**Design Pattern
=>객체의 사용 용도에 따라 클래스를 디자인하는 것
1. 생성과 관련된 패턴
1)Singleton
=>인스턴스를 1개만 만들 수 있도록 클래스를 디자인 하는 것
=>관리자 클래스(Controller, Manager)나 애플리캐이션 전체가 공유해야 하는 공유 데이터를 갖는 클래스 또는 서버에서 클라이언트의 요청을 처리하는 클래스 등은 일반적으로 인스턴스를 1개만 만들어서 사용
=>java.lang.Runtime클래스가 이 패턴으로 디자인
2)Decorator Pattern (커피)
=>외부에서 데이터를 주입받아 인스턴스를 생성하는 구조
=>하는 일은 유사한데 일을 수행해야 하는 대상이 여러가지 종류일 때 사용하는 패턴
=>작업을 수행하는 대상을 클래스 내부에서 직접 생성하지 않고 외부에서 생성한 후 주입받는 형태의 구조
=>java.io.BufferedReader클래스가 Decoragor Pattern의 대ㅍ적인 예
BufferedReader는 문자 스트림에서 문자열을 읽어오는 스트림
new BufferedReader(new InputStreamReader(new FileInputStream(String filepath))); 파일에서 읽어오기
new BufferedReader(new InputStreamReader(Socket.getInputStream())); 소켓에서 읽어오기
new BufferedReader(new InputStreamReader(HttpURLConnection.getInputStream())); 웹에서 읽어오기
=>매개변수가 여러 개가 될 수 있습니다.
=>C++이나 JAVA는 생성자 오버로딩을 이용해서 구현하거나 매개변수로 대입되는 클래스의 다형성을 이용해서 구현
2.구조와 관련된 패턴
1)템플릿 메소드 패턴
=>메소드의 원형을 인터페이스(추상 클래스)에 선언하고 인터페이스를 구현한 클래스에 메소드를 구현하는 방식
c++은 인터페이스가 없고 추상클래스이다.
=>c나 c++(추상 클래스)는 인터페이스 대신에 헤더파일을 이용해서 구현
최근에는 이런 방식은 잘 사용되지 않음
스마트폰이나 게임해야 할때 조심해야 하는 부분
최근에 등장하는 GUI를 구현하는 언어들 중에도 파일을 2개로 나누어서 구현하는 경우가 있는데 이 경우는 디자인 파일과 구현 파일을 분리하는 형태잊 헤더 파일을 이용하는 형태가 아닙니다.
최근에는 INTERFACE, SWAFT등으로 작업한다.
=>프로그래밍을 할 때 사용자의 요청을 처리하는 클래스는 이 패턴으로 디자인 합니다.
이렇게 사용자의 요청을 처리하는 메소드를 소유한 클래스를 Service 클래스 라고 합니다.
데이터베이스 연동 프로그램에서 트랜잭션을 적용하는 지점은 Service 클래스의 메소드입니다.

=>어떤 Unit이라는 클래스를 설계하는데 사용자가 공격과 이동이라는 동작을 수행해야 합니다.
uml에서 확인

Interface mpl
classEx
int i
Controller controller =
소문자로 시작
변수
메소드
패키지
대문자로 시작
클래스
모두 대문자
상수
c언어 일 경우 macro는 대문자로 해라
numpy ndarray
pandas Series
python은 소문자로 시작했다 나중에 개발자들이 name을 사용하기 시작했다.
series() Series() 생성자
인터페이스 생성
//이 프로그램은 설계에 가깝다.
public interface Unit {
//공격을 수행하는 메소드
public void attack();
//이동을 수행하는 메소드
public void move();
//자바는 코드로 도여있지만 uml로 하면 알기 쉽다.
