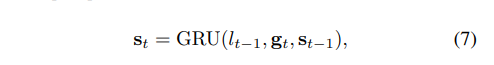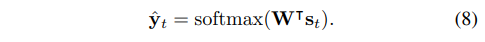CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
https://arxiv.org/abs/2111.11011
CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
The attention-based encoder-decoder framework is becoming popular in scene text recognition, largely due to its superiority in integrating recognition clues from both visual and semantic domains. However, recent studies show the two clues might be misalign
arxiv.org
Abstract
attention-based encoder-decoder framework는 scene text recognition에서 인기가 있는 이유는 visual and semantic domains으로 부터 recognition clues(힌트)를 통합하는데 있어서 성능이 우월하다. ⇒ scene text recognition 의 trend이다.
하지만 최근의 연구는 visual and semantic 양쪽의 clues가 특히 어려운 text에서 서로 잘 연결이 안되고 그것을 완화하기 위해서 character position constraints 을 소개한다. ⇒ 한계점
어떤한 성공에도 불구하고 의미 있는 지역적인 image regions와 a content-free positional embedding은 거의 안정적으로 연결되지 않는다.
이 논문은 visual and semantic related position encoding 새로운 모듈을 소개 ⇒ Multi-Domain Character Distance Perception (MDCDP)이라고 하는 모듈
MDCDP는 attention mechanism에 따라 visual and semantic features 두개 다 query로 사용하기 위해 positional embedding을 사용한다.
visual and semantic distances 를 모두 설명하는 positional clue를 자연스럽게 encoding한다.
우리는 새로운 architecture CDistNet이라고 하고 MDCDP를 여러개 쌓은 것 이며 좀 더 정확한 distance modeling이 가능하다.
따라서 다양한 어려움이 제시되더라도 visual-semantic alignment 이 잘 구축된다.
two augmented datasets and six public benchmarks
시각화는 또한 CDistNet이 visual and semantic domains 모두 에서 적절한 attention localization를 달성함을 보여준다.
소스코드 위치 : https://github.com/ simplify23/CDistNet. 소스코드는 초반에 없었는데 공개되였다.
1. Introduction
최근 몇년 동안 엄청나는 많은 연구가 수행되었음에도 Scene text recognition은 여러가지 문제에 직면해있다. 예를 들어, complex text deformations, unequally distributed characters, cluttered background, etc. ⇒ key issue
최근에는 attention-based encoder-decoder methods가 이 task에서 인상적인 영향을 보여왔다.
하지만 최근 연구[38]에서 는 두가지 잘못 인식된 예와 같이 흔치 않는 정형화 되지 않는 text에서 mismatch가 쉽게 일어난다. Fig.1 (a)참조 .
선행 연구에서 mismatch 발생한 원인
1). visual clue가 약할 때 visual counterpart에 대해서 semantic clue가 제대로 찾지 못한다.
2). 길이가 long text에서 많이 일어난다. text 길이가 길면 semantic feature가 점점 강화되면서 완전히 압도가 된다.
⇒ attention drift
위의 문제로 , mismatch를 완화하기 위하여 character position을 사용하여 연구를 진행한다 . sinusoidal-like positional embedding [6,29] or others [35,43,44]으로 encoding하였다.
이런 전략으로 문제는 좀 해결할 수 있으지만 [29, 44]여기에서는 content-free positional embedding을 사용하였기 때문에 visual feature가 character position하고 안정적으로 연관짓기가 어려웠다. 게다가 이미지 위치에 대한 character position에 대한 위치도 정해놓지 못하고 content-free positional embedding이 오히려 position order에 대한 제약만 주었다.
content-aware receptor를 해서 인식하는 것이 아니라 position order에 대한 제안만 주었다.
게다가 position and semantic space 관계는 아예 무시를 해버린다.

