3.3 파일과 운영체제
f= open()
줄끝 end-of-line EOL
f.close()
파일을 읽을 떄는 read,seek,tell메서드를 주로 사용하게 되는데 read메서드는 해당 파일에서 특정 개수만큼의 문자를 반환한다.
with open(path) as f:
lines = [x.rstrip() for x in f]
read메서드는 읽은 바이트만큼 파일 핸들의 위치를 옮긴다.
tell메서드는 현재 위치를 알려준다.
seek 메서드는 파일 핸들의 위치를 해당 파일에서 지정한 바이트 위치로 옮긴다.
파일의 텍스트를 기록하려면 write나 writelines메서드를 이용하면 된다.
3.3.1 바이트와 유니코드
b를 추가해서 열 수 있는 이진 모드와는 다르다.
UTF-8 인코딩을 사용하는 비-아스키 문자가 포함된 파일
04. NumPy 기본: 배열과 벡터 연산
Numpy는 Numerical Python의 줄임말
파이썬에서 산술 계산을 위한 가장 중요한 필수 패키지 중 하나다.
효율적인 다차원 배열인 ndarray는 빠른 배열 계싼과 유연한 브로드캐스팅 기능 제고
반복문을 작성할 필요 없이 전체 데이터 배열을 빠르게 계ㅆ산할 수 있는 표준 수학 함수
배열 데이터를 디스크에 쓰거나 읽을 수 있는 도구와 메모리에 적재된 파일을 다루는 도구
선형대수, 난수 생성기, 푸리에 변환 기능
c,c++ ,포트란으로 작성한 코드를 연결할 수 있는 C API
Numpy의 C API는 사용하기 쉬우므로 저 수준 언어로 작성된 외부 라이브러리에 데이터를 전달하거나 반대로 외부 라이브러리에서 NumPy 배열 형태로 파이썬에 데이터를 전달하기 용이하다.
Numpy 배열 과 배열 기반 연산에 대한 이해를 한 다음 pandas 같은 배열 기반 도구를 사용하면 휠씬 더 효율적이다.
Numpy는 일반적인 산술 데이터 처리를 위한 라이브러리를 제공하기 떄문에 많은 독자가 통계나 분석, 특히 표 형식의 데이터를 처리하기 위해 pandas를 사용하기 원할 것이다.
내장 파이썬의 연속된 자료형들 보다 휠씬 더 적은 메모리를 사용한다.
파이썬 반복문을 사용하지 않고 전체 배열에 대한 복잡한 계산을 수행할 수 있다.
numpy 휠씬 빠르다.
4.1 Numpy ndarray :다차원 배열 객체
Numpy 의 핵심 기능 중 하나는 ndarray 라고 하는 N차원의 배열 객체인데 파이썬에서 사용할 수 있든 대규모 데이터 집합을 담을 수 있는 빠르고 유연한 자료구조다.
배열은 스칼라 원소간의 연산에 사용하는 문법과 비슷한 방식을 사용해서 전체 데이터 블록에 수학적인 연산을 수행할 수 있도록 해준다.
import numpy as np
data = np.random.randn(2,3)
print(data)
산술 연산
print(data*10)
print(data+data)
from numpy import *
print(data.shape)
print(data.dtype)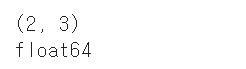
4.1.1 ndarray 생성하기
배열을 생성하는 가장 쉬운 방법은 array함수를 이용하는 것이다.
data1 = [6, 7.5, 8, 0,1]
arr1 = np.array(data1)
print(arr1)
data2 = [[1,2,3,4],[5,6,7,8]]
arr2 = np.array(data2)
print(arr2)
print(arr2.ndim)
print(arr2.shape)

print(np.zeros(10))
print(np.zeros((3,6)))
print(np.zeros((2,3,2)))

np.empty 는 0으로 초기화된 배열을 반환하지 않는다.
empty함수는 최기화되지 않은 배열을 생성한다.
최기화되지 않는 '가비지' 값으로 채워진 배열을 반환한다.
명시하지 않으면 float64(부동소수점) 가 될것이다.
4.1.2 ndarry의 dtype
dtype은 ndarray가 메모리에 있는 특정 데이터를 해석하기 위해 필요한 정보(또는 메타데이터)를 담고 있는 특수한 객체다.
arr1 = np.array([1,2,3], dtype = np.float64)
dtype로 type를 설정한다.
4.1.3 Numpy 배열의 산술 연산
배열의 중요한 특징은 for문을 작성하지 않고 데이터를 일괄 처리할 수 있다는 것이다.
백터화라고 하는데 , 같은 크기의 배열 간의 산술 연산은 배열의 각 원소 단위로 적용된다.
브로드캐스팅 : 크기가 다른 배열 간의 연산 broadcasting
arr[5:8].copy()를 사용해서 명시적으로 배열을 복사해야 한다.
슬라이스로 선택하기
4.1.5 블리언값으로 선택하기
numpy.random모듈에 있는 randn함수를 사용해서 임의의 표준 정규분포 데이터를 생성하자.
비교 연산 == 벡터화
!= 혹은 ~
4.1.6 팬시 색인
팬시 색인은 정수 배열을 사용한 색인을 설명하기 위해 Numpy에서 차용한 단어다.
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
print(arr)

arr[[4,3,0,6]]

-이면 끝으로 선택한다.
reshape 행렬의 행(로우) 과 열(컬럼)
4.1.7 배열 전치와 축 바꾸기
배열 전치는 데이터를 복사하지 않고 데이터의 모양이 바뀐 뷰를 반환하는 특별한 기능이다.
ndarray는 transpose메서드와 T라는 이름의 특수한 속성을 가지고 있다.
arr = np.arange(15).reshape((3,5))
print(arr)
print(arr.T)

행렬 계산을 할 떄 자주 사용되게 될 텐데 , np.dot
arr = np.random.randn(6,3)
print(arr)
print(np.dot(arr.T, arr))

arr = np.arange(16).reshape((2,2,4))
print(arr)
print(arr.transpose((1,0,2)))

swapaxes라는 메서드가 있는데 두 개의 축 번호를 받아서 배열을 뒤바꾼다.
print(arr)
print(arr.swapaxes(1,2))

swapaxes 도 마찬가지로 데이터를 복사하지 않고 원래 데이터에 대한 뷰를 변환한다.
'책 > python for Data Analysis' 카테고리의 다른 글
| 04-2. NumPy 기본: 배열과 벡터 연산 05. pandas 시작하기 (0) | 2021.01.31 |
|---|---|
| 04-1. NumPy 기본: 배열과 벡터 연산 (0) | 2021.01.31 |
| 03-2. 내장 자료구조, 함수 , 파일 (0) | 2021.01.26 |
| 02-2. 파이썬 언어의 기본, IPython, 주피터 노트북 03. 내장 자료구조, 함수 , 파일 (0) | 2021.01.26 |
| 02. 파이썬 언어의 기본,IPython,주피터 노트북 (0) | 2021.01.19 |