}
인터페이스를 구현한 class를 생성
public class UnitImpl implements Unit {
@Override
public void attack() {
System.out.println("공격");
}
@Override
public void move() {
System.out.println("이동");
}
}
main메소드를 만들어서 사용
public class UnitMain {
public static void main(String[] args) {
//탬플릿 메소드 패턴이 적용된 클래스의 인스턴스 만들기
//변수는 인터페이스 이름을 사용하고 생성자는 클래스 이름을 이용하는 형태로 많이 작성합니다.
UnitImpl unitImpl = new UnitImpl();
unitImpl.attack();
unitImpl.move();
List<String> list = new ArrayList<String>();
}
}

2)Adapter Pattern
=> 구현된 인터페이스를 이용해서 상속받은 클래스의 메소드를 호출하는 패턴
=>상속받은 클래스의 메소드를 직접 호출하기가 어려운 경우 이용
=>상속을 받았기 때무에 상위 클래스의 메소드를 호출해서 사용하는 것이 가능한데 상위 클래스의 메소드 이름을 다른 용도로 사용하는 경우 - 상위 클래스의 메소드의 내용을 변경해서 오버라이딩 하는 경우
=>원래 오버라이딩응ㄴ 상위 클래스의 메소드 기능을 확장하기 위해서 사용하는데 확장이 아니라 변경한 경우
=>Base 클래스 생성
public class OldSystem {
public void process() {
System.out.println("예전 처리");
}
}
=>Targe인터페이스 생성
public interface Target {
//OldSystem의 process 를 호출하기 위한 메소드
public void legacyProcess();
}
=>Derived 클래스 생성
public class NewSystem extends OldSystem implements Target{
@Override
public void process() {
//구현된 메소드의 오버러이딩 : 상위 클래스의 메소드를 호출하고 기능을 추가
/*
super.process();
System.out.println("기능 추가");
*/
System.out.println("새로운 기능");
}
//java는 예전것도 지원한다.
@Override
public void legacyProcess() {
super.process();
}
}
=>main메소드를 만들어서 실행
public class AdapterMain {
public static void main(String[] args) {
NewSystem newSystem = new NewSystem();
//새로 만들어진 메소드
newSystem.process();
//이전에 만들어진 메소드
newSystem.legacyProcess();
}
}
3)Composite Pattern
=>재귀적 구조를 쉽게 처리하기 위한 패턴
=>Recursive Call(Recursion- 함수가 내부에서 함수 자신을 다시 호출하는 경우)
=>파일 시스템에는 파일과 디렉토리가 있는데 디렉토리를 삭제할려고 하는 경우 디렉토리 안의 내용을 확인해서 디렉토리이면 다시 그 안에 있는 내용들을 삭제해야 합니다.
=>하나의 인터페이스를 만들고 인터페이스에 공통된 메소드 이름을 만들어주고 파일과 디렉토리 처리를 위한 클래스를 별도로 만들어서 처리하는 메소드를 구현합니다.
다형성을 구현하는 방식과 유사합니다.
=>인터페이스는 Entry- add와 remove그리고 rename
=>클래스는 File과 Directory로 생성
=>인터페이스 생성
//파일의 디렉토리 클래스에서 공통으로 사용할 메소드를 소유한 인터페이스
public interface Entry {
public void add(Entry entry);
void remove();//자기 자신을 지우는
void rename(String name);
}
=>File클래스 생성
public class File implements Entry {
//파일 이름을 저장할 변수
private String name;
public File(String name) {
this.name = name;//생성자로 부터 대입 받을 때
}
@Override
public void add(Entry entry) {
System.err.println("파일에는 파일이나 디렉토리를 추가할 수 없습니다.");
}
@Override
public void remove() {
System.out.println(name+"가 삭제 되였습니다.");
}
@Override
public void rename(String name) {
this.name = name;
}
}
=>Directory 클래스
public class Directory implements Entry {
private String name;
//FIle이나 Deriectory 를 소유할 수 있기 때문에 Entry를 여러 개 저장할 수 있는 자료구조를 소유
List<Entry> list;
public Directory(String name) {
this.name = name;
list = new ArrayList<Entry>();
}
@Override
public void add(Entry entry) {
list.add(entry);
}
@Override
public void remove() {
//list가 null이면 NullPointerException
//list가 인스턴스 생성은 되였는데 멤버가 없으면 수행을 안함
//Iterator 를 이용해서 데이터 접근
Iterator<Entry> iter = list.iterator();
while(iter.hasNext()) {
Entry entry = iter.next();
//file 은 지우지만 direcoty는 지우는 지 확인 해야 한다.
