데이터베이스 개론
데이터베이스
rdbms 많이 사용하고
NoSQL -> 새로운 기술에 인력소요가 많기 때문에
oracle-> 가장 강력한 데이터베이스
db2
sap 의 사이베이스나 하나db
하나db-> 많은 양의 데이터 읽는뎅 강하다.
orcle-> 많은 양의 데이터 쓰기에 강하다.
티맥스 tibero->
비밀버호 1234
mysql, maria db
java
페도라 ->centos->redhat
관계형 데이터베이스를 구성하는 용어
릴레이션(Relation) : 정보저장의기본형태가2 차원구조의테이블
속성(attribute) : 테이블의각열을의미 ->coloumn filed
도메인(Domain) : 속성이가질수있는값들의집합 -> 하나의 컬럼이 가질 수 있는 값의 집합 -> 자료형-> 제약조건도 포함
->업무에 관련된 것도 도메인이다.
->도메인 지식이 중요하다.
튜플(Tuple) : 테이블이한행을구성하는속성들의집합 -> 레코드 row
카디널리티(Cardinality) : 서로다른테이블사이에대응되는수- 내 데이터 하나에 몇개 연결되여있는가
키(key) 하나의 행을 구분할 수 있는 것들
-> 릴레이션을구성하는각튜플들을데이터값들에의해유일하게식별할수있는속성또 는속성의집합
후보키(Candidate Key) -> 최소의 키로 구분할수 있는것 예: 학번
-> 릴레이션의한속성집합(K) 이릴레이션이전체속성집합A 의부분집합이면서유일 성(uniqueness) 과최소성(minimality) 을만족하는속성또는속성의집합(K)
기본키(PimaryKey) 후보키중에서 개발자가 선정하는 것 테이블에 하나만 가능하다.
하나만 가능한 것인지 하나의 속성으로 할 필요 없다.
-> 후보키중에서선정한키로릴레이션의튜플들을유일하게식별할수있는키
필수는 아니지만 하는 게 좋다.
pk ->index 가 생성된다. 조회 빠르게 된다. 구분하기 위해서
대체키(Alternate Key)
기본키를제외한나머지후보키(Candidate Key)
외래키(Foreign Key)
다른테이블의행을식별할수있는속성
다른테이블에서는기본키이거나유일한값을갖는속성
제약조건
개체무결성(Entity Inetgrity)
기본키는null 이거나중복될수없음
참조무결성(Referential Intigrity)
릴레이션은 참조할수없는외래키의값을가져서는안됨
외래키의값은다른테이블에존재하는값이거나null 이어야함
NoSQL 이무엇의약자인지는No SQL, Not Only SQL, Non-Relational Operational Database
SQL 로엇갈리는의견들이있습니다만, 현재Not Only SQL 로풀어설명하는것이다수를차지
NoSQL 분류 ->dict map
Key Value DB: Key 와Value 의쌍으로데이터가저장되는가장단순한형태의솔루션으로 Amazon 의Dynamo Paper 에서유래되었으며Riak, Vodemort, Tokyo 등
Wide Columnar Store: Big Table DB 라고도하며Google 의BigTablePaper 에서유래되었 으며Key Value 에서발전된형태의Column Family 데이터모델을사용하고있고HBase, Cassandra, ScyllaDB 등->windows 에서 안됨 linux 등에서 가능
Document DB: Lotus Notes 에서유래되었으며, JSON, XML 과같은Collection 데이터모 델구조를채택하는형태로MongoDB, CoughDB 등
Cassandra ->java 로 만들었다.
MongoDB->c++ 기반으로 되여있다.
Graph DB: Euler & Graph Theory 에서유래한DB 로Nodes, Relationship, Key-Value 데이 터모델을채용하는형태인데Neo4J, OreientDB 등
기존의 관계형 등 여러가지 많이 사용한다.
Oracle 은 보통 linux unix. Mac 에서 설치되지 않는다.windows 에서 불안전하다.
Mac 은 서버쪽 관련 공부하는 것이 안좋아서 container 우에 깔아야 한다.
9i ->internet
10g, 11g->grid
12c ->cloud
Sid 가
Orcl(enter prise)
Xe(expre )-> 비밀번호만 여는 것
서비스에 가서
저장소 xe
원본을 사용하는 것이 아니다. 저장소에서 한다.
Sqlplus-> 원본을 사용한다.
