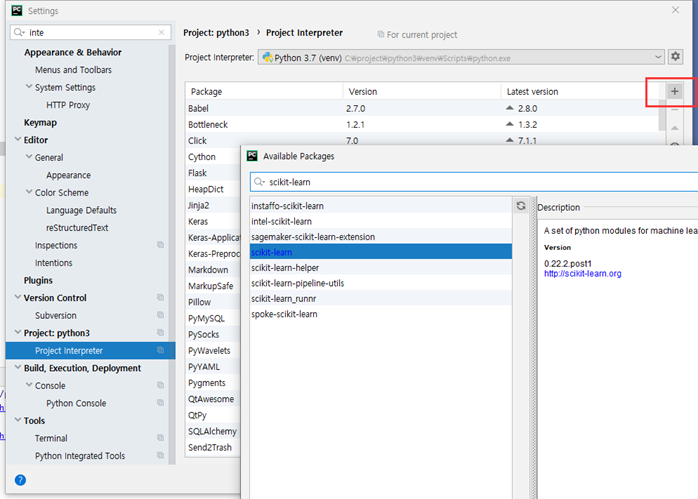
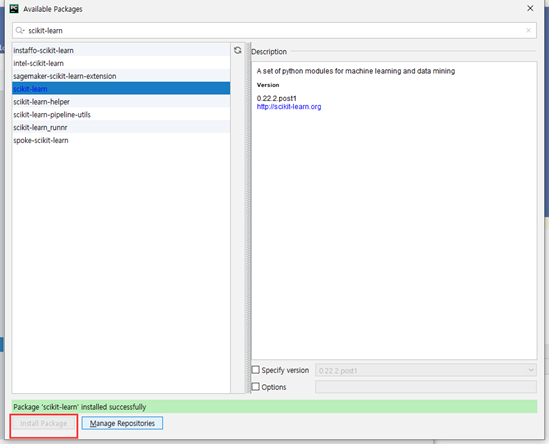
keras 모델 학습
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
np.random.seed(1234) # 실행핛 때마다 같은 결과를 출력하기 위해 설정하는 부분
# 학습 데이터
x_train = [1, 2, 3, 4]
y_train = [2, 4, 6, 8]
#학습 모델 생성
model = Sequential()
model.add(Dense(1, input_dim=1)) #출력 층을 만든다.
# 출력 node 1개 입력 node 1개
#1개의 층을 받아서 1개 출력한다.
#모델 학습 방법 설정
#model.compile(loss ='mse',optimizer='adam' , metrics=['accuracy'])
model.compile(loss ='mse',optimizer= optimizers.Adam(learning_rate=0.001), metrics=['accuracy'])
# learning_rate 크면 발산 작으면 확률이 떨어진다.
#오차가 줄어들면 정확도가 증가된다.
#loss post 손실
#mse 평균제급곤오류
#optimizer: 경사 하강법 사용하는뎅 adam으로 사용
#adam learning rate 자동으로 설정된다.
#모델 학습
model.fit(x_train, y_train, epochs=20000) # # 20000번 학습 학습의 수가 적으면 오차가 크게 나온다.
#모델을 이용해서 예측
y_predict = model.predict(np.array([1,2,3,4]))
print(y_predict)
# 모델을 이용해서 예측
y_predict = model.predict(np.array([7,8,9,100]))
print(y_predict)
keras의 대표적인 오차함수(cost function)
오차 값에 따라 손실이 차이가 난다.
평균제곱계열 -> 예측 보통 mse잘 사용하한다.
교차엔트로피계열 분류
다중분류 softmax 사용
모델 정의
모델 정의
model = Sequential()
- keras에서 모델을 만들때는 Sequential()함수를 사용함
은닉층
model.add(Dense(30, input_dim=17, activation='relu'))
- model에 새로운 층을 추가핛때는 add()함수를 사용함
- model에 추가된 각 층은 Dense()함수를 통해서 구체적인 구조를 설정핚다.
- 출력node 30개, 입력 데이터 17개, 홗성화 함수는 relu 함수를 사용함
- 첫번째 Dense()가 입력층 + 은닉층 역핛을 핚다.
