**배열의 집합
1.hstack
=>행의 수가 같은 배열을 열 방향으로 결합해주는 함수
2.vstack
=>열의 수가 같은 배열을 행 방향으로 결합해주는 함수
3.dstack
=>행과 열의 수가 같은 배열을 가지고 위치가 같은 요소들을 가지고 하나의 배열로 묶어서 차원이 1개 늘어난 배열을 만들어주는 함ㅅ
4.stack
=>dstack과 비슷하지만 원하는 방향으로 새로운 배열을 만들어서 차원을 늘려주는 함수
import numpy as np
#일련 번호 형태로 배열 만들기
ar = np.arange(1,13)
#3행 4열로 변경
ar = ar.reshape(3,4)
#일정한 간격을 가지고 만들기
br = np.linspace(101,112, num = 12)
br = br.reshape(3,4)
#열 방향으로 합치기
print(np.hstack([ar, br]))
#행 방향으로 합치기
print(np.vstack([ar, br]))
**pandas의 자료구조
=>series 와 dataframe
=>numpy의 ndarray는 행이나 열을 구분하는 것이 정수로 된 인덱스인데 pandas의 자료구조들은 index를 직접 설정 가능
1.Series
1)생성
Series(data, index = None, dtype = None, copy = False)
=>data는 __iter__가 구현된 객체
=>index는 데이터 별 이름을 부여하는 것인데 생략하면 0부터 시작하는 숫자
=>dtype은 각 요소들이 자료형인데 생략하면 유추해서 설정
=>copy는 복제 여부
=>data에 dict를 대입하면 key가 index가 되고 value가 데이터로 설정됩니다.
=>values속성을 호출하면 데이터만 추출해서 numpy의 ndarray로 리턴합니다.
=>index 속성을 호출하면 index들을 리턴하는데 직접 설정도 가능
=>각각의 데이터는 [인덱스]를 이용해서 접근
=>범위에 해당하는 데이터에 접근할 때는 [정수인덱스:정수인덱스]의 경우는 정수 인덱스 앞까지이지만 인덱스를 문자열로 생성해서 대입하는 경우 [문자열인덱스:문자열인덱스]는 마지막 문자열인데덱스를 포함
[0:4] ->0부터 3까지
['apple':'mango'] ->apple부터 mango까지 범위 설정
=>인덱스 자리에 list를 대입해서 list에 포함된 인덱스들의 데이터만 추출 가능
#series와 DataFrame은 현재 모듈에 포함시켜서
from pandas import Series, DataFrame
#series와 DataFrame 을 제외하고는 pd로 접근
import pandas as pd
#Series 만들기
good1 = Series([1000,1500,500])
print(good1)
#이름이 같이 붙는다.
#데이터에 접근
print(good1[0]) #1개의 데이터 접근
print(good1[0:2])#연속된 범위의 데이터 접근 2는 포함이 안된다.
print(good1[0,2]) #불연속된 데이터 접근
#인덱스 설정
good1.index = ['Orange','Apple','Banana']
print(good1)
print(good1['Orange':'Banana'])
#Orange부터 Banana까지
2)연산
=>Series와 Scala Data의 연산은 Broadcast연산(각각의 요소와 연산해서 결과를 다시 Series로 리턴)
=>Series끼리의 연산은 index를 기준으로 연산
None(numpy.nan)과의 연산은 결과가 무조건 None
=>없는 index와의 연산의 결과도 None
good1 = Series([100,200,150] ,index = ['1','2','3'])
good2 = Series([10,20,10],index = ['1','2','4'])
print(good1+200) #모든 요소에 200d을 더함
print(good1+good2)
#인덱스가 동일한 데엍끼리 연산
#1과 2번은 양쪽에 같이 있어서 더하기
#3과 4번은 한쪽에만 존재하기 깨문 None
good1 = Series([100,200,150,None, np.nan] ,index = ['1','2','3','5','6'])
good2 = Series([10,20,10],index = ['1','2','4'])
print(good1+200) #모든 요소에 200d을 더함
print(good1+good2)
#인덱스가 동일한 데엍끼리 연산
#1과 2번은 양쪽에 같이 있어서 더하기
2.DataFrame
=>인덱스 컬럼이름을 가진 행렬(2차원 배열) - 테이블
=>통계에서 주로 사용
=>dict의 list와 유사
=>외부 데이터를 가지고 생성하느 경우가 많고 직접 생성하는 경우는 dict를 주로 이용
하나의 key에 list형태의 value를 실행해서 생성
#딕셔너리를 생성
items = {'name':['orange','mango'],
'price':[2000,2500],
'nanufacture':['korea','taiwan']}
#DataFrame을 생성
df = DataFrame(items)
print(df)
1)생성 가능한 데이터
=>dict
=>2차원 ndarray
=>Sereis의 list