Sqldeveloper 는 java 가 있어야 한다.
dbbeaver 유료버전은 mongodb 등 접속가능하다.
Os authen 아이디 비밀번호 없는 것이다.
어디에 있는 것인가 ?
System
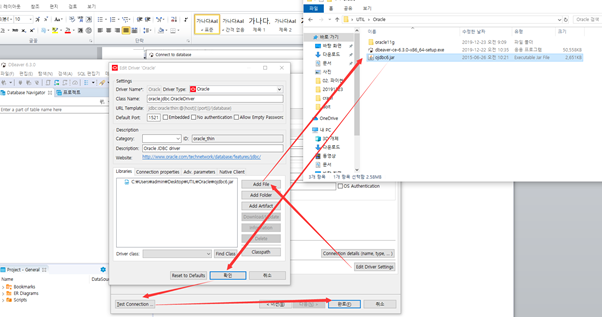
Driver 는 oracle 과 툴
driver 혹은 interface 이다.
사용자가 없어서 만들어줘야 한다.
--USER 추가
CREATE USER scott IDENTIFIED BY tiger ;
ALTER USER scott DEFAULT TABLESPACE USERS ;
ALTER USER scott TEMPORARY TABLESPACE TEMP ;
GRANT CONNECT , DBA, RESOURCE TO SCOTT ;
;-> 한명령어를 여기까지 한번에 해주세요
Set -> 데이터가 7 ,9 ,14
List 는 순서데로 저장한다. 없는 데이터 찾는데 오래 걸린다. 다 검색해야 한다.
Set 는 7 을 열경우 계산한다. 3 으로 나눈 나머지 가지고 저장해야 한다.
0 ,1 , 2-> 이런석으로 해서 bucket 에 나눈다. 중복은 안된다.hash 로 한다.
찾는데 걸리는 시간이 같다.
시노님 : 개체에 대한 별명 -> 별명을 한다.
식별하기 좋게 한다. 알아보기 쉽게 유지보수 하기 쉽게 위해서
오라클 시퀸스는 좀더 강력하다.
Index 대상을 빨리 찾기 위해서 한다.
우리는 순서데로 옇지만 index 한다. index 가지고 빠르게 찾는다.
Function 은 return 하는데
Procedure 은 return 이 필요없다. 일만 하면 된다. Plsql
package 묶어 논다.
PL/SQL (Procedural Language/Structured Query Language)
은 SQL 과 관계형 데이터베이스 ( 오라클 ) 를 위한 오라클 사의 절차적인 확장 언어이다 . Transact-SQL (T-SQL)
은 마이크로소프트 사와 사이베이스 사 소유의 SQL 확장 언어이다 . Transact-SQL 은 SQL Server 를 사용하기 위해 중심이 된다 . 모든 어플리케이션은 사용자 인터페이스에 개의치 않고
Transact-SQL 구문을 서버로 전송함으로써 SQL Server 의 인스턴스와 통신한다 . trigger 삭제 할 때 탈퇴 등 관련하여 가입시 여기 확인해서 탈퇴시 여기 가입해야한다.
명령어를 하나의 것으로 해야한다. 이것을 사용하는 것이 transaction 이다.
특정한 날짜에만 사용못하게 하세요 ->trigger 를 한다.
명령어 실행 못하게 끔 하는 것
SQL(Structured Query Language)
SEQUEL(Structured English QUeryLanguage)
SQL 은비절차적
대화식언어로사용가능
다른종류의범용프로그래언어로작성된프로그램에내장(embed) 시킨형태로도 사용가능
각각의튜플단위가아니라튜플들을집합단위로처리
반복문으로 하는것이다.
데이터 분석의 데이터는 vector 데이터 이다.
R 은 통계학자 return.
분석 -> 읽기 전용
python 은 프로그래머 읽기 쓰기 전용
dql 데이터 읽기만 하는 것
7. SQL
D 이-> 데이터 관리 하는 분만 한다.
로그아웃 하면서 하는 것이 복사본에 저장한다.