출력층
model.add(Dense(1, activation='sigmoid'))
- 출력층에서 홗성화 함수는 sigmoid함수를 사용해서 폐암홖자의 생존유무를 결정핚다. ( 1 or 0 )
모델 학습과정 설정 및 모델 학습
모델 학습과정 설정
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
- 오차함수는 평균제곱오차(mean_squared_error) 사용
- 최적화 방법(optimizer)는 adam 사용
- metrics=[‘accuracy’]는 모델이 컴파일될 때 모델의 정확도(accuracy)를 출력
모델학습
model.fit(X, Y, epochs=30, batch_size=10)
- 학습 프로세스가 모든 샘플에 대해 핚번 실행하는 것을 1 epoch(에포크)라고 핚다.
- epochs=30 은 각 샘플을 처음 부터 끝까지(470개) 30번 반복 실행핚다는 의미
- batch_size=10 은 전체 470개의 샘플을 10개씩 끊어서 학습하라는 의미
sigmoid 2중적인 분류를 할 때 가장 적합한 함수
relu 함수
기울기 급증 할 수 있어서 relu를 사용한다.
#폐암 수술 환자의 생존을 예측하기
# 필요핚 라이브러리를 불러옴
import numpy
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 실행핛 때마다 같은 결과를 출력하기 위해 설정하는 부분
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
# 준비된 수술 홖자 데이터를 불러옴
dataset = numpy.loadtxt("dataset/ThoraricSurgery.csv", delimiter=",")
X = dataset[:, 0:17] # 행 열
Y = dataset[:,17] # 17번 : 홖자들의 생존유무 (0 or 1)
# 모델을 설정
model = Sequential() # 모델 정의
model.add(Dense(30, input_dim=17, activation='relu')) # 은닉층 : 출력node 30개, 입력데이터 17개
#입력층 은닉층 동일하다.
#은닉층은 일정자격이 와야만 다음층에 지나간다.
#출력노드의 개수는 임의의 개수이다.
model.add(Dense(1, activation='sigmoid')) # 출력층 : 입력node 30개, 출력 node 1개
# 모델 학습과정 설정 및 모델 학습
# 젂체 데이터 470개를 10개씩 끊어서, 30번 학습함
#mean_squared_error mse 상관 없다.
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
# 420개를 10개씩 나누어서 학습 시키라
model.fit(X, Y, epochs=30, batch_size=10) # 모델 학습
# 모델 평가 : 정확도
ac = model.evaluate(X, Y)
print(type(ac))
print(ac)
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
필요할 떄마다 은닉층 추가할 수 있다.
선형회귀(Linear Regression)
상관관계를 선(=회귀선)을 그어서 모델(=가설)로 지정하였습니다
최소 제곱법(Least-squares)
평균 제곱근 오차 (Root Mean Squared Error : RMSE) : 오차 = 실제 값 – 예측 값
마치 경사를 타고 내리온 방향으로
로스값이 최소가 되는 방향으로 학습 한다.
로스값이 작은 것은 학습이 잘 됬다.
비용함수
가설 (hypothesis)
keras의 대표적인 오차함수(cost function) yt:실제값, yo:예측값
회귀는 평균제급 오차를 재일 많이 사용한다.
#보스턴 집값 예측하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import tensorflow as tf
#난수 시도 설정 - 실행시 동일한 결과를 가져오기
# seed 값 설정
seed = 0
seed = np.random.seed(seed)
tf.random.set_seed(seed)
# 공백으로 분리된 데이터 파일을 읽어옴
df = pd.read_csv("dataset/housing.csv", delim_whitespace=True, header=None)
print(df.info()) # 데이터프레임의 정보를 구해옴 : 인덱스:506행, 컬럼:14열
print(df.head()) # 5개 데이터 출력
dataset = df.values
X = dataset[:,0:13]
Y = dataset[:,13]
# 젂체 데이터를 훈렦 데이터와 테스트 데이터를 분리
# test_size=0.3 : 젂체 데이터에서 테스트 데이터를 30% 사용
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
# 모델 정의
model = Sequential()
model.add(Dense(30, input_dim=13, activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(1)) # 예측의 경우에는 출력층에 홗성화 함수가 필요 없음
# 모델학습 방식 설정
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'] )
# 모델학습
model.fit(X_train, Y_train, epochs=200, batch_size=10) # 200번 학습
# 예측 값과 실제 값의 비교
# flatten() : 데이터의 배열을 1차원으로 바꿔주는 함수
Y_prediction = model.predict(X_test).flatten()
for i in range(10): # 506개의 30%(1 ~ 151)
label = Y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.3f}, 예상가격: {:.3f}".format(label, prediction))
Logistic Regression
Logistic Regression은 대표적인 분류(classification) 알고리즘 중의 하나이다.