entry.remove();
}
System.out.println("내부 데이터는 전부 삭제 되였습니다.");
/*for(Entry entry: list) {
//디렉토리인지 확인해서 작업을 수행을 하지 않을 수 도 있습니다.
//FIle이 있으면 File의 remove를 호출하고 Directory이면 Direcoty의 remove를 호출 - 다형성(Polymoriphism)
//일반 다형성과 다른점은
//Direcotory는 file를 할 수있다 .. .list가 있어서
//이것 때문에 composite라고 한다.
//file 은 지우지만 direcoty는 지우는 지 확인 해야 한다.
entry.remove();
}*/
}
@Override
public void rename(String name) {
this.name = name;
}
}
=>main메소드를 만들어서 테스트
public class CompositeMain {
public static void main(String[] args) {
File f1 = new File("파일1");
File f2 = new File("파일2");
File f3 = new File("파일3");
Directory subDirectory = new Directory("하위 디렉토리");
subDirectory.add(f1);
subDirectory.add(f2);
Directory superDirectory= new Directory("상위 디렉토리");
superDirectory.add(subDirectory);
superDirectory.add(f3);
superDirectory.remove();
//자료형 이름 출력
System.out.println(superDirectory.getClass().getName());
Entry entry = new Directory("디렉토리");
System.out.println(entry.getClass().getName());
}
}
3.행동에 관련된 패턴
1)Command Pattern
=>처리 내용이 비슷한 명령을 모아서 실행하는 처리가 필요할 때 명령을 인스턴스로 취급해서 처리하는 패턴
=>데이터를 삽입하는 처리와 수정하는 처리가 필요한 경우
interface Action{
public void execute(DTO dto); //다형성 구현한 것 처럼 한다.
}
class InsertAction Implement Action{
public void execute(DTO dto){
오버라이딩 하고 삽입하는 크도
}
}
class updateAction Implement Action{
public void execute(DTO dto){
수정하는 크도
}
}
//action에 대입되는 인스턴스 자체가 명령어와 유사한 역할을 수행
Action action = null;
if(command == 삽입){
action = new insertAction();
}else if(command == 삭제){
action = new updateAction();
}
action.execute(dto);
=>이러한 패턴은 웹 서버의 Controller 클래스를 만들어서 요청에 따라 처리를 할 때 많이 사용
웹 서버 프로그래밍을 하다보면 URL에 따른 Routing구조를 만들 때도 이 구조를 이용합니다.
2)Observer Pattern
=>어떤 인스턴스의 내부 상태가 자주 변경되는 경우 내부 상태가 변경되는지를 감시하고 있다가 변경이 되면 알려줘서 처리를 할 수 있도록 해주는 패턴
=>알려준다고 해서 Notification이라는 표현을 많이 사용합니다.