Show user
Conn scott/tiger;
--DROP TABLE DEPT;
CREATE TABLE DEPT
(DEPTNO NUMBER ( 2 ) CONSTRAINT PK_DEPT PRIMARY KEY ,
DNAME VARCHAR2 ( 14 ) ,
LOC VARCHAR2 ( 13 ) ) ;
--DROP TABLE EMP;
CREATE TABLE EMP
(EMPNO NUMBER ( 4 ) CONSTRAINT PK_EMP PRIMARY KEY ,
ENAME VARCHAR2 ( 10 ),
JOB VARCHAR2 ( 9 ),
MGR NUMBER ( 4 ),
HIREDATE DATE ,
SAL NUMBER ( 7 , 2 ),
COMM NUMBER ( 7 , 2 ),
DEPTNO NUMBER ( 2 ) CONSTRAINT FK_DEPTNO REFERENCES DEPT) ;
INSERT INTO DEPT VALUES
(10 , 'ACCOUNTING' , 'NEW YORK' ) ;
INSERT INTO DEPT VALUES ( 20 , 'RESEARCH' , 'DALLAS' ) ;
INSERT INTO DEPT VALUES
(30 , 'SALES' , 'CHICAGO' ) ;
INSERT INTO DEPT VALUES
(40 , 'OPERATIONS' , 'BOSTON' ) ;
INSERT INTO EMP VALUES
( 7369 , 'SMITH' , 'CLERK' , 7902 , to_date ( '17-12-1980' , 'dd-mm-yyyy' ), 800 , NULL , 20 ) ;
INSERT INTO EMP VALUES
( 7499 , 'ALLEN' , 'SALESMAN' , 7698 , to_date ( '20-2-1981' , 'dd-mm-yyyy' ), 1600 , 300 , 30 ) ;
INSERT INTO EMP VALUES
( 7521 , 'WARD' , 'SALESMAN' , 7698 , to_date ( '22-2-1981' , 'dd-mm-yyyy' ), 1250 , 500 , 30 ) ;
INSERT INTO EMP VALUES
( 7566 , 'JONES' , 'MANAGER' , 7839 , to_date ( '2-4-1981' , 'dd-mm-yyyy' ), 2975 , NULL , 20 ) ;
INSERT INTO EMP VALUES
( 7654 , 'MARTIN' , 'SALESMAN' , 7698 , to_date ( '28-9-1981' , 'dd-mm-yyyy' ), 1250 , 1400 , 30 ) ;
INSERT INTO EMP VALUES
( 7698 , 'BLAKE' , 'MANAGER' , 7839 , to_date ( '1-5-1981' , 'dd-mm-yyyy' ), 2850 , NULL , 30 ) ;
INSERT INTO EMP VALUES
( 7782 , 'CLARK' , 'MANAGER' , 7839 , to_date ( '9-6-1981' , 'dd-mm-yyyy' ), 2450 , NULL , 10 ) ;
INSERT INTO EMP VALUES
( 7788 , 'SCOTT' , 'ANALYST' , 7566 , to_date ( '13-7-1987' , 'dd-mm-yyyy' )- 85 , 3000 , NULL , 20 ) ;
INSERT INTO EMP VALUES
( 7839 , 'KING' , 'PRESIDENT' , NULL , to_date ( '17-11-1981' , 'dd-mm-yyyy' ), 5000 , NULL , 10 ) ;
INSERT INTO EMP VALUES
( 7844 , 'TURNER' , 'SALESMAN' , 7698 , to_date ( '8-9-1981' , 'dd-mm-yyyy' ), 1500 , 0 , 30 ) ;
INSERT INTO EMP VALUES
( 7876 , 'ADAMS' , 'CLERK' , 7788 , to_date ( '13-7-1987' , 'dd-mm-yyyy' ), 1100 , NULL , 20 ) ;
INSERT INTO EMP VALUES
( 7900 , 'JAMES' , 'CLERK' , 7698 , to_date ( '3-12-1981' , 'dd-mm-yyyy' ), 950 , NULL , 30 ) ;
INSERT INTO EMP VALUES
( 7902 , 'FORD' , 'ANALYST' , 7566 , to_date ( '3-12-1981' , 'dd-mm-yyyy' ), 3000 , NULL , 20 ) ;
INSERT INTO EMP VALUES
( 7934 , 'MILLER' , 'CLERK' , 7782 , to_date ( '23-1-1982' , 'dd-mm-yyyy' ), 1300 , NULL , 10 ) ;
--DROP TABLE SALGRADE;
CREATE TABLE SALGRADE
( GRADE NUMBER ,
LOSAL NUMBER ,
HISAL NUMBER ) ;
INSERT INTO SALGRADE VALUES ( 1 , 700 , 1200 ) ;
INSERT INTO SALGRADE VALUES ( 2 , 1201 , 1400 ) ;
INSERT INTO SALGRADE VALUES ( 3 , 1401 , 2000 ) ;
INSERT INTO SALGRADE VALUES ( 4 , 2001 , 3000 ) ;
INSERT INTO SALGRADE VALUES ( 5 , 3001 , 9999 ) ;
COMMIT ;
SELECT * FROM DEPT ;
SELECT * FROM EMP ;
SELECT * FROM SALGRADE ;
@script 파일 명령어 쓰면 된다.