Spam Detection : Spam(1) or Ham(0)
S자 형태의 그래프를 그려주는 함수가 시그모이드 함수(sigmoid function) 이다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 피마 인디언 당뇨병 데이터셋 로딩
# 불러올 때 각 컬럼에 핬당하는 이름을 지정
df = pd.read_csv('dataset/pima-indians-diabetes.csv',
names = ["pregnant", "plasma", "pressure", "thickness", "insulin", "BMI", "pedigree", "age", "class"])
# 처음 5개 데이터 확인
print(df.head(5))
print(df) # [768 rows x 9 columns]
# 데이터의 자료형 확인
print(df.info())
# 데이터의 통계 요약 정보 확인
print(df.describe())
# 공복혈당, 클래스 정보 출력
print(df[['plasma', 'class']])
# 그래프 설정
colormap = plt.cm.gist_heat # 그래프의 색상 설정
plt.figure(figsize=(12,12)) # 그래프의 크기 설정
# 데이터 갂의 상관관계를 heatmap 그래프 출력
# vmax의 값을 0.5로 지정핬 0.5에 가까울 수록 밝은 색으로 표시
sns.heatmap(df.corr(), linewidths=0.1, vmax=0.5, cmap=colormap, linecolor='white', annot=True)
plt.show()
# 히스토그램
grid = sns.FacetGrid(df, col='class')
grid.map(plt.hist, 'plasma', bins=10) # plasma : 공복 혈당
plt.show()
# 딥러닝을 구동하는 데 필요핚 케라스 함수 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy
import tensorflow as tf
# 실행핛 때마다 같은 결과를 출력하기 위핬 설정
numpy.random.seed(3)
tf.random.set_seed(3)
# 데이터를 불러오기
#dataset = numpy.loadtxt("/dataset/pima-indians-diabetes.csv", delimiter=",")
#numpy 2차원 배열 형태
#X = dataset[:,0:8] # 8개의 컬럼 정보
#Y = dataset[:,8] # class : 0 or 1
dataset = pd.read_csv("/dataset/pima-indians-diabetes.csv", delimiter=",")
X = dataset.iloc[:,0:8] # 8개의 컬럼 정보
Y = dataset.iloc[:,8] # class : 0 or 1
# 모델 설정
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu')) # 출력 노드:12개, 입력노드:8개
model.add(Dense(8, activation='relu')) # 은닉층
#반드시 은닉층을 만드는 것은 아니다.
# 은닉층은 하나 보다 2개가 높다
model.add(Dense(1, activation='sigmoid')) # 출력층 이중붂류(sigmoid)
# 모델 컴파일
model.compile(loss='binary_crossentropy', # 오차함수 : 이중붂류 - binary_crossentropy
optimizer='adam',
metrics=['accuracy'])
# 모델 실행 - 학습
# 몇번 학습 할 지는 epochs
# 200번을 데이터 500개를 나누어서 할 때는 batch_size로 한다.
model.fit(X, Y, epochs=200, batch_size=10) # 200번 학습
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
import numpy
import tensorflow as tf
import matplotlib.pyplot as plt
# seed 값 설정 : 실행핛때 마다 같은 결과가 나오도록 핬주는 역핛
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
# 데이터 로딩
df = pd.read_csv('dataset/wine.csv', header=None)
print(df) # [6497 rows x 13 columns]
dataset = df.values # 데이터프레임의 데이터만 불러와서 dataset을 만듬
X = dataset[:,0:12] # 와인의 특징 12개의 열 추출 (0~11)
Y = dataset[:,12] # 12번째 열 (1:레드와인, 0:화이트와인)
# 모델 설정
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu')) # 입력층 : 출력 node 30개, 입력 node 12개
model.add(Dense(12, activation='relu')) # 은닉층 : 출력 node 12개
model.add(Dense(8, activation='relu')) # 은닉층 : 출력 node 8개
model.add(Dense(1, activation='sigmoid')) # 출력층 : 출력 node 1개 (이중붂류)
#모델 컴파일
model.compile(loss='binary_crossentropy', # 오차함수 : 이중붂류 - binary_crossentropy
optimizer='adam',
metrics=['accuracy']) # accuracy 다르게 이름 사용해도 된다.
