본 내용은 fastcampus 딥러닝/인공지능 올인원 패키지 online을 정리한 것이다.
파이썬 개발 환경 설정
anaconda 설치
python 3.7
jupyter notebook
anaconda
jupyter 환경에서 하게 된다.
파이썬 개발 환경 설정
anaconda 통합 platform이다.
각 플렛폼 마다 다르다.
다운된 것을 실행 하면 된다.
install 기본값으로
anaconda 환경을 기본환경으로 한다는 것만 check하면 된다.
Jupyter notebook 설치 및 사용법 소개
New를 하면 언어를 선택 가능 python3로 하면 된다.
마우스 클릭하고 esc눌리면
cell 은 실행할 코드나 주석 등을 입력
녹색 : 타이핑 가능 입력 모드
파란색 : 명령어를 할수 있다. 명령 모드
명령 모드 파란색
명령어 모드에서 h를 눌리면 키보드 단축키가 나온다. -> help

cell추가하면 위에 a
cell 아래 추가하면 b
d 두번 눌리면 지우기
shift+ enter : cell 실행하고 아래로 옮긴다.
ctrl+enter: cell 그냥 실행하고 cursor안옮긴다.
alt + enter: cell 실행하고 아래로 추가한다.
jupyter notebook cell의 type:
in 이것은 type은 코드이다.
cell 가지고 cell type에서 markdown으로 바꿀 수 있다.
markdown in이 없어졌다.
코드 입력할려면 in이 있어야 한다.
markdown은 문서를 만들때 문서와 구조를 한꺼번에 하는것
코드에 대한것 깔끔하게 하고 싶다.
# 큰 title
##
###
####
코드모드에서 m markdown
markdown에서 코드 모드 y
**python** bold
*cool* itelity
list로 하고 싶을 떄 - 순서가 없는
- pyton
- pandas
- java
순서
1. python
2. java
> 비교 연산자 들여쓰기 하는
> 파이썬은 재밌다고 하더라.
마크 다운 수학식 지원
$y = 3x$
코드 지원
'''pytonn
'''
한글로 link사용
[파이썬](url)
타입 및 변수
데이터 타입과 컬렉션
변수 : 데이터를 저장하는 공간, 변수
저장공간에 값을 생성하고 이름을 지정
=(대입연산자)를 사용하여 왼쪽은 변수명, 오르쪽은 데이터가 위치 변수 혹은 값
= 대입연산자
== 비교연산자
정수형과 실수형
a = 1
b = 2.1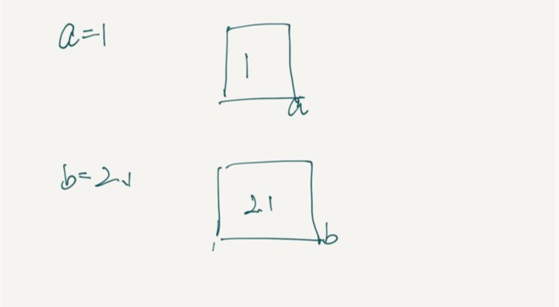
print함수
값을 확인 하는 함수
함수는 특정 기능 먼저 구형하여 그 함수를 반복적으로 호출하여 사용가능한 코드 블록
이름 명명 규칙에서 숫자로 시작하면 안된다.
해당 변수의 값을 출력
, 로 여러 변수를 나열하면 한줄에 출력
기본적으로는 한칸 띄어쓰기 후 출력
#뒤에 오는 거은 주석이다.
각 print사이에는 enter이다.
a = 10
b = 11.4
print(a, b)
print(a, 10, 200, b)
sep: 구분자 , 각 출력할 변수 사이에서 구별하는 역할을 함
end: 마지막에 출력할 문자열
shift+tab을 이용해서 자세한 정보 볼 수 있다.
print(a, b, 10, 100, sep = "*" , end ="!!")space를 *로 대체
원하시는 출력으로 출력 가능하다.

변수 값 확인법
print()함수 사용
변수 값을 코드의 마지막에 위치 시킨 후 실행
print(a)
print(a, b)
aprint는 출력만 하지 output이 아니다.