@ 하고 sql 관련 내용을 땡기면 된다.
DESC dept ; --ORA-00900: invalid SQL STATEMENT
--dbeaver 에서 안된다 . 왜냐하면 현제것 보여주기때문에
SELECT * FROM show_user ;# SELECT * FROM show_user ;
--dbeaver 에서 사용안한다 .
-- 색갈이 다른것은 제약어이다 .
오라클 대문자
Mysql 소문자. Ibatis
3 장 select
1. 기본적인Select
From -> where->condition ->Select ->order by
1bytes 10bytes
1 이면 null
0 이면 not null
Nvl() 로 준다.
Null+ 숫자 à null 이다.
LITERAL 정해진 값 집여 옇기 사용자가 입력한 상수 ‘a’
숮자 안쓰고
문자 날짜 ‘’
Null 은 그냥 쓴다.
Constant ready only 변수 a= 10 a
Const a = 10 -> 수정불가
Distinct 는 전체 영향을 준다.
한번밖에 못 쓴다.
곱하기 * 이것이다. X 가 아니다.
And 앞에것 거짓이면 뒤에것 안한다.
%3 == 0 and %4 ==0
%4 == 0 and %3 ==0-> 이것으로 하는게 좋다. 뒤에것 안해도 되기 때문에
and 앞에것 거짓이 확률이 높은 것
or 앞에것 참인 확률이 높은 것
WHERE 절의 연산자
BETWEEN A AND B : A 과 B 사이 (A 와 B 포함)
NOT BETWEEN A AND B:A 와 B 사이가 아닌
SELECT *
FROM EMP e ;
-- 특정 클럼만 조회
--emp 테이블에서 empno 와 ename 을 조회
SELECT EMPNO,ENAME
FROM EMP e ;
-- 컬럼 별명 부여
SELECT EMPNO AS 사원번호
, ENAME AS 사원이름 -- 벌명에 영문 대문자가 있으면 "" 안에 기제
FROM EMP e
---23 페이지
--EMP 테이블의모든데이터를조회
SELECT *
FROM emp ;
--EMP 테이블에서중복되지않는 deptno 를조회
SELECT DISTINCT deptno
FROM EMP e ;
--EMP 테이블의 ename 과 job 를연결하여조회
SELECT ENAME || ' ' ||JOB
FROM EMP e ;
-- 날짜도 숫자이기 때문에 크기 비교가능
--EMP 테이블에서 HIRDATE 가 1982 년 1 월 1 일 부터 1982 년 12 월 31 일 인 데이터의 HIREDATE 를 조회
-- 날짜는 일반적인 형식의 문자열로 작성이 가능
SELECT ENAME,HIREDATE
FROM EMP e
WHERE HIREDATE BETWEEN '1982/01/01' AND '1982/12/31' ;
--sal 의 값이 1000-3000 사이
SELECT ENAME, SAL
FROM EMP e
WHERE SAL BETWEEN 1000 AND 3000 ;
--in ( 목록 )
-- 보통은 or 로 대체가 가능하지만 subquery 에서는 or 로 대체가 안됨
--emp table 에서 jobdl clerk 또는 salesman 인 데이터의 모든 컬럼을 조회
SELECT *
FROM EMP
WHERE JOB IN ( 'CLERK' , 'SALESMAN' )
--like
-- 패턴에 일치하는 데이터를 조회할 때 사용
--2 개의 wild card 문자를 이용
--% 글자 수와 상관없이 매칭
--_ 1 글자와만 매칭
--%A% A 가 포함됨
--%A A 가 끝나는
--A% A 로 시작하는
--_A A 로 끝나는 2 글자
--WILD CARD 문자를 조회하는 경우
--_ 를 포함함
--LIKE '%\_%' escape '\':\ 다음에 나오는 글자는 하나의 문자로 해석 있는 거데로 인식하라
--hiredate 가 1982 년 인 데이터의 ename 과 hiredate 를 조회
--HIREDATE 가 12 월인 데이터의 ENAME 과 HIREDATE 를 조회
SELECT ename,hiredate
FROM EMP e
WHERE HIREDATE LIKE '___12%' ;
--yy/MM/dd
--___01%
--___01___
--NULL 조회 IS NULL,IS NOT NULL
-- NULL 로 조회하게 되면 입력된 데이터가 'NULL' 인 데이터를 조회
SELECT ENAME,COMM
FROM EMP e
WHERE COMM = NULL ;
SELECT ENAME,COMM
FROM EMP e
WHERE COMM IS NULL ;
-- = NULL 에 대신 IS NULL 로 조회
-- AND 와 OR 사용시 주의점
-- AND 는 앞쪽의 조건이 FALSE 이면 뒤의 조건을 확인하지 않습니다 .