=>이 패턴을 사용하는 대표적인 예가 스마트 폰의 뷰에서 키보드가 화면에서 보여지고 사라지는 것을 감시해서 뷰의 컴포넌트들을 재배치 하는 형태
3)Strategy Pattern
=>어떤 클래스가 공통된 부분이 있고 서로 다른 부분이 있는 경우 공통된 부분은 클래스 안에서 만들어 사용하고 서로 다른 부분은 외부에서 주입(Injection)받아 사용하는 패턴
public class Injection {
private String common;//모든 인스턴스들이 "Java"라고 저장해서 사용
private String diff1; //인스턴스들 마다 다름
private String diff2; //인스턴스들 마다 다름
public Injection(String diff1) {
common = "java";
//생성자를 이용한 주입
this.diff1 =diff1;
}
//diff2에 대한 setter메소드 - setter 나 getter를 소유한 인스턴스 변수를 property라고 합니다.
public void setDiff2(String diff2) {
this.diff2 = diff2;
}
//common 과 diff1은 null일 가능성이 없지만
//diff2는 setter 를 이용해서 대입받기 때문에 null일 가능성이 존재
//서버 프로그래밍을 할 때는 메모리 부담이 되더라도 처음부터 만들어두고 사용하는 것이 좋고
//클라이언트 프로그래밍을 할 떄는 속도가 느리더라고 필요할 때 생성하는 것이 좋습니다.
//서버에서 하는 것인지 클라이언트 ㅎ하는 지 완전히 다르다ㅏ.r은 메모리 부담이 많이 된다.
public void disp() {
System.out.println(common.toUpperCase());
System.out.println(diff1.toUpperCase());
System.out.println(diff2.toUpperCase());
}
}

public class InjectMain {
public static void main(String[] args) {
Injection injection = new Injection("JavaScript");
//다른 메소드들을 호출
//diff1을 가져고 다녀야 한다.
//다른 메소드들을 호출
injection.setDiff2("Spring");//사용하기 직전에 만들어서 사용한다. 메모리 절략은 되는데 속도가 느리다.
injection.disp();
//setDiff2를 호출하지 않았기 때문에 diff2가 null인 상태에서 toUpperCase를 호출해서 예외
injection = new Injection("FrontEnd");
injection.disp(); //java.lang.NullPointerException
}
}
=>Design Pattern은 하나의 클래스에 여러가지를 적용하기도 합니다.
=>Design Pattern의 개념은 절대적인 개념이 아니라서 개발자마다 약간씩 다르게 설명하기도 합니다.
Singleton, Template Method, Command Pattern은 모두 동일하게 설명합니다.
=>이외에도 인스턴스 생성을 대신해주는 Factory Method Pattern이나 개발자가 만든 클래스에 코드를 더해서 실제로는 개발자가 만든 클래스와 다른 형태의 인스턴스를 만들어내느느 Proxy Pattern 등도 있습니다.
=>객체지향 프로그래밍에서는 디자인 패턴이 중요합니다.
객체지향 프로그래밍 언어 문법 -> 자료구조&알고리즘 ->디자인패턴 ->SW공학(개발 방법론 ..)
C는 CLASS가 없다. 디자인패턴이 없다.
**외부로 부터 데이터를 방아서 사용하는 경우
=>주입을 받는 방법은 생성자를 이용하는 방법이 있고 프로포티(setter)를 이용하는 방법
생성자를 이용하는 방법은 처음부터 가지고 있기 때문에 NullPointerException이 발생할 가능성이 적지만 메모리에 부담이 되고 setter을 이용하는 방식은 사용하기 전에 주입받아서 사용하기 때문에 메모리를 절약할 수 있지만 항상 NullPointerExcetpion에 대비해야 합니다.
**데이터 저장 및 읽기
1.로컬이나 원격에 Flat file형태로 저장
=>text 형식 : txt, csv형식 -용량이 작다는 장점이 있지만 전체가 아닌 일부 검색은 어려움
=>xml,json형식 : 구격화된 포맷 형식 - 인간이 알아보기 쉬움, 인간이 직접 작성도 가능,사이즈가 커지면 용량도 커지고 알아보기도 어려워집니다.
설정 내용을 저장할 때 나 실시간으로 작은 용량의 데이터를 주고받을 때 이용
2. 별도의 저장 프로그램 이용
=>Database:앞의 방법 들보다 보안이 우수하고 검색 조건을 다양하게 설정할 수 있음 , 데이터이외이 많은 것들을 저장해야 하기 때문에 오버헤드가 큼 (돈이 많이 든다.)
