논문 출처 :
Robust Scene Text Recognition with Automatic Rectification
Abstract
irregular shapes
perspective distortion : 사진 및 영화 촬영에서 원근 왜곡은 물체와 그 주변 영역이 뒤틀 리거나 변형되어 주변 및 원거리 피처의 상대적 스케일로 인해 일반 초점 거리에서 물체가 어떻게 보일지와 크게 다릅니다. en.wikipedia.org/wiki/Perspective_distortion_(photography)
Perspective distortion (photography) - Wikipedia
Simulation showing how adjusting the angle of view of a camera, while varying the camera distance and keeping the object in frame, results in vastly differing images. At narrow angles and large distances, light rays are nearly parallel, resulting in a "fla
en.wikipedia.org
자연 이미지에서 텍스트를 인식하는 것은 여전히 어려운 작업이며이 논문에서는 불규칙한 텍스트에 대한 강력한 인식 모델 인 RARE(Robust text recognizer with Automatic REctification)를 제안합니다. RARE는 공간 변환 네트워크 STN (Spatial Transformer Network)과 시퀀스 인식 네트워크 SRN (Sequence Recognition Network)을 포함하는 심층 신경망입니다. 두 네트워크는 동시에 BP 알고리즘을 사용하여 훈련됩니다.테스트에서는 먼저 TPS (Thin-Plate-Spline)를 통해 이미지를보다 읽기 쉬운 일반 이미지로 변환합니다.이 변환은 전송 변환 및 곡선 텍스트를 포함하여 다양한 유형의 불규칙한 텍스트를 수정할 수 있습니다.
RARE is end-to-end trainable, requiring only images and associated text labels, making it convenient to train and deploy the model in practical systems.
Thin-Plate-Spline: 박판 스플라인은 데이터 보간 및 스무딩을위한 스플라인 기반 기술입니다.
Thin plate spline 이란 - Google 검색
Principal Warps: Thin-Plate Splines and the Decomposition of Deformations, F.L. Bookstein, PAMI 1989 (Vol. 11, No. 6) pp. 567-585.
www.google.com
Thin Plate Spline(TPS) 원래 점에서 한 점을 였을 때 어떻게 하면 그 점의 curve가 잴 적는가 ?
Introduction
Ideally, the STN produces an image that contains regular text, which is a more appropriate input for the SRN than the original one. The transformation is a thinplate-spline [6] (TPS) transformation, whose nonlinearity allows us to rectify various types of irregular text, including perspective and curved text. The TPS transformation is configured by a set of fiducial points, whose coordinates are regressed by a convolutional neural network.
TPS 변환은 일련의 기준점으로 표시되고 좌표는 컨벌루션 신경망 회귀를 통해 얻습니다. 그런 다음 식별을 위해 SRN에 넣습니다. SRN은 인코더 및 디코더를 포함하여 주의 기반 시퀀스 인식 방법을 사용합니다. 인코더는 특징 표현 시퀀스, 즉 시퀀스의 특징 벡터를 생성하고, 디코더는 입력 시퀀스에 따라 문자 시퀀스를 주기적으로 생성한다. 이 시스템은 end-to-end 텍스트 인식 시스템으로 훈련 과정에서 문자열의 키 포인트와 문자 위치를 추가로 표시 할 필요가 없습니다.
attention based model은 실제로 유사성의 척도입니다. 현재 입력이 목표 상태와 유사할수록 전류 입력의 가중치가 커져 현재 출력이 전류 입력에 더 많이 의존 함을 나타냅니다.
attention는 실제로 전류 입력과 출력 간의 일치 정도입니다.
이 논문의 주요 공헌 :
1) 불규칙한 텍스트에 대한 새롭고 robust scene text recoginition 방법 제안,
2) attention-based model STN 프레임 워크 채택. 기존 STN은 일반 컨볼 루션 신경망에서만 테스트됩니다 .
3) convolutional-recurrent 구조는 SRN 인코더에서 사용됩니다.
3. Proposed Model
모델의 입력은 이미지 I이고 출력은 시퀀스 L =입니다. (L1,…, LT), Lt는 T 번째 문자를 나타내고 T는 시퀀스 길이입니다.
3.1. Spatial Transformer Network
STN은 예측 된 TPS 변환을 사용하여 입력 이미지 I를 수정 된 이미지 I '로 변환합니다. 아래 그림과 같이:

먼저 포지셔닝 네트워크를 통해 참조 점 집합을 예측 한 다음 위의 참조 점을 사용하여 그리드 생성기에서 TPS 변환 매개 변수를 계산하여 I에 대한 샘플링 그리드를 생성합니다. 샘플러는 샘플링 그리드의 포인트를 통해 그리드와 입력 이미지를 결합합니다. 나는 이미지를 가져옵니다. STN은 샘플러가 미분 할 수있는 고유 한 속성을 가지고 있으므로 미분 할 수있는 포지셔닝 네트워크와 미분 할 수있는 그리드 생성기가 있으면 STN은 훈련을 위해 오류를 역 전파 할 수 있습니다.
STN의 장점은 위 모든 연산이 differentiable 한 연산들로 구성되어 각 모듈의 파라미터들이 학습이 가능하다는 점이다.
3.1.1 Localization Network
포지셔닝 네트워크는 x 및 y 좌표를 회귀하여 K 참조 점을 결정합니다. 상수 K는 짝수이고 좌표는 C =로 표시됩니다.

Localization network는 CNN으로 구성되고 출력은 K개의 좌표 값(=2K)에 대한 regression을 수행한다. 출력 노드는 tanh() activation function을 이용하여, (-1,1) 범위로 normalized된 좌표값을 예측하도록 한다.
이 때 중요한 점은 fiducial point에 대한 GT 없이 오직 back-propagation에 의해 학습된 포인트 위치 좌표로 rectification이 수행된다는 점이다.
Robust Scene Text Recognition with Automatic Rectification
Paper Info
www.notion.so
3.1.2 Grid Generator

Grid generator는 예측된 fiducial points로 부터 TPS transform을 위한 파라미터를 측정하여, 샘플링 그리드를 생성한다.
우리는 처음에 또 다른 fiducial points(기준점) 을 정의하는데 것을 base fiduacial points,라고 한다.

샘플링 그리드는 출력 영상(=rectified Image)의 각 화소에서 입력 영상의 어떤 위치의 화소와 매칭이 되는지를 계산하여, 매칭되는 부분의 화소값을 샘플링해 오는 역할을 한다. 출력 영상에서 fiducial point는 항상 이미지의 상단과 하단에 균일하게 분포되도록 설정하기 때문에, 출력 영상의 base fiducial points C'은 constant이다.
그리드 생성기는 TPS 변환의 매개 변수를 평가하고 샘플링 그리드를 생성합니다.
TPS transform의 파라미터는 행렬 T로 표현 된다.
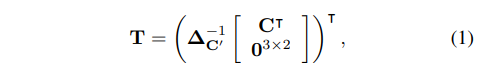


이 때, R'은 두 base fiducal points c'_i, c'_j 간의 euclidean distance로서 contant이고, △C' 는 contant 행렬 C' 와 R'에 의해 결정되므로, 이 또한 constant 이다. (참고로, 행렬 C는 localization network에 의해 예측되는 값이다.)
Rectified 이미지 I'에서의 픽셀 그리드 좌표는 다음과 같이 정의된다.
위 그림 3에서와 같이, Rectified 이미지 I'의 모든 화소에 대한 대응 점 p_i=[x_i,y_i]를 찾기 위해 다음의 변환을 적용한다.
P'의 모든 포인트에 대해 위 변환을 적용하여, 입력 영상 I에 대한, 그리드 P를 생성한다. 참고로, 해당 변환은 두개의 행렬 곱 연산(Eq.1, Eq.4)으로 구성되므로, 미분 가능하다.
3.1.3 Sampler
그중 V는 차별화 가능한 모델 인 bilinear sampler를 의미합니다.
TPS 변환의 유연성을 통해 다음과 같은 효과를 통해 다양한 유형의 불규칙한 텍스트를 규칙적이고 읽기 쉽게 만들 수 있습니다.
위 수식에서 V는 bilinear sampler이고, 이 또한 미분가능한 연산이다. 아래는 학습된 STN의 결과 샘플들이다.