=>dict ,list, tuple ,set의 list
2)index
=>행에 붙이는 이름
=>직접 설정을 하지 않으면 0부터 시작하는 정수로 된 인덱스가 생성
=>생성할 때 index매개변수를 이용해서 직접 설정 가능
=>생성한 후 index속성을 이용해서 설정 가능
3)컬럼이름
=>열에 붙이는 이름
=>직접 설정하지 않으면 디폴트로 생성 :dict의 경우는 key가 컬럼이름으로 설정되고 그 이외는 정수
=>생성할 때 columns매개변수를 이용해서 설정이 가능
=>생성한 후 columns속성을 이용해서 설정 가능
4)테이블의 데이터 일부 확인
head(데이터 개수) : 앞에서 부터 데이터 개수 만큼 리턴
tail(데이터 개수): 뒤에서 부터 데이터 개수 만큼 리턴
5)info()
=>DataFrame의 개요 리턴
=>외부에서 데이터를 가져와서 DataFrame을 만들 때 head나 tail을 이용해서 데이터가 제대로 불려져 왔는지 확인하고 데이터의 개요를 확인하기 위해서 info()를 호출해서 사용
#딕셔너리를 생성
items = {'name':['orange','mango','apple','banana'],
'price':[2000,2500,3000,5000],
'nanufacture':['korea','taiwan','keorea','vetnam']}
#DataFrame을 생성
df = DataFrame(items)
#인덱스를 직접 설정
df.index = np.arange(10,50,10)
#3개의 데이터 확인
print(df.head(3))
#개요 확인
print(df.info()) #nan이 있으면 개수 가 다른다.

<class 'pandas.core.frame.DataFrame'> : 전체 데이터의 자료형
Int64Index: 4 entries, 10 to 40 : 행의 개수와 인덱스
Data columns (total 3 columns): 컬럼의 개수
name 4 non-null object : name이라는 컬럼은 4개의 데이터가 존재하고 자료형은 객체 (문자열)
price 4 non-null int64 : price라는 컬럼은 4개의 데이터가 존재하고 자료행은 정수
nanufacture 4 non-null object : nanufacture 이라는 컬럼은 4개의 데이터가 존재하고 자료형은 객체 (문자열)
dtypes: int64(1), object(2) : 1개의 컬럼은 정수로 되어 있고 2개의 컬럼은 객체
memory usage: 128.0+ bytes :메모리 사용량
None
=> 각 컬럼에 None의 개수를 파악할 수 있음
#sklean에서 제공하는 boston주택 가격 데이터 가져오기
import numpy as np
from pandas import Series, DataFrame
import pandas as pd
#sklean에서 데이터를 사용하기 위한 import
from sklearn import datasets
#boston 데이터 셋을 가져오기
boston = datasets.load_boston()
#자료형 확인 head오류
print(type(boston)) #키의 자료형 확인
print(boston.keys)
#<built-in method keys of Bunch object at 0x000001FE523639A8> method라는 것이다.
print(boston.keys())
#실제 데이터의 자료형을 확인
print(type(boston.data))
#DataFrame으로 변환
df = DataFrame(boston.data)
print(df)
#DataFrame으로 변환-컬럼이름을 확인해서 컬럼 이름 부여
#자져온 데이터 셋이 ndarray인 경우 데이터를 파악하기 가
#어려울 수 있어서 컬럼이름을 부여한 dataframem으로 가지고 있는 것이
#데이터 파악이 용이합니다.
#머신러닝에 적용할 때 는 df.values로 다시 ndarray로 만들면 된다.
df = DataFrame(boston.data,
columns = ['CRIM','INDUS','NOX','RM','LSTAT','B','PTRATIO','ZN','CHAS','AGE','RAD','DIS','TAX'])
print(df.info())
7)fwf파일 : 텍트스 파일인데 글자 수가 일정한 형태로 되어있는 파일
pandas.read_fwf(파일경로 ,widths=(글자수를 나열 ),
names=(컬럼이름 나열),
encoding= 인코딩 방식)
=>파일이 windows에서 기본 인코딩으로 만들어진 것이면 cp949(ms949)이고 그 이외의 운영체제에서는 만들어진 것이면 utf-8
import os
print(os.getcwd())
#data/data_fwf.txt파일의 내용을 가지고 dataFrame만들기
fwf = pd.read_fwf('./data/data_fwf.txt',width = (10,2,5),names =('날짜','종목이름','종가'),encoding = 'utf-8')
print(fwf)
8)csv파일 읽기
=>read_csv: 기본 구분자가 , 로 설정
=>read_table: 기본 구분자가 Tab
=>옵션 설정이 없으면 첫번째 행의 데이터가 컬럼이름 이 됩니다.