비밀번호 보안예기 많이 나온다.
**관계형 데이터베이스 인 오라클 사용
1.프로그래밍 언어에서 관계형 데이터베이스를 사용하는 방법
1)언어가 제공하는 기능만을 이용해서 구현 - java의 경우는 jdbc그리고 윈도우는 odbc등
2)프레임워크를 이용해서 구형 - 언어가 제공하는 기능을 편리하게 사용할 수 있도록 만들어진 프레임워크 이용
-SQL Mapper: Java코드와 SQL을 분리해서 작성하는 구조 , Mybatis(iBatis가 예전 이름)(c#도 사용가능)가 대표적
=>성능은 떨어지지만 쉬워서 si(시스템 통합 - 기업의 전산화 , 외주를 많이 줌)에서 많이 사용
-Object Relation Mapper (ORM)
=>최근에 많이 사용하는 프레임워크로 하나의 행을 하나의 인스턴스와 매핑하는 프레임워크
하나의 테이블을 하나의 클래스와 매핑
데이터베이스에 대한 구조를 파악하고 있어야만 사용이 가능
어렵지만 성능이 우수해서 솔루션 제작에 많이 이용
Java의 JPA(구현체로는 Hibernate)가 대표적인 프레임워크 - 다른 언어에도 대부분 있음
카카오와 배민이 이것 사용하고 있다.
sql없이 데이터베이스 작업이 가능 - dbms를 변경해서 적용하더라고 설정파일만 수정하면 됩니다.
iBatis, MyBatis
MariaDB, MySQL
Fedora(테스트형), Cent OS(stable버전), Red Hat Enterprise(stable해서 사용화 버전 ) <->Ubuntu
sqlite ->autoincrement : sqlite의 일련번호
오라클 ->sequence nextval()
서비스를 작은 마이크로 서비스 단위로 만들고
2.java에서 관계형 데이터베이스 연동 방법
1)사용하고자 하는 데이터베이스와의 인터페이스를 제공하는 드라이버를 사용할 수 있도록 설정
=>자바는 드라이버를 build path에 추가하고 클래스를 로드

드라이브 사용하는 것은 프린트 서로 다른 것 통신해주기로 해서
python은 예외 sqlite3가 예외이다 드라이브에 lib에 있어서 할 필요없다.
pip install
2)데이터베이스 접속 정보를 가지고 데이터베이스 연결 객체(java.sql.Connection)를 생성
=>접속정보는 데이터베이스 URL, 포트번호 , 데이터베이스이름(오라클의 경우는 SID또는 serviceName)이 필요하고 접속계정과 비밀번호도 필요
=>데이터베이스 종류에 따라서 접속 계정과 비밀번호가 필요없는 경우가 있음
=>데이터베이스 중에는 자신의 기본 포트를 사용하는 경우 포트번호 생략이 가능(Mysql은 3306 포트인 경우 생략가능 )
=>자바의 경우는 연결 객체를 이용해서 트랜잭션 사용 방법을 설정합니다.
3)Connection을 이용해서 SQL을 주고받을 객체를 생성하고 실행 - Java는 Statement(완성된 sql) ,PreparedStatement(나중에 데이터를 매핑할 수 있는 sql - 대부분의 언어가 사용), CallableStatement (Procedure 실행)
4)결과를 사용
-select 를 제외한 구문 : 영향받은 행의 개수를 정수로 리턴
- select 구문 : select의 결과를 사용할 수 있는 Cursor를 리턴
5)트랜잭션 처리를 하고 사용한 객체를 close를 합니다.
6)java에서는 이 과정 전체가 예외처리를 강제합니다.
