아래 내용은 Udemy에서 Pytorch: Deep Learning and Artificial Intelligence를 보고 정리한 내용이다.
GRU and LSTM
Modern RNN Units
LSTM
GRU is like 간단한 버전의 LSTM 과 비슷하다.(파라미터가 적고 thus more efficient )
simple RNN이 is not enough 는 vanishing gradient 때문이다.
vanishing gradient해결하는데 ReLU 사용 ????????
하지만 더 효과적인 GRU, LSTM를 발견하였다.
Simple RNN은 수식이 하나이다.
GRU
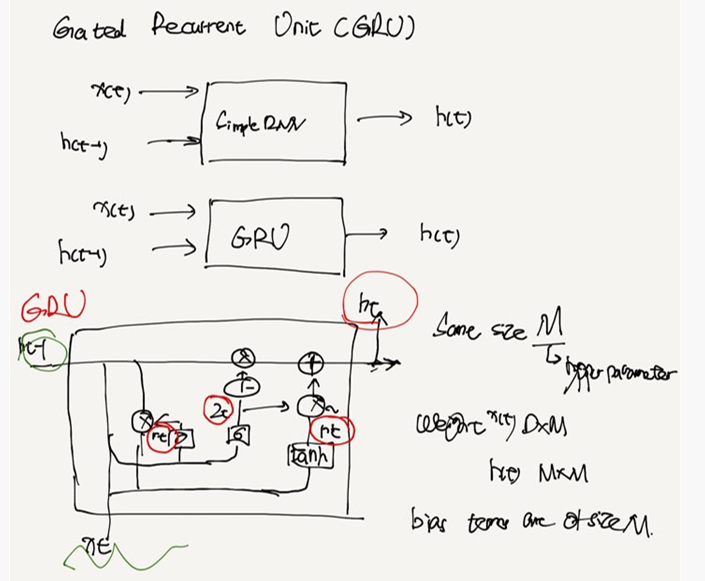
recurrent Unit
SimpleRNNs have no choice bue to eventually forget, due to the vanishing gradient
binary classifier (logistic regression neurons) as our gates
SimpleRNN 은 long-term dependencies에 학습 할 떄 문제가 있다.
the hidden state becomes the weighted sum of the previos hidden state and new value(allowing you to remeber the old state)
these are controlled by "gates" which are like binary classifiers /logistic regression / neurons
GRU less parameter > more performent
LSTM(long-short term memory)
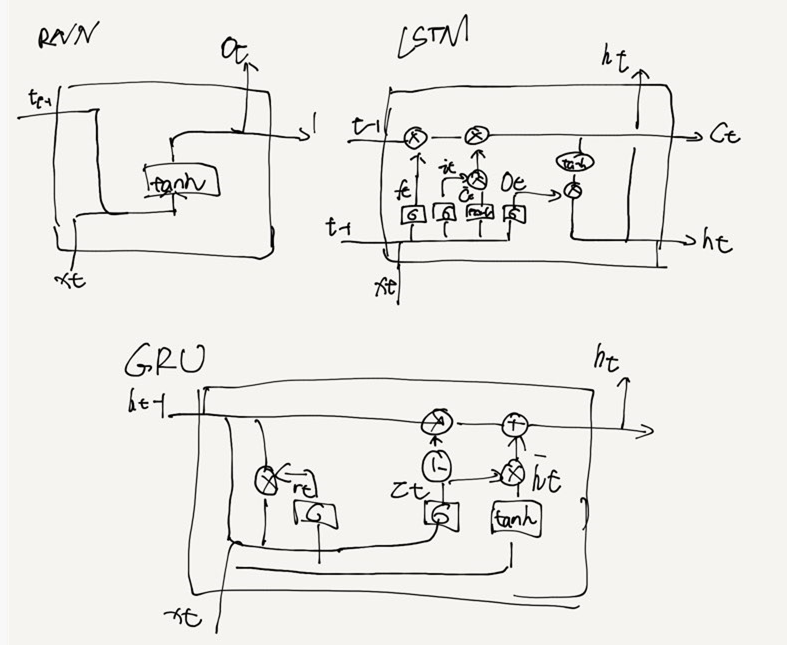

Simple RNN GRU LSTM code
nn.RNN(
input_size = self.D,
hidden_size = self.M,
num_layers = self.L,
nonlinearity = 'relu',
batch_first = True
)
GRU
nn.GRU(
input_size = self.D,
hidden_size = self.M,
num_layers = self.L,
batch_first = True
)
LSTM
nn.LSTM(
input_size = self.D,
hidden_size = self.M,
num_layers = self.L,
batch_first = True
)
A more challenging Sequence
pytorch nonlinear sequence Linear code
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as pltseries = np.sin((0.1 * np.arange(400)) ** 2)data 만들기
T = 10
D = 1
X = []
Y = []
for t in range(len(series) - T) :
x = series[t:t+T]
X.append(x)
y = series[t+T]
Y.append(y)
X = np.array(X).reshape(-1, T)
Y = np.array(Y).reshape(-1, 1)
N = len(X)
print(X.shape, " " , Y.shape)model = nn.Linear(T, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.1)train test set split
X_train = torch.from_numpy(X[:-N//2].astype(np.float32))
y_train = torch.from_numpy(Y[:-N//2].astype(np.float32))
X_test = torch.from_numpy(X[-N//2:].astype(np.float32))
y_test = torch.from_numpy(Y[-N//2:].astype(np.float32))모델 학습
LOSS 확인 하기
ONE-STEP forecast
validation_target = Y[-N//2:]