#item, csv파일을 읽어서 DataFrame 만들기
item = pd.read_csv('./Desktop/data/item.csv')
print(item.head())
print(item.info())
=>read.csv의 매개변수
path: 파일의 경로
sep: 구분자(기본은 , )
header: 컬럼이름에 행 번호로 기본값은 0, 첫번째 행이 컬럼이름이 아닌 경우는 None으로 설정
index_col: 인덱슬로 사용할 컬럼 번호나 컬럼 이름
names: 컬럼이름으로 사용할 list, header = None과 함께 사용
skiprows: 읽지 않을 행의 개수
nrows: 일부분만 읽는 경우 읽을 행의 개수
skip_footer: 마지막에 읽지 않은 행의 개수
encoding : 인고딩 설정
squeze : 행이 하나인 경우 Series를 만드는데 이 속성의 Trueㄹ 설정하면 DataFrame으로 생성
thousands: 천 단위 구분 기호 설정 ,이 설정을 하지 않은 상태에서 , 가 있는 데이터를 읽으면 문자열로 읽게 됩니다.
na_values :None 처리할 데이터의 list
parse_datas: 날짜 형식의 데이터를 datetime으로 변환할 지 여부
0 - 남자
1 - 여자
99 - 예상
[-,'99'] -None
날짜는 빼기 가능하다. 시계열 분석 가능하다.
한글이 있는지 없는지 있으면 encodng이다.
#item, csv파일을 읽어서 DataFrame 만들기
item = pd.read_csv('./Desktop/data/item.csv')
print(item.head())
print(item.info())
#good.csv파일을 읽어서 dataframe 만들기
good = pd.read_csv('./Desktop/data/good.csv',header = None, names=['제품명','수량','가격'])
print(good.head()) #컬럼 이름 이 되서 별로 보기 좋지 않다. ,header = None, names=['제품명','수량','가격']
print(good.info())
=>텍스트 파일의 용량이 큰 경우 (데이터가 많은 경우 )
log 분석을 하기 위해서 csv를 읽어오는 경우 실무에서 사용하는 데이터는 아주 큰 용량입니다.
한국 ebay의 경우 하루 로그기록하는 파일의 사이즈가 대략 8GB정도 됩니다.
이런 정도의 파일을 한 번에 읽어서 DataFrame을 만들게 되면 시스템이 멈추거나 아주 느리게 작업이 이루어지게 됩니다.
이런 파일은 분할해서 읽어야 합니다.
nrows와 skiprows를 이용할 수 있습니다.
읽을 떄 chunksize(한 번에 읽을 행의 개수)를 설정 - 이 옵션을 설정하면 TextParser객체가 리턴 TextParser를 iterator(for)를 돌리면 chunksize단위로 데이터를 가져오게 됩니다.
#good.csv파일의 내용을 2개씩 읽어오기
goodchunk = pd.read_csv('./Desktop/data/good.csv',chunksize =2, header = None)
print(goodchunk)
#TextFileReader
for two in goodchunk:
#print(type(two))
print(two)
#2개씩 찾아돈다.
아주 큰 싸이즈를 들고 올 때는 분할해서 들고 온다.
=>문자열이 작은 따옴표나 큰 따옴표로 묶여 있는 경우 또는 구분자가 1글자가 아니고 여러 글자인 경우에는 read_csv가 제대로 데이터를 읽지 못하는 경우가 발생할 수 있습니다.
csv모듈의 reader 객체를 이용해서 줄 단위로 읽어서 처리를 해야 한다.
#문자열이 작은 따옴표로 묶여 있는 경우
fruits = pd.read_csv('./Desktop/data/fruit.csv',header = None,sep="|")
print(fruits)
#줄단위로 읽어서 dataframe만들기
import csv
lines = list(csv.reader(open('./Desktop/data/fruit.csv'),delimiter='|'))
print(lines)
#줄 단위로 읽어서 DATAFRAME으로 전화하면 된다.
fruits = DataFrame(lines, columns = ['이름','수령','가격'])
print(fruits)
9)CSV저장
=>Series나 DataFrame 객체가 to_csv함수를 호출
=>첫번째 매개변수는 파일 경로
=>sep는 저장될 때의 구분자를 생성
=>na_rep는 None값을 어떻게 출력할 것인지를 설정
=>index= None을 설정하면 인덱스는 출력되지 않음
=>header = None을 설정하면 컬럼이름이 출력되지 않음
=>cols에 컬럼이름의 list를 설정하면 설정한 컬럼들만 출력
#파일제 저장
fruits.to_csv('./Desktop/data/fruits.csv')
설정을 바꾸는 게 좋다. index = None해주는게 좋다.