마지막 값이 전체 값의 out으로 나온다.
변수이름 규칙
대소문자
숫자는 사용가능하되 숫자로부터 시작하면 안된다.
숫자로 시작하면 안되는 이유?
4 = 9
print(4)이해하기 쉬운 것으로 명시적으로 이름을 하는게 좋다.
또 한가지 안되는 것이 있다.
class 사용할 경우 녹색으로 변해서 예약어있다.

for
while
if
elif
else
class
try
excpt
class
#,,,
이런것을 사용하고 싶을 경우에는
_class = 100
print(_class)
_ 로 사용해야 한다.
05. 데이터
기본 데이터 타입 4가지 int, float, str, boolean
int: a = 10
flot: b = 11.45
type(A)
None : 아무런 값을 갖지 않을 때 사용
c => 이렇게는 안된다.
python은 무조건 초기화해야 한다.
변수 생성하고 싶은 데 어떤 값으로 해야 할지 모를떄
초기화 값을 모를때
정수와 실수
a = 5
b = 4
# 숫자형이면 비교 가능
#결과는 boolean이다.
print( a > b ) #True
print( a < b) #Flase
print( a >= b) #True
print( a <= b) #False
print( a == b) #False
print( a != b) #True
c = a>b
c = True
print(type(c))
print(c)