we show some common types of irregular text, including
a) loosely-bounded text, which resulted by imperfect text detection;
b) multi-oriented text, caused by non-horizontal camera views;
c) perspective text, caused by side-view camera angles;
d) curved text, a commonly seen artistic style. The STN is able to rectify images that contain these types of irregular text, making them more readable for the following recognizer.
In our model, the SRN is an attention-based model [4, 8], which directly recognizes a sequence from an input image. The SRN consists of an encoder and a decoder. The encoder extracts a sequential representation from the input image I 0 . The decoder recurrently generates a sequence conditioned on the sequential representation, by decoding the relevant contents it attends to at each step.
기존 Encoder-Decoder RNN/LSTM 모델의 문제점
- 아무리 긴 input sentence가 주어져도 고정 길이 벡터fixed-length vector로 압축해서 표현해야 함
- Decoder는 Encoder의 마지막 은닉상태만 전달받음 → 엄청 긴 문장이라면 엄청 많이 까먹음
- Attention은 Encoder와 Decoder 사이에 있으며, Decoder에게 (Encoder의 마지막 은닉상태뿐만 아니라) Encoder의 (모든) 은닉상태를 전해줌
* Attention의 두 종류 1) global attention 2) local attention
1) global attention : Encoder의 모든 은닉상태를 Decoder에 전해줌
2) local attention : Encoder의 일부 은닉상태를 Decoder에 전해줌
Attention Model 번역 및 정리
출처 1) Neural Machine Translation By Jointly Learning to Align and Translate 2) Attention: Illustrated Attention 3) Attention and Memory in Deep Learning and NLP 기존 Encoder-Decoder RNN/LSTM 모델..
codlingual.tistory.com
www.jianshu.com/p/27efdd561897
基于TPS的STN模块-Robust Scene Text Recognition with Automatic Rectification
基于TPS的STN模块-Robust Scene Text Recognition with Automatic Rectification TPS:薄板样条插值(Thin ...
www.jianshu.com
localization network: TPS 보정에 필요한 K 기준점 예측(fiducial point)
Grid Generator:기준점을 기반으로 TPS 변환을 수행하여 Feature map을 출력하는 샘플링 창을 생성합니다.(Grid)
Sampler:각 그리드에 대해 쌍 선형 보간 수행
3.2. Sequence Recognition Network
SRN은 인코더와 디코더를 포함하여 입력 이미지에서 시퀀스를 직접 식별 할 수있는주의 기반 모델입니다. 인코더는 입력 이미지 I '에서 특성 시퀀스 표현을 추출하고, 디코더는 각 단계에서 관련 콘텐츠를 디코딩하여 시퀀스 표현에 따라 조정 된 시퀀스를 주기적으로 생성합니다.
3.2.1 Encoder: Convolutional-Recurrent Network
컨볼 루션 레이어와 반복 네트워크를 결합하여 특징 벡터를 추출하는 구조를 구축했으며 입력 이미지 크기는 임의적 일 수 있습니다.

convolutional layers와 recurrent network를 combine 한다.
encoder 아래쪽에는 여러개의 convolutional layers가 있다. => feature maps를 생산하며 robust and high - level descriptions of an input image.
가설 : feature map D conv (depth ) x H conv(height) x W conv(width)
그 다음에는 maps 를 sequence 에 변하게 한다. Wconv vecotrs , each has D conv W conv 차원
Specifically, the “map-to-sequence” operation takes out the columns of the maps in the left-to-right order, and flattens them into vectors. According to the translation invariance property of CNN, each vector corresponds to a local image region, i.e. receptive field, and is a descriptor for that region.
two-layer Bidirectional Long -Short Term Memory(BLSTM)
BLSTM은 양방향 시퀀스의 독립성을 분석 할 수있는 순환 네트워크로, 출력은 입력 값과 크기와 길이가 동일한 또 다른 시퀀스이고,h = (h1, . . . , hL), L은 특성 맵의 너비입니다.
3.2.2 Decoder: Recurrent Character Generator
디코더는 인코더에 의해 생성 된 시퀀스를 기반으로 일련의 문자 시퀀스를 생성하며 루프 부분에서는 GRU (Gated Recurrent Unit)를 cell로 사용합니다.

st−1 is the state variable of the GRU cell at the last step. For t = 1, both s0 and α0 are zero vectors.

