아래 내용은 Udemy에서 Pytorch: Deep Learning and Artificial Intelligence를 보고 정리한 내용이다.
Recommender Systems with Deep Learning Theory
applicable concepts in ML
아마존 - Amazon
netflex
News -> exciting 한 뉴스를 본다.
Ratings Recommenders
movies
How to recommend?
Given a dataset of triples: user, item, rating
fit a model to the data: f(u, m ) ->r
what should it do?
#1. if the user u and movie m appeared in the dataset, then the predicted rating should be close to the true rating
#2. the function should predict what user u would rate movie m, even if it didn't appear in the training set
Neural networks(function approximators) do this!
since our model can predict ratings for unseen movies, this is easy
given a user, get predicted for every unseen movie=>보지 않았든것
Sort by predicted rating(descending)
recommend movies with the highest predicted rating
How to build the model?
users and movies categorical
neural networks do matrix multiplications
we can't multiply a category by a number(e.g. "Start wars" x5)
NLP
embeddings
mapping
A neural network for recommenders
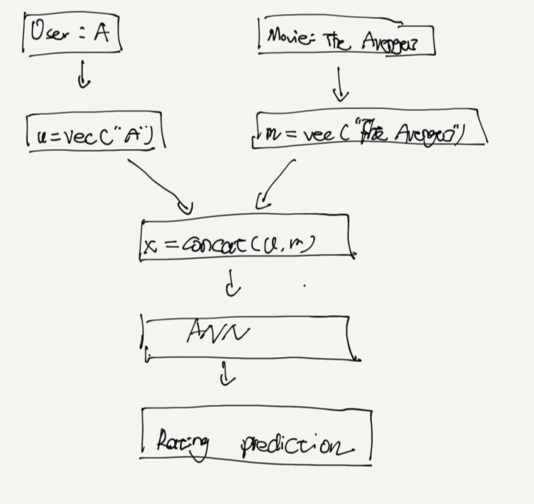
Interesting point
NLP
algorithms word2vec and GloVe
They both do things like " king-man = queen -women"
ANN all data is the same
The inputs are clearly not an N x D matrix of features
All data is not the same
we still have N samples
1st column(users): N- length array of categories()
2nd column(movies): N- length array of categories(can bu duped)
Embedding
NLP: word indexes(N x T) -> word vectors(N x T x D )
recommenders: users / movies(N) -> user/movie vectors(N x D)
How is the data stored?
They are already integers !
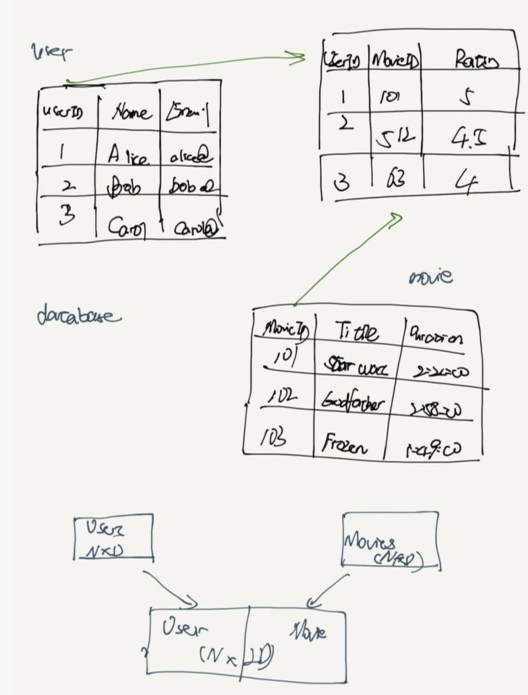
Embeddings & Concatenation
After embedding, users and movies have shape N x D
combine concatenate N x 2D
Now " all data is the same" once again
forward :
something special about this model: it has 2 inputs, not just one!