다른 언어에서 예외처리를 강제하지 않더라도 예외처리를 해주는 것이 좋습니다
문제가 발생하면 어떤 조치를 취할 수 있도록 해 주어야 합니다.
데이터베이스는 외부에 존재하는 경우가 많기 떄무에 어떤 문제가 발생할 지 우리가 예측할 수 없습니다.
3.애플리케이션 프로그램이 잘 수행하지 않는 sql
=>Grant(권한 부여), Revoke(권한 회수)
=>Create(개체 생성) ,Alter(개체 구조 변경), Drop(개체 삭제) ,Truncate(테이블의 데이터만 삭제), Rename(테이블의 이름 변경)
=>주로 관리자가 사용하는 sql명령들이고 이 명령들은 Rollback이 안됩니다.
관리자만 로컬에서 사용하는 애플리케이션을 만들어서 수행하도록 하는 경우는 종종 있습니다.
(원격으로 잘 안한다.)
4.데이터베이스 계정
ip:
PORT:1521
SID:xe
계정 : user01-user30
비번 : user01-user30
강사님 계정 user00
5.샘플 테이블을 생성
=>Oracle의 자료형
숫자는 - number(정수자릿수),number(전체자릿수 ,소수자릿수)
문자열 - char(글자수),varchar2(글자수), clob
한글은 곱하기 3
char를 사용하면 글자수보다 작은 양의 글자를 입력하면 뒤에 공백이 있습니다.
clob는 아주 많은 글자인 경우 사용
날짜 - date
=>거래정보 테이블
거래번호 - 정수이고 기본키, 일련번호 형식
품목코드 - 거래한 품목의 코드 , 문자열 20자리
품목명 - 거래한 품목이름 , 문자열 100자리
단가 - 정수 7자리
수량 - 정수 3자리
거래일 - 날짜
거래 id -거래한 유저의 id, 문자열 50자리
create table transactions(
num number(10) primary key,
itemcode varchar2(20),
itemname varchar2(100),
price number(7),
cnt number(3),
transdate date,
userid varchar2(50)
);
6. 프로젝트를 생성하고 오라클을 사용할 준비
=> 데이터베이스 드라이브를 프로젝트의 build path애 추가
오라클은 ojdbc>.jar
ojdbc6.jar :숫자의 의미는 자바 버전이고 이 이외의 숫자가 추가로 있으면 오라클 버전입니다.
상위버전은 하위버전을 지원
7.애플리케이션이 시작될 때 1번 드라이버 클래스를 로드
=>Class.forName("드라이버 클래스 이름"); //여기에 직접 쓰지 않는다.
=>실제 애플리케이션을 만들 때는 드라이버 클래스 이름을 별도의 파일에 작성하고 읽어들이는 구조로 만듭니다.
=>오라클의 경우 드라이버 클래스 이름: oracle.jdbc.driver.OracleDriver
=>드라이브 클래스 이름이 틀리거나 jar파일을 build path에 추가하지 않았다면 예외가 발생합니다.
public class OracleMain {
public static void main(String[] args) {
try {
//이 코드는 애플리케이션 전체에서 1번만 수행하면 됩니다.
Class.forName("oracle.jdbc.driver.OracleDriver");
System.out.println("드라이브 클래스 로드 성공");
} catch (Exception e) {
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
8. 데이터베이스 연결 및 해제
=>데이터베이스에 연결할 때 는 3가지 정보가 필요
데이터베이스 url: 데이터베이스 종류마다 설정 방법이 다름
계정
비번
=>계정과 비번은 없어도 되는 경우가 있습니다.
=>오라클의 url: -jdbc:oracle:thin:@IP또는 domain :port:sid
sid가 아니고 serviceName인 경우는 : 대신에 /serviceNmae
=>데이터베이스 접속
Connectioin ? = DriverManager.getConnection(url, id, pw);
=>데이터베이스 접속 해제
?.close();
=>url이 잘못 된 경우는 기본적인 접속시간동안 접속을 해보고 네트워크 문제라고 예외를 발생시킵니다.