이 논문에서는 앞에서 언급된 이슈들을 극복하기 위해서 Multi Domain Character Distance Perception (MDCDP) 이라고 하는 새로운 module을 개발하였다.
기존의 연구 [34, 44] 와 유사하게 fixed positional embedding이 초기화 된다.
하지만 다른 점은 encoder가 position embedding하고 나서 그리고 visual and semantic features가 self-attention enhancement를 걸친다. 그리고 나서 비로서 query vector로 사용이 된다.
two enhanced features가 일종의 visual and semantic distance-aware representation 이 된다.
이전 정보 가 다음 MDCDP의 query vector로 들어간다. 그렇게 하면 좀 더 attention-focused visual-semantic alignment 가 얻어진다.
이런 idea를 따라서 CDistNet이라는 architecture를 제안한다.
여러개 MDCDP가 쌓인 것이고 정확한 distance modeling이 가능하도록 한다.
이렇게 하면 complex character이 spatial layouts 이 인식하는데 도움이 된다.

(b) HA-IC13 and CA-IC13 datasets are created by horizontal and curved stretching ICDAR2013 with various scales.

(c) We develop CDistNet that perceives multi-domain character distance better by position-related joint encoding. Compared with baseline, the accuracy margin becomes larger as the deformation severity rises.
3가지 기여도가 이다.
- MDCDP visual and semantic features모두 positional feature 를 사용 할 수 있게 만든다.
- CDistNet stacks several MDCDP 어려운 text를 recognizing하는데 이점이 있다.
- we carry out extensive experiments with different configurations and compare CDistNet with existing methods.
2. Related Work
2.1. Semantic-free Methods
RNN and CTC loss
semantic정보를 무시 하고
visual feature만 가지고 modeling한다.
2.2. Semantic-Enhanced Methods
visual feature을 강화하기 위해 semantic clue를 활용하고 attention framework와 함께 encoder decoder를 사용하는 것을 강조
Transformer [34], a powerful model in capturing global spatial dependence, many variants [23, 29, 37] were developed with improved accuracy.
semantic loss를 도입한 것도 있고
semantic feature를 사용하는데 visual feature를 강화하는
ABINet은 별도의 language model을 사용하고 나중에 합쳐서 사용
하지만 misalignment문제가 여전히 남아 있고 attention drift
2.3. Position-Enhanced Methods
position도 고려하겠다.
character position encoding to ease the recognition
advanced rectification models 개발하였지만 , rectification 자체로는 서로 different clues에서 synergistic사용하는데 실패하였다.
Transformer-based models attention mechanism was non-local global하게 한다.
sinusoidal positional embedding
learnable embedding
segmentation map : ensure that characters
RobustScanner [44] proposed a position enhancement branch along with a dynamical fusion mechanism and achieved impressive results.
RobustScanner content-free positional embedding that hardly built a stable correspondence between positions and local image regions
CDistNet에서는 positional embedding을 visual and semantic features 양족에다 주입해서 multi-domain distance aware modeling 수립
3. Methodology

end-to-end trainable network
attention-based encoder-decoder framework
encoder : three branches : encoding visual, positional and semantic information
decoder : three kinds of information are fused by a dedicated designed MDCDP module, positional branch is leveraged to reinforce both visual and semantic branches and generate a new hybrid distance-aware positional embedding.
The generated embedding, which records the relationship among characters in both visual and semantic domains, is used as the positional embedding of the next MDCDP. (다음 MDCDP input으로 사용)
It is thus conducive to generating a attention-focused visual-semantic alignment.
The MDCDP module is stacked several times in CDistNet to achieve a more precise distance modeling.
At last, characters are decoded sequentially based on the output of the last MDCDP module.
마지막 MDCDP module의 output이 문자를 순차적으로 decoding된다.
3.1. Encoder
Visual Branch. TPS를 사용해서 rectify 을 먼저 한다.
Backbone : ResNet-45 and Transformer units , both local and global spatial dependencies를 captures 한다.
ResNet45
Transformer units are three-layer self-attention encoders with 1024 hidden units per layer