여러가지 연산을 다 할 수있다.
변수의 값은 대입하기 전에 값은 변하지 않는다.
a = 5
b = 4
print(a+b)
print(a*b)
print(a-b)
print(a/b)
print(a%b)
print(a**b)
a= 5
b = 4
a + b*4
a+b 를 먼저 하고 싶을 경우에는 (a+b) * 4
연습문제
a = 9
print(a)
print(a-3)
print(a)
변수의 값은 대입이 발생하기 전에는 절대 변하지 않는다.
a = 9
a-3
print(a)
a= 9
t = a-3
a = t
print(a)
위에것 비효율 적이여서 아래처럼 바꾼다.
a= 9
a = a-3
print(a)더 줄이기
a = 9
a-=3
print(a)- 뿐만 아니라 +, * , / 등 사용가능하다.
문자열 타입의 이해 및 활용하기
문자열
생성 4가지 방법
a = ' '
b = " "
위 두개는 차이점이 없다. 문자열 안에서 사용한 것과 다르게 사용하면 된다. enter 사용 불가
a = ''' '''
b = """ """
위 두개는 enter사용가능하다.
차이점이 있다. 출력은 같지만
escape 문자
문자열 자체로 쓰이는 것이 아니라 특수 효과로 쓰인다.
\n new line
\t tab 등
indexing은 0부터 ㅣ작한다.
마지막 순서는 -1혹은 len()-1
대괄호 이용해서 index사용할 수 있다.
python은 음수 index 지원한다.
0부터 시작하고 음수 index도 지원한다.
음수는 뒤에서 부터 시작한다.
인덱스의 범위
범위를 초과하면 string index out of range라는 에러가 난다.
유용한 index사용하기
문자열 slicing : 부분적으로 짜르는 것 이다.
시작 : 끝 사이의 문자를 가져온다.
a = 'Hello world'
a[0:4]
0<= <4
생략도 가능하다.
:끝 0 ~ 끝-1
시작: 시작 ~ 끝
: => 시작 부터 끝
부분 문자열을 추출 할때
문자열 함수
a = 'hello world'
a. 하고 tab을 눌리면
upper() 대문자
replace('','')
format
temperature = 25.5
prob = 80.0
a = '오늘 기온{}도 이고 , 비율 확률은 {}% 입니다.'.format(temperature, prob)
print(a)
split
.split() 띄여쓰기를 기준으로 한다.
.split('w') 문자열 혹은 기타로 하고 싶을 때 w 기준으로 하고 싶을 때
a = 'hello world what a nice weather'
a.split('w')
컬렉션 타입 이해 (List)
컬렉션 -> 어떤 것들의 모음이다. 모음이 어떤 목적에 의해서 모은것인지
list & tuple
list순서가 있는 추가 , 삭제 등 가능 동적으로 크기가 변경 가능
tuple 생성된 후에 변경 불가능
list
a = []
a = [1,2,3,4,5]
a = 'hello world'
b = list(a)
split() 함수
indexing
문자열
a = 'hello wold'
print(a[0]
a[0] = 'j' => 어레가 난다. 'str' objects does not support item assignment
문자열은 불변(immutable) 변경이 안된다. 그래서 다시 생성하거나
문자열이 생성되면 절대 바꿀 수 없다.
b = 'jello world'
c = 'j'+a[1:]
혹은 replace()함수를 사용해서
a.replace('h','j') 하지만 a자체는 변하지 않는다 . 출력만 한다. 값을 바꾸려면 대입을 해야 한다.
list는 바꿀 수 있다.
a =[1,2,3,4]
a[0] = 100
리스트 slicing
start: end : increment(1)
값 추가 및 바꾸는것
컬렉션 타입 이해 -2 (List)
list에도 멤버 함수가 있다.
list에 값을 추가하는것
.append() 리스트의 끝에 항목을 추가
.extend() 리스트를 연장 += 로도 가능함
a = [1,2,3,4,5]
b = [6,7,8,9,10]
#[1,2,3,4,5,6,7,8,9,10]
a.append(b)
[1,2,3,4,5,[6,7,8,9,10]]
a[5]
[6,7,8,9,10]
=>
a.extend(b) 혹은 a+=b
print(a)
append는 항상 마지막에 추가
insert() 원하는 위치에 추가
remove() 값 지우기 값으로 지운다.
a.remove(2) 값으로 지우기
지우고 싶은 값이 없을 경우에는 오류가 난다.
pop() 지우고자 하는 아이템을 반환후 , 삭제
index() 찾고자 하는 값의 인덱스 반환
값으로 찾기 없을 경우에는 에러
in 키워드 : 리스트 내에 해당 값이 존재하는지 확인
a = [1,2,3,4,5,10]
b = 10
c = b in a # True => b가는 값이 a에 있는 가 ?
list 정렬
sort() -> 리스트 자체를 내부적으로 정렬
sorted() -> 리스트의 정렬된 복사본을 반환
a= [9,10,7]
a.sort(reverse=True) =>내림차순
컬렉션 타입 이해 -3(tuple)
튜플은 괄호를 이용한다.
a=[1,2,3] =>list
a = (1,2,3) => tuple
tuple은 생성된 후 수정 불가
거의 사용하지 않지만
사용 원인
튜플의 값을 차례대로 변수에 대입
a = (100,200)
a = 100, 200 => 괄호를 생략 가능하다.
type(a)
a, b = (100,200) => multiple return
print(a,b)
변수 여러개 대입하거나 할 수있어서 편한다. tuple unpacking
함수는 값을 한개 할 수있지만 tuple로 반환하면 여러개 할 수있다.
연습문제
a = 5
b = 4
#logic
a = b
b = a
print(a,b)
a = 5
b = 4
#logic
temp = a
a = b
b = temp
print(a,b)
a = 5
b = 4
a,b = b,a
print(a,b)
컬렉션 타입 이해 -3(dict)
dict : 키와 값을 갖는 데이터 구조
dictionary는 순서가 없고 index가 없다.
a = {}
key , value를 복수개를 가지고 있다.
기존에 키가 존재하면 , 새로운 값으로 업데이트
존재하지 않으면 , 추가
동일한 키가 중복으로 두개 있을 수 없다.
value는 여러개 있을 수 있다.
update() 두 딕셔너리를 병합함
겹치는 키가 있다면 parameter로 전달되는 키 값이 overwrite된다.
key 삭제
del 키워드 사용 범용적으로 사용할 수 있다.
pop 함수 이용
a.pop('b')
del a['b']
c = 100
del c
print(c) => undefined
딕셔너리의 모든 값을 초기화
clear()
변수명.clear()
in
key값 존재 확인
O(1) 연산
'b' in a
in keyword는 기능이 매우 중요하다.
in list, dict 두개 다 가능하다.
a.get('d') ->값이 없어도 오류가 안난다.
a['d']
if 'd' in a:
print(a['d'])
keys() 키만 반환
values() 값만 반환
items() 키, 값의 튜플을 반환
list(a.items())
컬렉션 타입 이해 -3(set)
set은 거의 사용할 일이 없다.
중복이 안되고 순서가 없는
indexing이 없다. 순서가 없다. 오류가 없다. indexing이 없는 것은 순서가 없다는 것이다.
a = set()
a={}=>이런식으로 할 수 없다.
b = set(a)
print(b) =>중복이 허용 되지 않는다.
a = {1,2,3}
b = {2,3,4}
print(a.union(b)) #합집합
print(a.intersection(b)) #교집합
print(a.difference(b)) #차집합
print(a.issubset(b)) #부분 집합 
'교육동영상 > 01. 딥러닝인공지능' 카테고리의 다른 글
| 06. 이미지 분석 tensorflow 2.0 (0) | 2020.11.25 |
|---|---|
| 05. Tensorflow 2.0 Pytorch (0) | 2020.11.24 |
| 04. 인공지능에 대한 개념과 준비 (0) | 2020.11.23 |
| 03. python 함수 (0) | 2020.11.19 |
| 02. python 조건문, 반복문 (0) | 2020.11.19 |