-- OR 는 앞쪽의 조건이 TRUE 이면 뒤의 조건을 확인하지 않습니다 .
-- AND 와 OR 를 사용할 떄는 조건을 확인해서 AND 의 앞쪽에 FALSE 일 가능성이 높은 조건을 배치하고 OR 의 경우에는 TRUE 일 가능성이 높은 조건을 치 하는 것이 좋습니다 .
-- AND 와 OR 가 같이 사용될 때는 AND 의 우선순위가 높습니다 .
-- A OR B AND C:(B 이고 C 인 데이터 ) 또는 A 인 데이터로 해석
-- OR 의 우선순위를 높일려면 괄호를 해야 합니다 . (A OR B) AND C
-- ORDER BY
-- SELECT 구문의 결과를 정렬하기 위한 절
-- SELECT 의 가장 마지막 절이고 마지막으로 수행됩니다 .
-- 2 개 이상의 데이터를 조회하는 경우 해주는 것이 좋습ㄴ디ㅏ .
-- 관계형 데이터베이스에 데이터를 저장하게 되면 데이터의 순서는 데이터베이스가 결정합니다 .
-- 입력 순서와는 무관하게 저장됩니다 .
-- 사용형식
-- ORDER BY 컬럼이름 [ASC|DESC],컬럼이름 [ASC|DESC]
-- ASC ->DEFUALT( 작은 것에서 큰 것 순으로 ) 오름차순
-- DESC -> 내림차순 ( 큰 것에서 작 것 순으로 )
-- 컬럼이름 대신에 SELECT 에서 만든 별명 사용가능
-- SELECT 에서의 INDEX 를 사용해도 가능 ( 데이터베이스에서는 인덱스가 1 부터 시작 )
-- 컬럼이름을 2 개 이상 사용하면 앞의 데이터 값이 동일할 때 적용
-- 컬럼 이름 대신에 연산식도 가능하다 .
--EMP 테이블의 모든 데이터를 조회
--HIREDATE 의 오름차순으로 정렬
SELECT EMPNO,ENAME,JOB,MGR,HIREDATE 입사일 ,SAL, COMM, DEPTNO
FROM EMP e
ORDER BY HIREDATE ;
SELECT EMPNO,ENAME,JOB,MGR,HIREDATE 입사일 ,SAL, COMM, DEPTNO
FROM EMP e
ORDER BY 입사일 ;
SELECT EMPNO,ENAME,JOB,MGR,HIREDATE,SAL, COMM, DEPTNO
FROM EMP e
ORDER BY 5 ;
--DEPTNO 의 내림차순 정렬하고 동일한 값이면 EMPNO 의 오름차순으로 정렬
SELECT *
FROM EMP
ORDER BY DEPTNO DESC , EMPNO ;
--SELECT 구문
--SELECT -5
-- FROM -1
-- WHERE -2
-- GROUP BY -3
-- having -4
-- ORDER BY -6
--select 와 from 은 필수 이다 .
