논문 :
[OCR]Spatial Transformer Networks
2015, NIPS
Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu
Google DeepMind
cnn으로 만족시키지 못한 것을 stn으로 한다.
3가지 절차가 있다.
Localisation net: U -> parameter matrix
Grid generator: 에 -> sampling grid Tθ(G)를 계산
Sample:
이 논문의 저자들은, CNN (Convolutional Neural Network)이 spatially invariant하지 못한 점이 근본적인 한계라고 주장합니다.CNN의 max-pooling layer가 그런 점을 다소 만족시켜 주기는 하지만, 2×2 픽셀 단위의 연산으로는 데이터의 다양한 spatial variability에 대처하기 어렵다는 것입니다. 여기서 말하는 spatial variability란 scale (크기 변화), rotation (회전), translation (위치 이동)과 같은 공간적 변화를 의미한다고 보시면 되겠습니다.
이를 해결하기 위해 이 논문에서는 기존 CNN에 끼워 넣을 수 있는 Spatial Transformer라는 새로운 모듈을 제안합니다.
non-rigid deformations
end-to-end training
end-to-end 딥러닝은 자료처리 시스템 / 학습시스템에서 여러 단계의 필요한 처리과정을 한번에 처리합니다. 즉, 데이터만 입력하고 원하는 목적을 학습시키는 것입니다.
www.edwith.org/deeplearningai3/lecture/34893/
[LECTURE] End-to-End Deep Learning 은 무엇인가요? : edwith
학습목표 end-to-end 딥러닝을 학습한다. 핵심키워드 end-to-end 딥러닝 파이프라인 (pipline) - 커넥트재단
www.edwith.org
Spatial Transformer의 개념
Spatial transformer란, 기존의 neural network architecture에 집어넣어 아래 그림과 같이 spatial transformation 기능을 동적으로 제공하는 모듈입니다.

Localisation net: input feature map U에 적용할 transform의 parameter matrix θ를 추정합니다.
Grid generator: 에 따라 input feature map에서 sampling할 지점의 위치를 정해주는 sampling grid Tθ(G)를 계산합니다.
Sample:
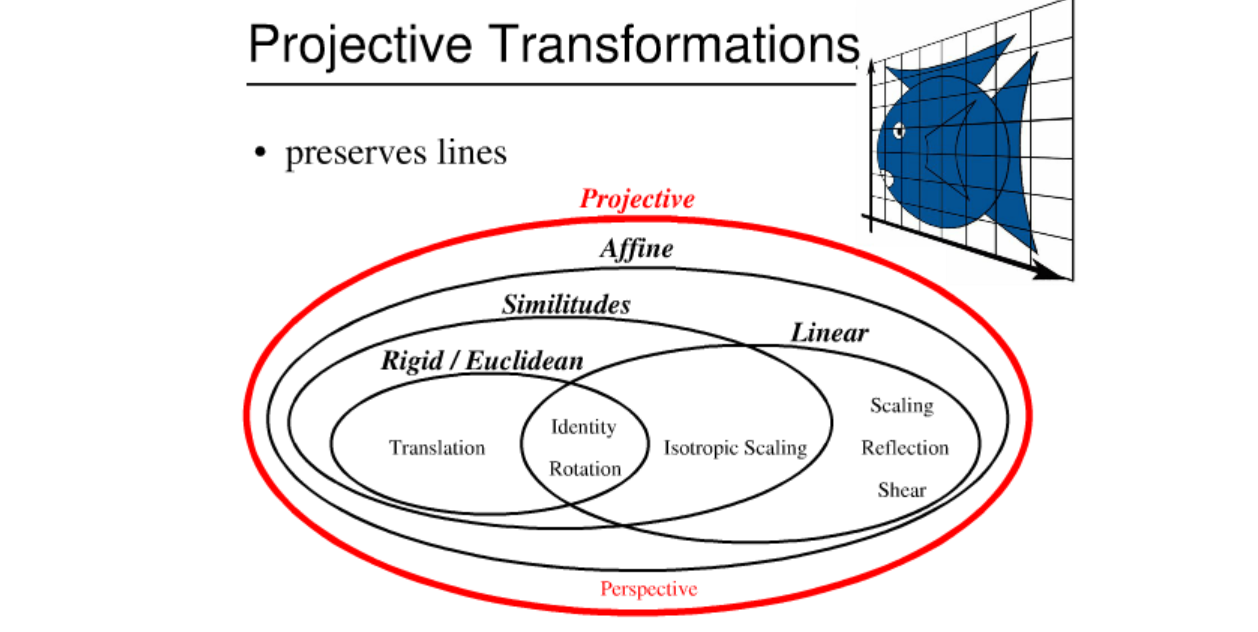
Projective Transformation(원근변환)
이것은 선만 보존되는 변환이다. 각도도 바뀐다. 단지 선의 성질은 보존되어 곡선으로 되지는 않는다.