=>id나 pw가 잘못된 경우는 login denied라는 예외를 발생시킵니다.
public static void main(String[] args) {
try {
//이 코드는 애플리케이션 전체에서 1번만 수행하면 됩니다.
Class.forName("oracle.jdbc.driver.OracleDriver");
System.out.println("드라이브 클래스 로드 성공");
//데이터베이스 접속
Connection con = DriverManager.getConnection("jdbc:oracle:thin:@ip주소:1521:xe","user29","user29");
//ip주소 잘못되면 멍때리고 있다.후에 나온다.
//포트번호가 틀리면 빨리 떤다.
//login denined
System.out.println("접속 성공");
//접속 해제
con.close();
} catch (Exception e) {
System.out.println(e.getMessage());
e.printStackTrace();
}
}
9.데이터베이스 드라이버이름이나 접속 정보는 별도로 작성한 후 읽어 들이는 구조로 만드는 것을 권장
개발환경과 운영환경이 다를 가능성 때문입니다.
프로그래밍 언어별 실행방법
1. 줄 단위로 읽어가면서 실행 - 인터프리터 방식
(대표적인 언어가 python)
python은 코드를 작성할 때 한줄 씩 실행한다.idle에서는 줄단위로 해서 불편해서 파일로 실행한다.
2.소스 전체를 번역한 후 실행
1).줄단위로 실행
2).전체로 한꺼번에 실행
source code -> compile(번역) -> java에서는 byte code(중간코드)만든다. -> build -> 실행 가능한 코드가 만들어진다. -> 로드 (메모리에 적재) -> 실행 (Run)
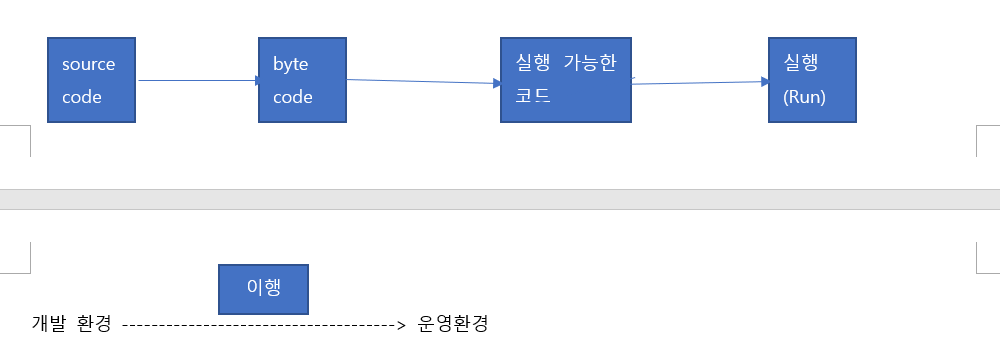
개발 환경 -------------------------------------> 운영환경
localhost:1521 : xe 211....:1521 : xe
getConnection("localhost:1521:xe")=>이것을 운영에 올릴 때
=> getConnection("211..:1521:xe")으로 소스 코드 바꿔야 한다.
소스 코드 바꾸면 처음 부터 해야 한다.
예기치 않는 문제가 발생
이런 경우를 줄이려면 이쪽에 작업을 안할려고 하는 방법
setting.xxx=>파일 을 만들어서 db : localhost: 1521:xe
getConncetion(파일의 내용을 읽는 코드를 사용)
데이터를 바꿀 경우 파일의 내용을 바꾸면 된다. 자바 코드를 바꾸지 않았다.
BUILD를 다시 할 필요없다. 배포만 다시 하면 된다.
SETTING.XXX-> properties
xml -> json
자원이 넉넉하면 클릭해서 손을 댈 수 있어서 별도에 디비에 여는 경우가 있다.
별도의 디비에 작성