10) excel파일 읽기
=>anaconda를 설치하지 않은 경우에는 xlrd패키지르 설치해야 합니다.
=>pandas.read_excel(엑셀 파일 경로)
=>pandas.excel.read_excel(엑셀 파일 경로)
=>함수들의 매개변수는 read_csv랑 유사한데 sheet_name옵션에 읽을 sheet이름을 설정해야 합니다.
11)excel파일 저장
=>ExcelWriter 객체를 만들고 DataFrame.to_excel(ExcelWriter객체 , sheet_name = '시트이름')
실습 - excel .xlsx파일에 읽기
=>한글이 포함되어 있고 첫번째 줄이 컬럼의 이름인 것을 확인
인코딩을 고려
#엑셀 파일 읽고 쓰기
excel = pd.read_excel('./Desktop/data/excel.xlsx',sheet_name = 'Sheet1')
print(excel)
writer = pd.ExcelWriter('./Desktop/excel.xlsx')
excel.to_excel(writer, sheet_name='연습')
writer.save() #엑셀로 저장
12)html페이지의 table 태그의 내용을 DataFrame으로 변환
pandas.read_html(경로)
=>천단위 구분기호 설정, 인코딩 방식, na 데이터 설정 등의 옵션이 있습니다.
=>하나의 페이지에 table 태그가 여러 개 있을 수 있기 떄문에 DataFrame의 list로 리턴
#pandas의 read_html 함수 도움말
help(pd.read_html)
li = pd.read_html('https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B5%AC%EC%88%9C_%EB%82%98%EB%9D%BC_%EB%AA%A9%EB%A1%9D',thousands = ',')
for df in li :
print(df.head())
print(li[0])
#list가 와서 다른 형태로 쓰야 한다.
13)json데이터 읽기
=>pandas.read_json을 이용해서 읽습니다.
=>대다수의 데이터는 배열의 형태가 아니고 일반 객체 형태라서 바로 만들면 나중에 가공 작업이 필요한 경우가 많습니다.
[1,2,3,4,5,6,7,8,9,10]
list: 익덱스로 구분
dict: key로 구분
ndarray과 dataframe에서 dataframe이 편한다.
#json 데이터 읽기
movies= pd.read_json("http://swiftapi.rubypaper.co.kr:2029/hoppin/movies?version=1&page=1&count=20&genreId=&order=releasedateasc")
print(movies)
print(movies['hoppin'])
print(movies['hoppin']['movies'])
print(movies['hoppin']['movies']['movie'])
for temp in movies['hoppin']['movies']['movie']:
print(temp['title'])
14.xml읽기
=>pandas에는 xml을 읽어서 만드는 함수는 없습니다.
이 경우에는 xml파싱을 수행한 후 직접 만들어야 합니다.
15)데이터베이스의 데이터를 가져고 DataFrame만들기
=>sqlalchemy 패키지: 관계형 데이터베이스에 접속해서 sql을 실행시켜서 데이터를 가져오는 패키지
=>sqlalchemy 패키지를 이용한 데이터베이스 연결 객체 만들기
from sqlalchemy import create_engine
연결객체 = create_engine(데이터베이스 url)
=>sql을 이용한 DataFrameㅇ만들기
pandas.read_sql_query(sql구문 ,연결 객체 ):sql구문 수행 결과를 가져오는 함수
pandas.read_sql_table(table이름 , 연결 객체 ): 테이블의 데디터를 전부 가져오는 함수
16)sqlite3의 pl테이블의 데이터 가져오기
#sqlite3의 데이터 가져오기
import pandas as pd
from sqlalchemy import create_engine
#연결 객체 생성
con = create_engine('sqlite:///data/sample.db')
#sql을 실행해서 dataframe만들기
pl = pd.read_sql('select * from pl',con)
print(pl)
17)오라클의 데이터 가져오기
=>cx_Oracle 이라는 패키지가 필요
=>Mac 에서는 바로 접근이 안되서 Oracle홈페이지에서 instant client라는 프로그램을 다운로드 에서 설치한후 /opt디렉토리에 oracle디렉토리르 생성하고 받은 파일의 압축을 해제
압축해제한 디렉토리에서 lib파일들을 /user/loacl/lib디렉토리에 복사를 해야 합니다.