--1.EMP 테이블에서 sal 이 3000 이상인사원의 empno, ename, job, sal 을조회하는 SELECT 문장을 작성
SELECT EMPNO,ENAME,job,SAL
FROM EMP e
WHERE sal >= 3000 ;
-- 결과는 SCOTT,KING,FORD
--2.EMP 테이블에서 empno 가 7788 인사원의 ename 과 deptno 를조회하는 SELECT 문장을작성
SELECT ENAME,DEPTNO
FROM EMP e
WHERE EMPNO = 7788 ;
-- 결과는 SCOTT
--3.EMP 테이블에서 hiredate 가 1981 년 2 월 20 일과 1981 년 5 월 1 일사이에입사한사원의 ename, job, hiredate 을조회하는 SELECT 문장을작성 ( 단 hiredate 순으로조회 )
--1).
SELECT ENAME,JOB, HIREDATE
FROM EMP e
WHERE HIREDATE BETWEEN '1981/02/20' AND '1981/05/01'
ORDER BY hiredate ;
--2).
SELECT ENAME,JOB, HIREDATE
FROM EMP e
WHERE HIREDATE >= '1981/02/20' ; --13
SELECT ENAME,JOB, HIREDATE
FROM EMP e
WHERE HIREDATE <= '1981/05/01' ; --5
SELECT ENAME,JOB, HIREDATE
FROM EMP e
WHERE HIREDATE <= '1981/05/01' AND HIREDATE >= '1981/02/20' ;
-- 4.EMP 테이블에서 deptno 가 10, 20 인사원의모든정보를조회하는 SELECT 문장을작성 ( 단 ename 순으로조회 )
SELECT *
FROM EMP e
WHERE DEPTNO IN ( '10' , '20' )
ORDER BY ENAME ;
-- 5.EMP 테이블에서 sal 이 1500 이상이고 deptno 가 10, 30 인사원의 ename 과 sal 를조회하는 SELECT 문장을작성 ( 단 HEADING 을 employee 과 Monthly Salary 로조회 )
SELECT ENAME employee, SAL "Monthly Salary"
FROM EMP
WHERE SAL >= 1500 ; --8
SELECT ENAME employee, SAL "Monthly Salary"
FROM EMP
WHERE DEPTNO IN ( '10' , '30' ) ; --9
SELECT ENAME employee, SAL "Monthly Salary"
FROM EMP
WHERE SAL >= 1500
AND DEPTNO IN ( '10' , '30' ) ;
-- 6.EMP 테이블에서 hiredate 가 1982 년인사원의모든정보를조회하는 SELECT 문을작성
SELECT *
FROM EMP e
WHERE HIREDATE LIKE '82%' ;
-- 50 페이지
-- 1.EMP 테이블에서 MGR 인 NULL 인사원의 ename 과 job 컬럼을조회
SELECT ENAME, JOB
FROM EMP e
WHERE MGR IS NULL ;
-- 2.EMP 테이블에서 COMM 이 NULL 이아닌사원의모든정보를조회하는 SELECT 문을작성
SELECT *
FROM EMP e
WHERE COMM IS NULL ;
-- 3.EMP 테이블에서 comm 이 sal 보다 10% 이상많은사원에대하여 ename, sal, comm 를조회하 는 SELECT 문을작성
SELECT *
FROM EMP E
WHERE COMM IS NOT NULL
AND COMM >= (SAL * 1 . 1 ) ;
-- 4.EMP 테이블에서 job 이 CLERK 이거나 ANALYST 이고 sal 이 1000, 3000, 5000 이아닌사원의모 든정보를조회하는 SELECT 문을작성
SELECT *
FROM EMP e
WHERE JOB IN ( 'CLERK' , 'ANALYST' ) ; --6
SELECT *
FROM EMP e
WHERE SAL NOT IN ( '1000' , '3000' , '5000' ) ; --11
SELECT *
FROM EMP e
WHERE JOB IN ( 'CLERK' , 'ANALYST' )
AND SAL NOT IN ( '1000' , '3000' , '5000' ) ;
-- 5.EMP 테이블에서 ename 에 A 와 E 를모두포함하고있는사원의 ename 과 sal 을조회
SELECT ENAME, SAL
FROM EMP e
WHERE (ENAME LIKE '%A%' ) ; -- 7
SELECT ENAME, SAL
FROM EMP e
WHERE (ENAME LIKE '%E%' ) ; --6
--A 와 E 를모두포함
SELECT ENAME, SAL
FROM EMP e
WHERE (ENAME LIKE '%E%' ) AND (ENAME LIKE '%A%' ) ;
-- 6.EMP 테이블에서 (ename 에 L 이두자이상이포함되어있고 deptno 가 30) 이거나 mgr 이 7566 인사원의모든정보를조회하는 SELECT 문을작성
--ename 에 L 이두자이상
SELECT *
FROM EMP e
WHERE ENAME LIKE '%L%L%' ; --2
--deptno 가 30
SELECT *
FROM EMP e
WHERE deptno IN ( '30' ) ; --6
--mgr 이 7566
SELECT *
FROM EMP e
WHERE MGR = '7566' ;
SELECT *
FROM EMP e
WHERE ENAME LIKE '%L%L%'
AND deptno IN ( '30' )
OR MGR = '7566' ;
** 오라클 제공함수
1. 함수 분류
1). 단일 행 함수 : 하나의 행에 적용되는 함수
2). 다중 행 함수 : 0 개 이상의 행에 적용되는 함수
2. dual 테이블
=> 오라클에서 제공하는 가상의 테이블
=> 실제 데이터를 저장할 목적이 아니라 연산의 결과나 확인 등을 하기 위한 테이블
=>select 구문에서 from 이 없으면 에러가 발생하는데 오늘날짜 같은 데이터는 실제 테이블에 존재하는 데이터가 아닙니다.