T : TPS block
R represents ResNet-45, ResNet-45 downsamples both the width and height to 1/8 of the original size
τ is the Transformer unit
Semantic Branch.
previously seen characters during training
이전에 decode된 character들이 input으로 들어간다.
test 단계에서, 이전에 decode된 character들은 각 time step에서 update되는 current semantic feature으로 encode된다.
Embedding of the start token is used when decoding the first character.
L을 decoding할려고 하면 input은 없으면 안되서 start token으로 한다.
Positional Branch.
text의 문자 위치를 endode한다.
먼저 one-hot vector로 만든다. → same sinusoidal positional embedding
3.2. MDCDP
MDCDP module is formulated on the decoder side and benefit the recognition
3가지 parts로 구성이 되여있다.
self-attention enhancement for positional feature reinforcement
cross-branch interaction that utilizes positional feature to query both the visual and semantic branches, obtaining positional-enhanced representations
dynamic shared fusion to get a visual and semantic joint embedding
Self-Attention Enhancement (SAE)
encoder에서 positional embedding을 주면 SAE 가지고 embedding을 강화한다. multi-head self-attention block한개인 vanilla Transformer에서 다 빼고 하나인 것을 하고 self-attention을 한다.
dimension도 줄였다.

이 방식은 upper triangular mask 이고
반대로 된 것은 lower triangular mask이다.
np.triu() ⇒ upper triangular mask : mask is applied to the query vector of the self-attention block to prevent from ”seeing itself”, or saying, leaking information across time steps. 다음 정보는 보면 안된다.
np.tril() ⇒ lowertriangular mask
RobustScanner내용

before using the positional embedding to query the visual feature 이러한 enhancement 는 사용하지 않는다. The query vector is always fixed in different character sequences. 바뀐 것이 없다.
반면에 , our enhancement enables a more targeted positional embedding learning.
Cross-Branch Interaction (CBI)
positional embedding is treated as the query vector
visual and semantic branches in parallel
When applying to the visual branch, it uses previous decoded character locations to search the position of the next character in the text image. CBI-V
While applying to the semantic branch, it models the semantic affinities between previous decoded characters and current positional clue. CBI-S.
Both branches have been reinforced after the interactions.
A similar upper triangular mask is also applied to the semantic branch to prevent information leaks due to its dynamical update nature.
이전 연구에서는 semantic feature가 query 로 들어가고
RobustScanner position에서 추가적인 query를 visual 쪽에 다 query를 얻은 것이다. position to visual and enables a positional-enhanced decoding.
하지만 , 우리는 semantic branch는 그대로 둔다. 대조적으로, we formulate the interactions as the positional-based intermediate enhancement to both visual and semantic domains. It reinforces not only visual but also semantic features and can be understood as delineating the multi-domain character distance.
Dynamic Shared Fusion (DSF).


two positional-enhanced features as input
visual 과 semantic
channel방향으로 concatenated 해서 하는데 channel이 2배가 된 hybrid feature가 된다.
→ 그 다음 다시 1 × 1 convolution 을 해서 절반으로 줄인다.
→ 그 다음 gating mechanism을 사용 transformed weight matrices
→ both visual and semantic features element-wisely
→ dynamic fusion
ABINet
channel이 2C였다가 C로 줄어든다.
특이한 점은 the weights are shared among different MDCDP modules. As a consequence, DSF not only decouples the feature fusion with the previous attention learning, but also eases the network modeling.
4. Experiments
4.1. Datasets
three kinds of datasets :
two synthetic datasets for model training MJSynth (MJ) [10] and SynthText (ST) [7]
데이터 셋 sample
https://arxiv.org/pdf/1904.01906.pdf
two augmented datasets for model verification

HA-IC13 and CA-IC13 two augmented datasets created from ICDAR2013
simulate the horizontal (HAIC13) and curved (CA-IC13) stretching with scales from 1 (the smallest deformation) to 6 (the largest deformation) with interval of 1 using the data augmentation tool in [21]
postprocessing exception 것을 처리 하기 위한 것
6배 정도 많다.
six widely used public datasets for both ablation study and comparison with existing methods.
ICDAR2013 (IC13) [13], Street View Text (SVT) [36], IIIT5k-Words (IIIT5k) [24], ICDAR2015 (IC15) [12], SVT-Perspective (SVTP) [26] and CUTE80 (CUTE) [28]
The first three mainly contain regular text while the rest three are irregular.
4.2. Implementation details

We resize the input images to 32×128 and employ data augmentation such as image quality deterioration, color jitter and geometry transformation.
Transformer 확인
transformer의 learning rate와 같다.
To reduce the computational cost, we shrink the transformer units employed, where dimension of the MLP layer is reduced from 2048 to 1024 in encoder, and from 2048 to 512 in decoder.
beam search
4.3. Ablation study