=>접속 URL - oracle://유저id:유저비밀번호@ip:port/sid
#sqlite3의 데이터 가져오기
import pandas as pd
from sqlalchemy import create_engine
#연결 객체 생성
con = create_engine('oracle://유저id:유저비밀번호@ip주소:1521/xe')
dept = pd.read_sql('select * from dept',con )
print(dept)

18)mysql에서 데이터 가져오기
=>pymysql이라는 패키지가 필요
=>접속 url : mysql+mysqldb://유저id:유저비밀번호@ip:port/db이름
https://www.mysql.com/downloads/
gpl이 무료로 하는것

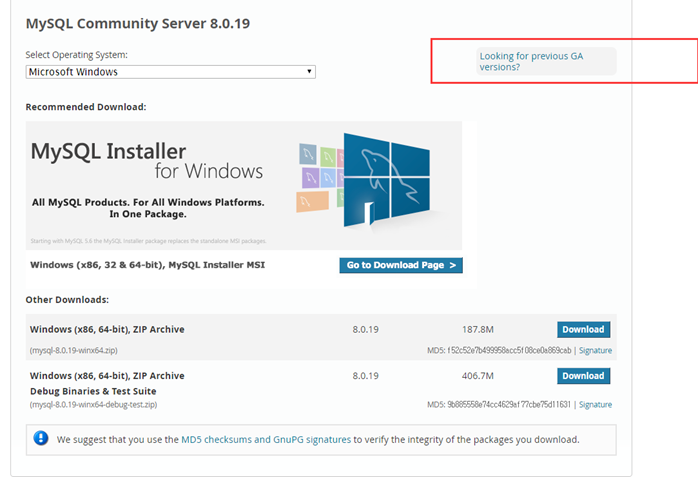
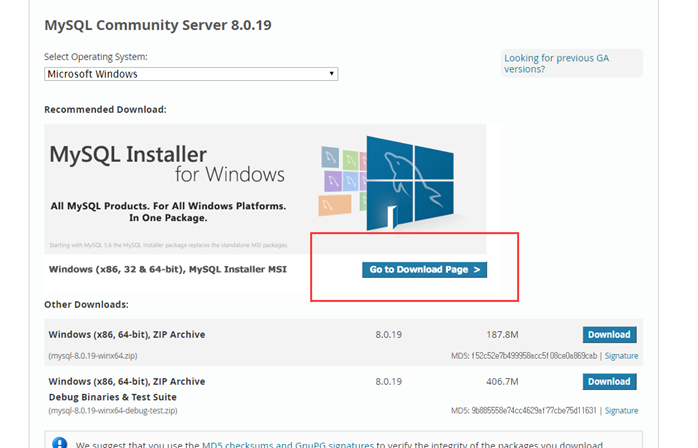
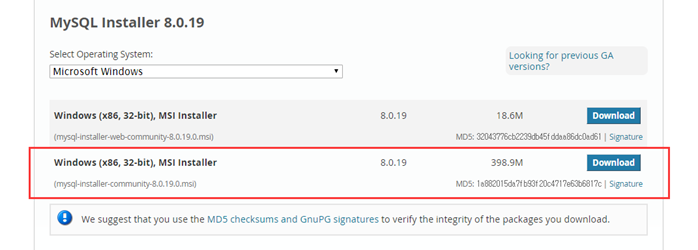
mysql이 ->oracle인수해서 유료로 만들었다.
mariadb는 mysql 5점대하고 같다.
mysqldl

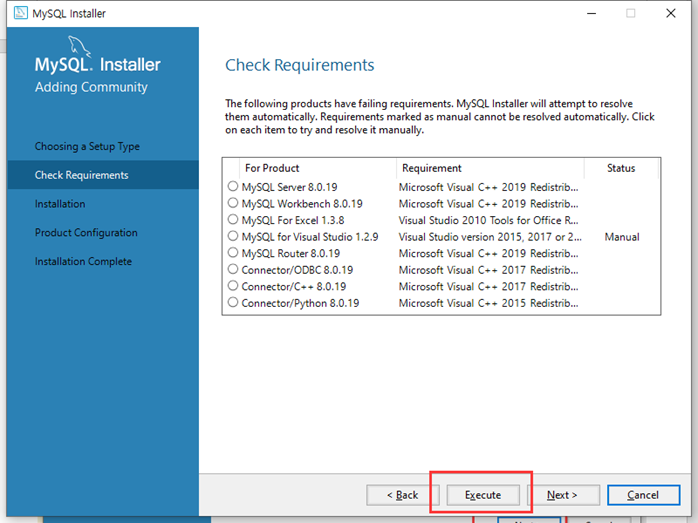
c++로 배포를 하게 되면 배포된 자리에 c++나 재배포 패키지가 설치되어 있어야 실행이 가능
mac , linux는 c++이 할수 있지만 windows는 설치가 안되여 있다.
visual c++ 설치 를 해야 한다.
python에서 문제가 생기면 visual c++재배포 가능한것 설피 해야 한다.