Since αt has non-negative values that sum to one, it effectively controls where the decoder focuses on.
The state st−1 is updated via the recurrent process of GRU [7, 8]:
st-1은 GRU주기 프로세스를 통해 업데이트됩니다.
Lt-1은 훈련에서 t-1 번째 실제 레이블을 나타냅니다.
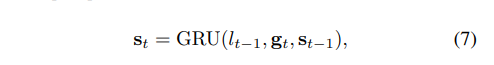
확률 분포 함수는 다음과 같습니다.
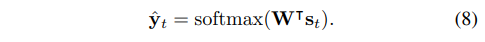
The label space includes all English alphanumeric characters, plus a special “end-of-sequence” (EOS) token, which ends the generation process. => 영어 알파벳
The SRN directly maps a input sequence to another sequence. Both input and output sequences may have arbitrary lengths. It can be trained with only word images and associated text.
3.3. Model Training
training set :

, we minimize the negative log-likelihood over X :

where the probability p(·) is computed by Eq. 8, θ is the parameters of both STN and SRN.
optimization : ADADELTA [41] : we find fast in convergence speed.
- 스텝 사이즈도 가중치의 누적 변화에 따라 감소
datascienceschool.net/view-notebook/ba1f343cbe134837959f5c1c4fd98406/
Data Science School
Data Science School is an open space!
datascienceschool.net

모델 파라미터는 localization network의 fully-connected layers의 가중치 0을 설정하는 것 제외하고 randomly initialized되며, 편차는 위의 그림 a와 같은 형태로 초기화됩니다. 경험에 따르면 b와 c의 초기화 효과가 상대적으로 낮습니다. 그러나 포지셔닝 네트워크의 매개 변수를 임의로 초기화하면 결과가 수렴되지 않습니다.
3.4. Recognizing With a Lexicon
단어를 인식하기 위해 사후 조건부 확률을 사용합니다. 50 k words 효율성있게 이 큰 사전을 죄회해야 한다.

사전 집합을 줄이기 위해 접두사 트리는 다음과 같이 구성됩니다.