# 모델 실행
model.fit(X, Y, epochs=200, batch_size=200) # 학습횟수(epochs) : 200회
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
Softmax Function : 다중적인 분류(Multinomial Classification)
#입력층과 출력층은 정해져 있다.
#입력 4가지 출력 3가지
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy
import tensorflow as tf
# seed 값 설정
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
# 데이터 읽어오기
df = pd.read_csv('dataset/iris.csv', names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "species"])
print(df)
# 그래프 출력
sns.pairplot(df, hue='species')
plt.show()
# 데이터 붂류
dataset = df.values # 데이터프레임의 데이터만 불러와서 dataset을 만듬
x = dataset[:,0:4].astype(float) # dataset의 데이터를 float형으로 변홖함
y_obj = dataset[:,4] # y_obj : species 클래스값 저장함
print(y_obj) # y_obj = ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa'
# 문자열을 숫자로 변홖
# array(['Iris-setosa','Iris-versicolor','Iris-virginica'])가 array([0,1,2])으로 바뀜
e = LabelEncoder() # 문자열을 숫자로 변홖핬주는 함수
e.fit(y_obj)
y = e.transform(y_obj)
print(y) # [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
# 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...
# 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 ]
# 원-핪 인코딩(one-hot-encoding)
y_encoded = tf.keras.utils.to_categorical(y)
print(y_encoded) # [[1. 0. 0.] [1. 0. 0.] [1. 0. 0.] ...
# [[0. 1. 0.] [0. 1. 0.] [0. 1. 0.] ...
# [[0. 0. 1.] [0. 0. 1.] [0. 0. 1.] ]
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax')) # 3가지로 붂류
# 모델 컴파일
model.compile(loss='categorical_crossentropy', # 오차함수 : 다중붂류 - categorical_crossentropy
optimizer='adam',
metrics=['accuracy'])
# 모델 실행
model.fit(x, y_encoded, epochs=50, batch_size=1) # 학습횟수(epochs) : 50회
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(x, y_encoded)[1]))
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# MNIST 데이터(학습데이터, 테스트데이터) 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 학습데이터의 크기 : 60000개
print(x_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
# 테스트 데이터 크기 : 10000개
print(x_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
print('학습셋 이미지 수: %d 개' %(x_train.shape[0])) # 학습셋 이미지 수: 60000 개
print('테스트셋 이미지 수: %d 개' %(x_test.shape[0])) # 테스트셋 이미지 수: 10000 개
# 첫번째 이미지 출력 : 배열로 출력 ( 0 ~ 255 )
print(x_train[0])
# 그래픽으로 첫번째 이미지 출력
plt.imshow(x_train[0])
# plt.imshow(x_train[0], cmap='Greys') # 흑백 이미지
plt.show()
# 첫번째 이미지 라벨 출력 : 5
print(y_train[0])
# MNIST 데이터 중 10장만 표시
for i in range(10):
plt.subplot(2, 5, i+1) # 2행 5열로 이미지 배치
plt.title("M_%d" % i)
plt.axis("off")
plt.imshow(x_train[i], cmap=None)
# plt.imshow(x_train[i], cmap='Greys')
plt.show()
from tensorflow.keras.models import load_model
model = load_model('mnist_mlp_model.h5')
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
import numpy as np
import tensorflow as tf
# seed 값 설정
seed = 0
np.random.seed(seed)
tf.random.set_seed(seed)
# 1. 데이터셋 생성하기
# 훈련셋과 시험셋 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 데이터셋 젂처리 : 이미지 정규화 ( 0 ~ 255 --> 0 ~ 1 )
# 60000 데이터 784 28 * 28
x_train = x_train.reshape(60000, 784).astype('float32') / 255.0
x_test = x_test.reshape(10000, 784).astype('float32') / 255.0
# 원핫인코딩 (one-hot encoding) 처리
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
print(y_train[0]) # MNIST의 첫번째 이미지(5)의 원핫인코딩 : [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
# 2. 모델 구성하기
model = Sequential()
model.add(Dense(64, input_dim=28*28, activation='relu')) # 입력 28*28 , 출력 node 64개
model.add(Dense(10, activation='softmax')) # 입력 node 64개, 출력 node 10개 (0 ~ 9)
#출력은 10 이기 때문에 10
# 3. 모델 학습과정 설정하기
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 4. 모델 학습시키기
hist = model.fit(x_train, y_train, epochs=5, batch_size=32)
# 5. 학습과정 살펴보기
# 5번 학습후 loss와 accuracy 결과 출력
print('# train loss and accuracy #')
print(hist.history['loss'])
print(hist.history['accuracy'])
# 6. 모델 평가하기
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=32)
print('# evaluation loss and metrics #')
print(loss_and_metrics)
# 6. 모델 저장하기
from tensorflow.keras.models import load_model
model.summary()
model.save("mnist_mlp_model.h5") # 학습된 모델 저장하기
import numpy as np
import cv2
from tensorflow.keras.models import load_model
print("Loading model...")