--데이터베이스 확인
show databases;
--데이터베이스 생성
create database park;
--데이터베이스 설정
use park;





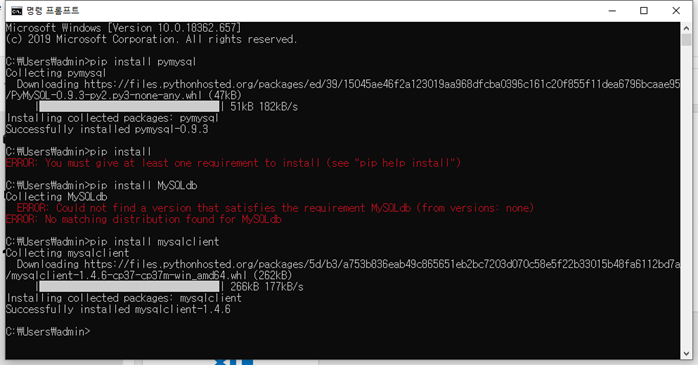
#mysql+mysqldb://유저id:유저비밀번호@ip:port/db이름
#sqlite3의 데이터 가져오기
import pandas as pd
from sqlalchemy import create_engine
import pymysql
pymysql.install_as_MySQLdb()
import MySQLdb
#연결 객체 생성
con = create_engine('mysql+mysqldb://root:1234@localhost:3306/park')
dbms = pd.read_sql('select * from dbms',con )
print(dbms)
3.datafram에서의 선택
1)열 선택
하나의 열은 DataFrame[열이름] 또는 DataFraem.열이름 으로 접근
여러개의 열은 DataFrame[[열이름나열]]
DataFrame[열이름: 열이름 ] ->마지막열이 포함됩니다.
2)행 선택
=>iloc[행의 위치]
=>loc[인덱스]
list형태나 :을 이용한 범위 형태 가능
하나의 행인 경우는 Series로 리턴되고 2개 이상인 경우는 DataFrame으로 리턴
3) 셀 선택
=>[컬럼이름][행번호]
=>loc[행인덱스,열인덱스]
=>iloc[행번호, 열번호]
#dATAFRAME에서의 선택
#item.csv파일의 데이터 가져오기
import numpy as np
import pandas as pd
#item.csv파일의 내용을 가져오기
item = pd.read_csv('./Desktop/data/item.csv')
#컬럼이름 :code, manufacture,name,price
print(item.head())
item.info()
#인덱스 설정
item.index = ['사과','수박','참외','바나나','레몬','망고']
print(item['name']) #하나의 열 선택
print(item[['name','price']]) #여러 개 열 선택
#행 선택
print(item.loc['사과'])
print(item.iloc[2])
print(item.loc['사과','망고']) #인덱스 로 접근
print(item.iloc[2,4]) #행의 위치로 접근
print(item.loc['사과':'망고']) #인덱스 로 접근
print(item.iloc[0:5]) #행의 위치로 접근
4)boolean indexing
=>loc에 bool자료형의 series를 대입하면 TRUE인 행 만 추출
=>Series는 scala data와 연산을 하게 되면 BROADCAST연산을 수행해서 Series로 결과를 리턴
=>Series가 isin([값 나열])를 대입하면 값에 속한 것들만 True그리고 나머지는 False인 Series를 리턴
#price가 100 0 이상인 데이터만 추출
print(item[item['price']>= 1000])
#price가 1000이나 1500 인 데이터
print(item[item['price'].isin([1000,1500])])
4.DATA탐색 관련 함수
1)head: 정수를 대입해서 정수만큼의 데이터를 앞에서부터 리턴
2)tail:정수를 대입해서 정수만큼의 데이터를 뒤에서부터 리턴
3)shape: 행과 열의 수를 tuple로 리턴
4)info: 데이터의 대략적인 개요
5)dtypes:각 컬럼의 자료형을 리턴
6)describe: 기술 통계 정보를 리턴하는데 include = True옵션을 추가하면 숫자가 아닌 컬럼의 정보도 리턴
7)count: 데이터 개수
8)value_counts: 각 값들의 개수인데 Series에만 사용
9)unique: 고유한 값 리턴
#데이터 탐색 함수
df = pd.read_csv("./Desktop/data/auto-mpg.csv")
print(df.head())
#기술 통계 정보 확인
print(df.describe())#숫자 데이터의 통계
print(df.describe(include = 'all'))#문잗 포함
#카테고리 형태의 데이터의 분포 확인
print(df['origin'].value_counts())
5.기술통계 함수
=>count, max, min, mean(평균),median(중간값),var(분산),std(표준편차)
=>skew(비대칭도 - 왜도 ),kurt(청도),sem(평균의 표준오차) 잔차 ,mode(최빈값)
왜도 좌우로 얼마나 틀어졌나 ?좌우로 얼마나 움직였나
청도 : 정규분포 내것이 얼마나 위 아래로 퍼졌너나 ? 뽀족함 위 아래
평균의 표준오차: 평균과차이 나는 것 잔차 :
평균 점수의 차이
90 80 85 평균이 85
+5 -5 0 ->잔차
잔차의 합을 구하면 0으로 될 가능성이 있다. 퍼지는 것이 대해서 그다지 효율적이지 않는다.