tree를 만들어서 한다.
Recognition performance could be further improved by incorporating beam search.
Larger beam width usually resultbeam searchs in better performance, but lower search speed.
beam search : 자연어처리 조회하는 기법이다.
그리디 탐색에서 확장된 빔 탐색이 많이 사용한다. 이것은 가장 높은 확률을 시퀀스를 반환한다.
빔 탐색은 모든 가능한 다음 스텝들로 확장하고, 가 사용자 지정 파라미터 이고, 빔의 숫자 또는 확률 시퀀스에서 병렬 탐색들을 조절가능한 곳에서 가능한 를 유지하려고 한다.
그리디 탐색의 경우 빔이 1인 탐색과 같다. 빔의 수는 일반적으로 5 또는 10을 사용하고, 빔이 클수록 타겟 시퀀스가 맞을 확률이 높지만 디코딩 속도가 떨어지게 된다.
velog.io/@nawnoes/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-Beam-Search
자연어처리 Beam Search
텍스트 생성 문제에 대해서 Greedy Search와 Beam Search을 어떻게 사용하는지 How to Implement a Beam Search Decoder for Natural Language Processing블로그를 보고 정리캡션 생성, 요약, 기계 번역은
velog.io
이오스는 위임지분증명 방식을 사용하는 제3세대 암호화폐이다. 이오스의 화폐 단위는 EOS이다.
ko.wikipedia.org/wiki/%EC%9D%B4%EC%98%A4%EC%8A%A4
이오스 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 이오스(EOS.IO)는 위임지분증명(DPoS) 방식을 사용하는 제3세대 암호화폐이다. 이오스의 화폐 단위는 EOS이다. 2017년 댄 라리머가 이더리움 기반으로 개발했고, 2018�
ko.wikipedia.org
4. Experiments
recognition benchmarkets on irregular text
First we evaluate our model on some general recognition benchmarks, which mainly consist of regular text, but irregular text also exists.
Next, we perform evaluations on benchmarks that are specially designed for irregular text recognition. For all benchmarks, performance is measured by word accuracy.
4.1. Implementation Details
Spatial Transformer Network:
STN의 localization network는 4 개의 convolution layers, 각 2 × 2 max-pooling layer가 있다.
all convolutional layers
filter size : 3 , padding size : 1, stride : 1
filters are respectively 64, 128, 256 and 512
Following the convolutional and the max-pooling layers is two fully-connected layers with 1024 hidden units.
fiducial points K = 20, meaning that the localization network outputs a 40-dimensional vector
activation function : ReLU [27] output layer tanh(·). 을 제외하고
Sequence Recognition Network:
encoder has 7 convolutional layers, whose {filter size, number of filters, stride, padding size} are respectively {3,64,1,1}, {3,128,1,1}, {3,256,1,1}, {3,256,1,1,}, {3,512,1,1}, {3,512,1,1}, and {2,512,1,0}.
The 1st, 2nd, 4th, 6th convolutional layers are each followed by a 2 × 2 max-pooling layer
On the top of the convolutional layers is a two-layer BLSTM network, each LSTM has 256 hidden units.
decoder:
we use a GRU cell that has 256 memory blocks and 37 output units (26 letters, 10 digits, and 1 EOS token).
Model Training
8 백만 개의 합성 샘플, 배치 크기 = 64, [17, 16]에 따라 이미지 크기는 100x32, STN의 출력 이미지 크기도 100x32입니다.
Implementation => gpu
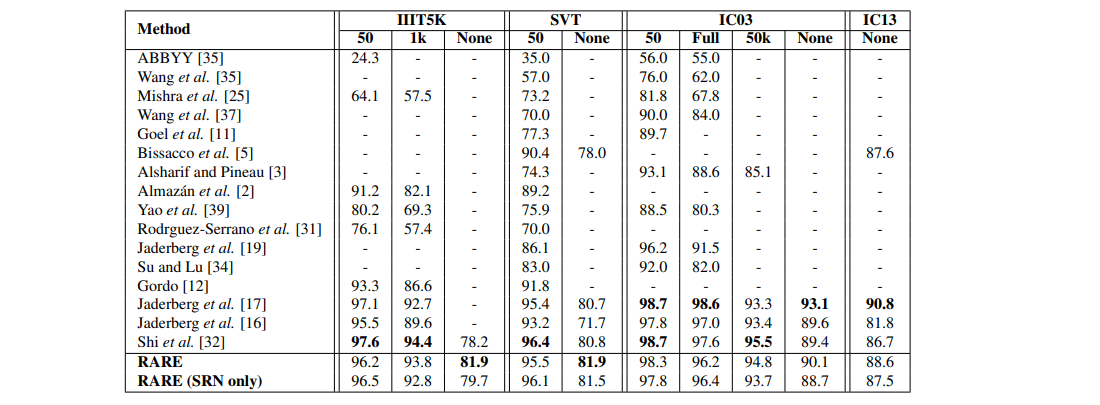
4.2. Results on General Benchmarks
• IIIT 5K-Words [25] (IIIT5K)
• Street View Text [35] (SVT)
• ICDAR 2003 [24] (IC03)
• ICDAR 2013 [20] (IC13)
4.3. Recognizing Perspective Text

SVT-Perspective [29] is specifically designed for evaluating performance of perspective text recognition algorithms.


We use the same model trained on the synthetic dataset without fine-tuning. For comparison, we test the CRNN model [32] on SVT-Perspective. We also compare RARE with [35, 25, 37, 29], whose recognition accuracies are reported in [29].

4.4. Recognizing Curved Text

5. Conclusion
irregular text problem =>scene text recognition에서의 어려운 문제
불규칙한 텍스트 인식을 해결하기 위해 차별화 가능한 공간 변환기 네트워크(spatial transformer network를 사용하고,주의 학습 attention-based sequence 인식과 결합하여 전체 모델을 end-to-end 인식 할 수 있습니다.
실험 결과 :
1) 이 모델은 geometric supervision없이 더 가독성이 높은 이미지를 자동으로 생성 할 수 있습니다 .
2) 본 논문에서 제안한 이미지 보정 모델은 인식의 정확도를 향상시킬 수 있습니다 .
3) 본 논문에서 제안한 인식 시스템과 현재의 방법 보다 더 나은 결과를 가진다.
In the future, we plan to address the end-toend scene text reading problem through the combination of RARE with a scene text detection method, e.g. [43].
STN먼저 소계하고
SRN : encoder decoder