이터로 변환하는 것을 다운 샘플링이라고 하고 반대의 과정을 asampling이라고 한다.
=>resampling(freq, how, fill, method, closed, label , king)
freq: 리샘플링 빈도(M,Q, A등)
how: 집계함수를 지정하는 것으로 기본은 mean(평균을 구한다.) first, last, max, median ,min등
데이터가 있으면 합계등 골라내다.
fill_method: 업 샘플링할 때 데이터를 채우늠 옵션이므로 기본은 None인데 fill이나 bfill을 설정해서 이전값이나 이후값으로 채울 수 있음
closed: 다운 샘플링을 할 때 왼쪽과 오른쪽 어느쪽을 호팜시킬지 설정
label: 다운 샘플링을 할 때 레이블을 왼쪽 또는 오른쪽을 사용할 것인지 여부
#일정한 조건으로 집계
ran = pd.date_range('11/3/2010',periods = 20, freq ='T')
print(ran)
ts = pd.Series(np.arange(20),index = ran)
print(ts)
#5개씩 하면 5분단위로 할 수 있다.
#실데이터는 다르다. 10분마다
#label을 0분이나 4분이나 할 것이다
#5분 단위로 합게
print(ts.resample('5T').sum())
print(ts.resample('5T').mean())
10.날짜 데이터가 데이터프레임에 존재하는 경우 날짜 데이터를 인덱스로 설정하면 특정 시간단위로 집계를 하는 것이 쉬워집니다.
**이동시간 윈도우
=>통계적 수치를 계산을 할 때 최근의 데이터에 가중치를 부여해야 한다라는 개념
평균을 구할 때 데이터 전체의 평균을 구하는 것 보다는 최근의 데이터 몇 개의 평균을 구하는 것이 미래를 예축할 때는 더 잘 맞을 가능성이 높다.
이전 데이터와 최근의 데이터를 같이 사용할 거라면 최근의 데이터에 가중치를 부여하는 것이 미래를 예측할 때는 더 잘 맞을 가능성이 높다.
1.rolling 함수
=>단순 이동 평균을 계산해주는 함수
=>winodw 매개변수에 데이터 개수를 설정하면 데이터 개수 단위로 연산을 수행
2.ewm함수
=>지수 이동 평균을 계산해주는 함수
=>지수 이동 평균은 최근의 데이터에 가중치를 부여하는 방식의 평균
주식 데이터는 이 평균을 사용합니다.
=>기간(span)을 설정하면 아래 수식으로 평균
데이터가 3개인 경우
x1, x2, x3(가장 최근 데이터)
1-span을 알파라고 합니다.
x3+(1-(1-span)) x2 +(1-(1-span) )제곱 x3 / 1 + (1-알파) +(1-알파)제곱
숫자를 줄인다.
500 2000 2300 2700
3일
2000 +2500+2700 / 3
반영율을 조정한다.
2500 + (1-1/3) * 2000 + (1-1/3)2 의 제곱 * 2000
지수 이용 평균
어느 속도를 기준해서 낮아진다. 불량율 , 숙련도 주식등에서 많이 사용한다.
시간에 따라 변경되는
데이터를 가지고 계속 할 때는 최근의 데이터
가중치를 부여해야 한다.
에이징 커브 -전년도 데이터를 해서 하는 것
최근에 얼마 사용했는지에 따라 가중치를 준다.
휴대폰이 2년 100시간 최근에는 2시간
python문법 ->데이터 가공 numpy pandas ->
sklearn
회귀 군집 알고리즘 등