거리의 개념으로 찾아서 제곱해서
25 25 0 ->제곱해서 합을 구하는 것이 분산이다.
25+25+0 / 3 = >
통계학에서는 25+25+0/ 3-1 =
빼기 1을 하자
70 , 85 , 105 -> 평균이 85
누가 더 고르냐 ?
25 + 25 /2 = 25
15의 제곱 + 15의 제곱 / 2
분산을 사용하면 편향이 심해진다. 그래서 ROOT를 씌워준다.
225의 ROOT
편향 때문에 데이터를 줄인다.
보통은 중간값이나 MODE를 하는 것이 많다.
=>argmin, argmax,idxmin,idxmax,
arg->위치 idx ->인덱스
=>quantile(4분위수 - 25%, 50%, 75%, 값)
max, min , quantile 같이 보면 대략적인 분포를 볼 수 있다.
=>descrive(요약정보)
=>cumsum, cumprod,cummax, cummin:누락
=>diff(앞 데이터와의 차이)
=>pct_changes(앞 데이터와의 차이를 백분율로 출력)
=>unique: 고유한 데이터들의 배열 리턴
=>DataFrame에서 axis옵션을 0이나 1을 설정하면 행과 열방향 반대
=>skipna 옵션을 True로 설정하면 None값을 제외하고 그렇지 않으면 None값을 포함
#cyl 컬럼의 평균
print(df['cyl'].mean())
stock = pd.DataFrame({'다음':[1000,1200,1960]})
print(stock['다음'].diff()) #각 행의 차이
print(stock['다음'].pct_change()) #각 행의 차이 를 비율로
# NaN, (1200-1000)/1000 , (1960-1200)/1200
6. 공분산과 상관계수
=>공분산은 cov()
=>상관계수는 corr()
=>Series를 이용할 때는 Series객체가 함수를 호출하고 다른 Sereis객체를 매개변수로 대입
=>DataFrame은 함수만 호출하면 모든 컬럼의 공분산이나 상관계수를 출력
1)공분산(covariance)
=>2개의 확률 변수의 상관정도를 나타내는 수차
=>분산은 하나의 확률 변수의 이산정도를 나타내는 수치
=>공분산은 2개의 컬럼 사이의 관계를 파악한 수치
하나의 컬럼의 값이 증가하는 추세를 보일 때 같이 증가하면 양수이고 감소하면 음수가 됩니다.
공분산은 하나의 값이 증가할 때 다른 하나의 값이 얼마나 증가하는 지 또는 감소하는 지를 수치화
a 100 -> 200
b 5 -> 15
값의 범위에 따라 서 a는 2배 b는 3배 하지만 a는 100 b는 10
공분산은 증가한 값
2)상관계수
=>공분산과 개념은 같은데 값의 범위를 -1~ 1까지으로 제한
하나의 컬럼의 값이 증가할 때 동일한 비율로 증가하면 상관계수는 1
하나의 컬럼의 값이 감소할 때 동일한 비율로 증가하면 상관계수는 -1
절대값 0.6 이상이면 상관이 높다라고 하고 0.4 정도 이상이면 상관이 있다라고 하고 0.4이하면 상관이 없다라고 합니다.