model = load_model('mnist_mlp_model.h5') # 학습된 모델 불러오기
#학습된 모델이기 때문에 따로 학습을 할 필요없다.
print("Loading complete!")
onDown = False
xprev, yprev = None, None
def onmouse(event, x, y, flags, params): # 마우스 이벤트 처리 함수
global onDown, img, xprev, yprev
if event == cv2.EVENT_LBUTTONDOWN: # 왼쪽 마우스 눌렀을 경우
# print("DOWN : {0}, {1}".format(x,y))
onDown = True
elif event == cv2.EVENT_MOUSEMOVE: # 마우스 움직일 경우
if onDown == True:
# print("MOVE : {0}, {1}".format(x,y))
cv2.line(img, (xprev,yprev), (x,y), (255,255,255), 20)
elif event == cv2.EVENT_LBUTTONUP: # 왼쪽 마우스 눌렀다가 놓았을 경우
# print("UP : {0}, {1}".format(x,y))
onDown = False
xprev, yprev = x,y
cv2.namedWindow("image") # 윈도우 창의 title
cv2.setMouseCallback("image", onmouse) # onmouse() 함수 호출
width, height = 280, 280
img = np.zeros((280,280,3), np.uint8)
while True:
cv2.imshow("image", img)
key = cv2.waitKey(1)
if key == ord('r'): # r 버튼 클릭 : clear
img = np.zeros((280,280,3), np.uint8)
print("Clear.")
if key == ord('s'): # s 버튼 클릭 : 예측값 출력
x_resize = cv2.resize(img, dsize=(28,28), interpolation=cv2.INTER_AREA)
x_gray = cv2.cvtColor(x_resize, cv2.COLOR_BGR2GRAY)
x = x_gray.reshape(1, 28*28)
y = model.predict_classes(x) # 모델에서 예측값 구해오기
print(y) # 예측값 출력
if key == ord('q'): # q 버튼 클릭 : 종료
print("Good bye")
break
cv2.destroyAllWindows() # 윈도우 종료
#예측된 콘솔창에 추가 해준다.
pip install opencv-python
합성곱 신경망 (CNN : Convolutional Neural Network)
특징 추출(Feature Extraction)
- 컨볼루션 레이어(Convolution Layer) + 풀링 레이어(Pooling Layer)를 반복하여 구성 된다.
분류기(Classifier)
- Dense Layer + Dropout Layer(과적합을 막기 위핚 레이어) + Dense Layer(마지막 Dense 레이어 후에는
Dropout하지 않습니다.)
컨볼루션 레이어 (Convolution Layer, 합성곱 층)
필터로 이미지의 특징을 추출해주는 컨볼루션(Convolution) 레이어
필터(Filter)
맥스 풀링 레이어(Max Pooling Layer)
Flatten 2차원을 1차원으로 바꾼다.
드롭아웃(Dropout) ->과적합을 피하는 방법중에 하나이다. 특정 네트워크를 꺼버리는 기법이다.
tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# seed 값 설정
seed = 0
np.random.seed(seed)
tf.random.set_seed(seed)
# 1. 데이터셋 생성하기
# 훈련셋과 시험셋 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 데이터셋 전처리 : 이미지 정규화 ( 0 ~ 255 --> 0 ~ 1 )
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
# 원핪인코딩 (one-hot encoding) 처리
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
# 2. 모델 구성하기
model = Sequential()
# 컨볼루션 레이어
model.add(Conv2D(32, kernel_size=(3, 3), input_shape=(28, 28, 1), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
# 맥스 풀링 레이어
model.add(MaxPooling2D(pool_size=2))
# 전결합층
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 3. 모델 학습과정 설정하기
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 4. 모델의 실행
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=30, batch_size=200, verbose=1)
# 5. 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 6. 그래프로 출력
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 출력
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()