오늘 날짜 확인
Select sysdate
From dual;
3. 숫자 관련 함수
=>ABS( 절대값), COS, EXP( 지수), FLOOR( 올림), LOG( 로그),POWER,SIGN, TAN, ROUND( 반올림),TRUNC( 올림), MOD
ROUND( 데이터[, 자릿수]): 자릿수가 없으면 소수 첫째 자리에서 반올림 – 정수로 리턴
자릿수를 적으면 그 자리 뒤에서 반올림해서 리턴
자릿수를 음수를 적으면 정수부분에서 반올림을 합니다.
-1: 1 의 자리 반올림
-2: 10 의 자리 반올림
--EMP 테이블에서 입사 한 후 몇칠을 근무했는지 조회
SELECT ENAME, ROUND ( SYSDATE - HIREDATE, 2 ) AS 근무일수
FROM EMP e ;
SELECT ENAME, ROUND ( SYSDATE - HIREDATE,- 2 ) AS 근무일수
FROM EMP e ;
--14250.72 ->14300
SELECT ENAME, TRUNC ( SYSDATE - HIREDATE,- 2 ) AS 근무일수
FROM EMP e ;
SELECT ENAME, FLOOR ( SYSDATE - HIREDATE) AS 근무일수
FROM EMP e ;
4. 대소문자 관련 함수
UPPDER: 모두 대문자로 변경
LOWER: 모두 소문자로 변경
INITCAP: 단어의 첫글자만 대문자로 변경
영문 조회할 때는 대소문자 관련 부분을 고려
iOS,iPhone
Select ename,sal
From emp
Where job= ‘manager’;
Select ename,sal
From emp
Where lower(job)= ‘manager’;
Select ename,sal
From emp
Where UPPER(job)= ‘MANAGER;
encoding: 데이터를 컴퓨터에 저장하는 형태로 변경하는 것
Decoding: 컴퓨터에 저장된 데이터를 출력하기 위한 형태로 변경하는 것
영문은 전세계 모든 코드 체계에서 동일한 방식으로 인코딩과 디코딩을 수행
A->65
a->97
한글은 ms949(cp949),euc-kr,utf-8 방식의 인코딩이 있습니다.
ms949: ms-windows 인코딩 방식 한글 한글자가 2byte
euc-kr: 예전 웹에서 한글을 표현하기 위한 인코딩 방식 한글자가 2byte
utf-8: 전 세계 모든 문자를 표현하기 위한 인코딩 방식 한글자가 3byte
다른 인코딩 방식으로 인코딩 된 데이터를 읽으면 제대로 디코딩을 못하기 때문에 글자가 깨집니다.
오픈 소스들에서는 기본 인코딩이 .iso-8859-1(iso latin 1) 으로 되어 있는 경우가 많은데 이 방식에서는 한글 표현이 안됩니다.
mysql 은 기본이 iso-8859-1 이기때문에 한글 사용불가하다.
그래서 “utf-8” 로 지정해야 한다.
b ->byte 오라클 3byte 인데 byte 로 하면 9byte 이다.
substr 문자 수 가지고
substrb 는 byte 수로 해야 한다 . 한글자에 에 3byte
한글은 2 혹은 3 으로 되여있다.