상관계수가 0인 경우는 상관이 없다라는 것이지 관계가 없다라는 표현이 아닙니다.
=>피어슨 상관계수 : 비율을 가지고 구하는 상관계수 - 선형 관계인 경우 적합
=>스피어만 상관계수 : 값의 증가와 감소에만 집중하는 상관계수 - 비선형 관계에 적합
=>캔달 순위 상관계수 : 순위를 가지고 상관계수를 구함
피어슨 상관계수는 비율이 1로 차이나야 한다. 늘어난 비율이 달라야 한다.
비율이 안 맞고 하면 캔달 순위 상관계수 : 국어를 잘하면 영어를 잘하더라 점수는 95점이지만 다른 분이 100점 일 경우 국어 , 영어는 같은 비율이 아니다.
잴 먼저 찾아야 하는 것은 상관계수
3)상관계수 대신 사용하는 것들
=>산점도나 선 그래프를 그려서 데이터 간의 관계를 파악할 수 있습니다.
상관관계는 산점도나 등 cor, cov
#데이터 탐색 함수
df = pd.read_csv("./Desktop/data/auto-mpg.csv")
print(df.head())
# weight와 mpg의 상관계수 확인
#둘 다 음수가 나왔고 0.6 이상이므로 음의 상관관계
print(df['weight'].corr(df['mpg']))
#-0.8322442148315753 음의 상관계수
print(df['hp'].corr(df['mpg']))
#-0.7784267838977759
#상관관계가 0인데 계속 뽑아내면 의미가 없다.
7.정렬(sort)
=>sort_index()호출하면 인덱스 순서대로 오름차순 정렬
axis=1 을 대입하면 컬럼의 이름 순서대로 오름차순 정렬
ascending에 True을 대입하면 내림차순 정렬
=>Series객체는 sort_values()를 호출
=>DataFrame에서 특정 컬럼을 가지고 정렬을 하고자 하는 경우에는 sort_Values함수에 by 매개변수로 컬럼의 이름을 list로 대입하면 됩니다.
print(df['hp'])
print(df['hp'].sort_values()) #오름 차순 정렬
print(df['hp'].sort_values(ascending= False)) #내림차순 정렬
#hp의 오름차순 그리고 값이 같으면 cyl의 오름차순 정렬
print(df.sort_values(by=['hp','cyl']))
8.rank
=>순위를 구해주는 함수
=>asending을 False로 설정하면 내림차순으로 순위를 구함
=>동점인 경우의 순서는 method를 이용해서 설정할 수 있는데 max를 대입하면 큰 순위로 min을 대입하면 작은 순위로 그리고 first를 설정하면 먼저 등장한 데이터가 작은 순위로 대입
max min first 기본
100 -1 1 1 1 1
90 -4 4 4 4 4
93 -2 3 2 2 2.5
93 -2 3 2 3 2.5
87 -5 5 5 5 5
max하면 3으로 하고
min이면 2로 한다.
min은 우리가 보통 사용하는 것
9.rename
=>컬럼이나 인덱스의 이름을 변경할 때 사용하는 함수
=>index나 columns매개변수에 {기존이름: 새로운이름...} 의 형태로 대입하ㄴ면 index나 columns를 수정해서 새로운 DataFrame을 리턴
=>axis 꼭 기억하기
inplace = True
=>inplace=True옵션을 추가하면 함수를 호출한 DataFrame을 변경합니다.
메모리 문제 때문에 메모리 사용량을 줄이기 위해서
없으면 새로 만들어진다. 계속 복사본을 만들면 멈출수 있다.
추천 시스템을 만들 경우 R로 하면
A B F D
A C F K
A C
옆으로 15 아래로 10개
15 * 10 ->r에서 메모리가 8기가 되면 10분 걸린다.
10.인덱스 재구성
=>reindex속성을 이용해서 인덱슬르 재배치 가능
=>set_index('열이름'또는 열이름의 list ) :열로 index로 생성하는데 열은 데이터에서 제거
=>reset_index():인덱스가 제거되고 0부터 시작하는 숫자로 초기화: 그룹화에서 많이 사용
#item.csv내용 가져오기
item = pd.read_csv('./Desktop/data/item.csv')
print(item)
#순위 출력
print(item.rank())

print(item.rank(method = 'min'))

print(item['code'].rank(method = 'min'))=>하나의 열
#코드를 index로 만들기
item.set_index('코드')
item
#코드를 index로 설정 데이터에서는 제거
item.set_index('코드',inplace = True)
print(item)
item.reset_index('코드')
print(item)#코드를 index로 설정 데이터에서는 제거