Loading in data
data is just a csv (pandas)
training 을 하기 위해서 DataLoader로 한다.
pytorch Recommender systems with deep learning code
모델 만들기
class Model(nn.Module):
def __init__(self, n_users, n_items, embed_dim, n_hidden = 1024):
super(Model, self).__init__()
self.N = n_users
self.M = n_items
self.D = embed_dim
self.u_emb = nn.Embedding(self.N, self.D)
self.m_emb = nn.Embedding(self.M , self.D)
self.fc1 = nn.Linear(2 * self.D , n_hidden)
self.fc2 = nn.Linear(n_hidden , 1)
def forward(self, u, m ):
u = self.u_emb(u)
m = self.m_emb(m)
out = torch.cat((u, m ), 1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return outmodel = Model(N, M ,D )
model.to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())make dataset
#make dataset
Ntrain = int(0.8 * len(ratings))
train_dataset = torch.utils.data.TensorDataset(
user_ids_t[:Ntrain],
movie_ids_t[:Ntrain],
ratings_t[:Ntrain]
)
test_dataset = torch.utils.data.TensorDataset(
user_ids_t[Ntrain:],
movie_ids_t[Ntrain:],
ratings_t[Ntrain:]
)
batch_size = 512
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = False)
pytorch %prun
얼마나 function에 사용했는지 알려진다.
5분 정도 걸리기 때문에 이것을 사용한다.
%prun train_losses, test_losses = batch_gd(model, criterion, optimizer, train_loader, test_loader, 25)
same prediction
pytorch weight 변경해서 하기
class Model(nn.Module):
def __init__(self, n_users, n_items, embed_dim, n_hidden = 1024):
super(Model, self).__init__()
self.N = n_users
self.M = n_items
self.D = embed_dim
self.u_emb = nn.Embedding(self.N, self.D)
self.m_emb = nn.Embedding(self.M , self.D)
self.fc1 = nn.Linear(2 * self.D , n_hidden)
self.fc2 = nn.Linear(n_hidden , 1)
# set the wights since N(0,1) leads to poor results
self.u_emb.weight.data = nn.Parameter(torch.Tensor(np.random.randn(self.N, self.D) * 0.01))
self.m_emb.weight.data = nn.Parameter(torch.Tensor(np.random.randn(self.M, self.D) * 0.01))
def forward(self, u, m ):
u = self.u_emb(u)
m = self.m_emb(m)
out = torch.cat((u, m ), 1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model(N, M ,D )
model.to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.08 , momentum = 0.9)
pytorch top 10 recommended
watched_movie_ids = df[df.new_user_id ==1].new_movie_id.values
watched_movie_idspotential_movie_ids = df[-df.new_movie_id.isin(watched_movie_ids)].new_movie_id.unique()
print(potential_movie_ids.shape)
print(len(set(potential_movie_ids)))user_id_to_recommend = np.ones_like(potential_movie_ids)t_user_ids = torch.from_numpy(user_id_to_recommend).long().to(device)
t_movie_ids = torch.from_numpy(potential_movie_ids).long().to(device)
with torch.no_grad():
predictions = model(t_user_ids, t_movie_ids)predictions_np = predictions.cpu().numpy().flatten()
sort_idx = np.argsort(-predictions_np)top_10_movie_ids = potential_movie_ids[sort_idx[:10]]
top_10_scores = predictions_np[sort_idx[:10]]
for movie, score in zip(top_10_movie_ids, top_10_scores):
print("movie:", movie," score:", score)'교육동영상 > 02. pytorch: Deep Learning' 카테고리의 다른 글
| 10. GANs (0) | 2020.12.28 |
|---|---|
| 09. Transfer Learning (0) | 2020.12.23 |
| 07. NLP (0) | 2020.12.16 |
| 06-2. Recurrent Neural Networks, Time Series, and Sequence Data (0) | 2020.12.14 |
| 06. Recurrent Neural Networks, Time Series, and Sequence Data (0) | 2020.11.20 |