The number of MDCDP modules considered.
layer를 많이 쌓으면 쌓을 수록 computational cost가 증가한다.
Therefore the MDCDP modules in CDistNet are empirically set to 3.
The effectiveness of SAE.
self attention enhancement는 position branch 에 사용
The effectiveness of CBI.
The result basically validates two hypotheses.
First, imposing the positional clue is helpful.
Second, it is effective to query the semantic feature by using the positional clue, which perceives the semantic affinities between previous decoded characters and current position.
The effectiveness of DSF.
DSF outperforms static-based fusions (Add and Dot) as well as the scheme that not sharing weights among MDCDP modules.
4.4. Model Verification
Contribution of the positional utilization.

We first explain how the methods are modified.
CDistNet w/o Sem
Transformer* visual branch를 강화
RobustScanner* Transformer unit to replace the raw ”CNN+LSTM” implementation
CDistNet
With the modifications above, accuracy

gains from the position modeling can be quantitatively evaluated.
positional utilization이 중요
Performance on augmented datasets.
HAIC13 and CA-IC13 are simulated with different levels of horizontal and curved deformations.
It clearly verifies the advantage of CDistNet in recognizing difficult text.
Decoding Visualization.


attention map based on the positional-enhanced visual branch and give some examples in Fig.6
It again indicates the superiority of the proposed MDCDP module.
semantic affinities between previous decoded characters and current position in Fig.7
Analysis of good and bad cases.
good: we can conclude that CDistNet retains powerful and universal recognition capability with the existence of various difficulties, e.g., diverse text shapes, blur, distortions, etc.
bad : We also list some bad cases in Fig.9. The failures can be summarized as three categories mainly, multiple text fonts (cocacola, quilts), severe blur (coffee) and vertical text (garage). Most of them are even undistinguishable by humans and they are common challenges for modern text recognizers.


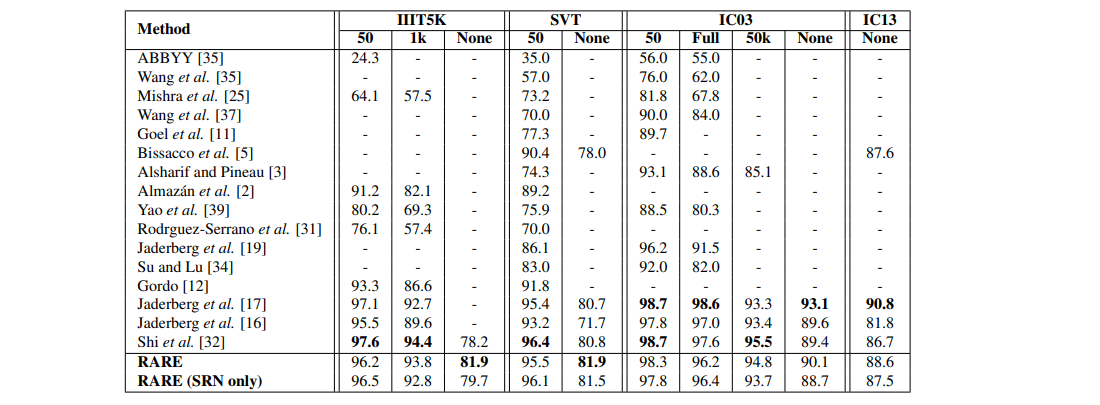
4.5. Comparisons with Existing Methods
five datasets including IC13, SVT, IIIT5K, IC15 and SVT-P when trained based on the two synthetic datasets.
irregular text datasets

5. Conclusion
extreme irregular text, we have presented the MDCDP module which utilizes positional feature to query both visual and semantic features within the attention-based encoder-decoder framework.
both visual and semantic domains.
MDCDP module
eight datasets that successfully validate our proposal.
The result on augmented datasets shows larger accuracy margin is observed as the severity of deformation increases.
ablation studies
state-of-the-art accuracy when compared with existing methods on six standard benchmarks.
In addition, the visualization experiments also basically verify that superior attention localization are obtained in both visual and semantic domains.