with torch.no_grad():
validation_predictions = model(X_test).numpy()Linear model has terrible result
pytorch nonlinear sequence SimpleRNN code
T = 10
D = 1
X = []
Y = []
for t in range(len(series) - T) :
x = series[t:t+T]
X.append(x)
y = series[t+T]
Y.append(y)
X = np.array(X).reshape(-1, T , 1) #MAKE IT N x T
Y = np.array(Y).reshape(-1, 1)
N = len(X)
print(X.shape, " " , Y.shape)class RNN(nn.Module):
def __init__(self, n_inputs, n_hidden, n_rnn_layers, n_outputs):
super(RNN, self).__init__()
self.D = n_inputs
self.M = n_hidden
self.K = n_rnn_layers
self.L = n_outputs
self.rnn = nn.RNN(
input_size = self.D,
hidden_size = self.M,
num_layers = self.L,
nonlinearity = 'relu',
batch_first = True
)
self.fc = nn.Linear(self.M, self.K)
def forward(self, X):
h0 = torch.zeros(self.L, X.size(0), self.M).to(device)
out, _ = self.rnn(X, h0)
out = self.fc(out[:,-1,:])
return out
pytorch nonlinear sequence LSTM code
class RNN(nn.Module):
def __init__(self, n_inputs, n_hidden, n_rnn_layers, n_outputs):
super(RNN, self).__init__()
self.D = n_inputs
self.M = n_hidden
self.K = n_rnn_layers
self.L = n_outputs
self.rnn = nn.LSTM(
input_size = self.D,
hidden_size = self.M,
num_layers = self.L,
batch_first = True
)
self.fc = nn.Linear(self.M, self.K)
def forward(self, X):
h0 = torch.zeros(self.L, X.size(0), self.M).to(device)
c0 = torch.zeros(self.L, X.size(0), self.M).to(device)
out, _ = self.rnn(X, (h0,c0))
out = self.fc(out[:,-1,:])
return out
RNNs for Image Classification

MNIST , Fashion MNIST
H x W (2-d )
Code preparation
step 1: load in the data
step 2: model
step 3: fit / plot the loss /etc.
regression is harder than classification
classification 은 라벨만 하면 된다.
lstm
'교육동영상 > 02. pytorch: Deep Learning' 카테고리의 다른 글
| 08. Recommender System (0) | 2020.12.21 |
|---|---|
| 07. NLP (0) | 2020.12.16 |
| 06. Recurrent Neural Networks, Time Series, and Sequence Data (0) | 2020.11.20 |
| 05. Convolutional Nerual Networks (0) | 2020.11.19 |
| 04. Feedforward Artificial Neural Networks (1) | 2020.11.18 |