이 변환은 원근감을 표현하기 위해 필요한 변환이며, 입체를 평면이 투영할때도 꼭 필요한 변환이다.
[영상처리] 일지 16: Transformations -- 기본적이며 전반적 이해를 위해
일지 16 : Transformations(변환) 아무 개념없이 이미지의 이동/ 회전/ 확대를 앞 일지에서 하였다. 그러다가 원근변환을 해야하는 일이 있어 공부해보니 이 모든 것이 다 변환이었다. 그래서 영상처리
blog.daum.net
근데 원근법에 의해서 멀리있는 기둥은 짧아 보이고 가까이 있는 기둥은 길어 보여서 마치 화면의 중심점으로 소실되어 가는 것처럼 보이죠.
이게 바로 원근변환입니다
5.2.4. Affine Transformations
선형변환에서 이동변환까지 포함하여 Affine변환이라고 한다. 여기에서는 변환전 물체의 속성중에서 서로 평형한 선은 Affine변환후에도 역시 평형하다는 것이 특징이다. 따라서 Shear도 Affine변환이다.

위의 그림에서 보듯이 평형사변형을 Affine변환시키면 역시나 평형사변형이 된다. 만약 평형사변형을 perspective(원근변환)시키면 사다리꼴이 되어 서로 평형했던 선이 더 이상 평형관계에 있지 않게 된다.
image classification은 이미지가 개에 관한 것인지, 고양이에 관한 것인지, 사람에 관한 것인지, 자동차에 관한 것인지 분류하는 컴퓨터 비전 과제다. 그렇다면 fine-grained image classification은 무엇일까? 새의 종, 꽃의 종, 동물의 종 또는 자동차의 모델 같이 구분하기 어려운 클래스들을 분류하는 과제다.
image classification의 대표 데이터셋이 이미지넷(ImageNet)이라면, fine-grained image classfication에 자주 사용되는 데이터셋에는 CUB-200-2011, Stanford Cars, Stanford Dogs 등이 있다. CUB-200-2011은 200개의 클래스를 포함하고, 5994개의 훈련셋과 5794개의 테스트셋으로 구성되어 있다. Standford Cars는 196개의 클래스, 8144개의 훈련셋, 8041개의 테스트셋을 제공한다. Stanford Dogs의 경우에는 120개 클래스, 12000개 훈련셋, 8580개 테스트셋을 갖는다.
Coarse-grained 의 사전적 정의는 "결이 거친", "조잡한" 입니다. 곡식을 낱알로 분리하는 작업을 "grain" 이라고 할 수 있는데, 이를 거칠고 큼직큼직하게 할지, 곱고 세밀하게 할지에 따라서 Coarse 와 Fine 으로 나누어 표현한다고 이해할 수 있습니다.
Coarse-grained classification 은 Cifar10, Cifar100, MNIST 등의 데이터셋을 사용해 classification 하는 것이 Coarse-grained classification 의 예시입니다.
Fine-grained classification 은 Coarse-grained classification 보다 더 세밀하게 classification 을 한다고 이해할 수 있습니다. Stanford dogs 가 가장 유명한 Fine-grained classification dataset 인데, 아래 이미지를 보시면 "개" 라는 동물종 안에서 더 세세하게 "개의 품종"을 classification 하기 위한 데이터셋임을 알 수 있습니다. Fine-grained classification 은 Coarse-grained classification 보다 상대적으로 비슷한 특징을 가진 classs 들을 분류하는 것이라고 이해할 수 있습니다.
출처: https://light-tree.tistory.com/215 [All about]
image classification과 fine-grained image classification의 차이
image classification은 이미지가 개에 관한 것인지, 고양이에 관한 것인지, 사람에 관한 것인지, 자동차에 관한 것인지 분류하는 컴퓨터 비전 과제다. 그렇다면 fine-grained image classification은 무엇일까?.
bskyvision.com
딥러닝 용어 정리, Coarse-grained classification과 Fine-grained classification의 차이와 이해
이 글은 제가 공부한 것을 정리한 글입니다. 잘못된 내용이 있다면 댓글로 지적 부탁드립니다. 감사합니다. Coarse-grained classification 과 Fine-grained classification 의 차이 Coarse-grained 의 사전적 정..
light-tree.tistory.com
참조 :
jamiekang.github.io/2017/05/27/spatial-transformer-networks/
Spatial Transformer Networks · Pull Requests to Tomorrow
Spatial Transformer Networks 26 May 2017 | PR12, Paper, Machine Learning, CNN 이번 논문은 Google DeepMind에서 2015년 NIPS에 발표한 “Spatial Transformer Networks”입니다. 이 논문의 저자들은, CNN (Convolutional Neural Network)이 sp
jamiekang.github.io