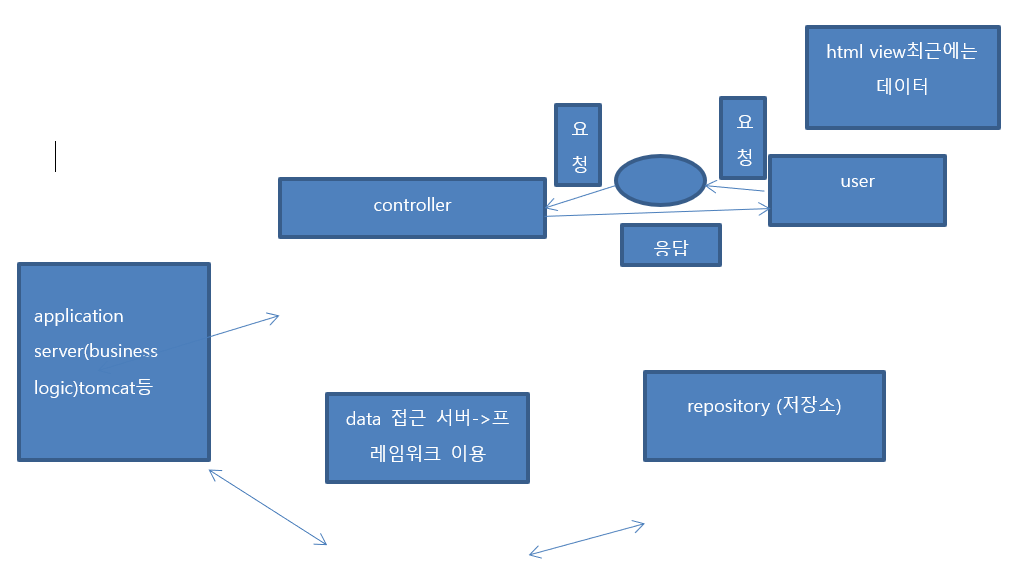
데어터저장소 repository
db가 아니다.
저장소가 repository
repository에 접근하는 데이타 접근서버 별도로 통신
데이타 접근서버 framework 이용(hibernate, mybatis)
application서버
현대자동차는 hana db로 한다.읽기 위해서 특화된 것이다.
속도와 트래픽 문제
데이터를 던져줘서 마음데로 해
데이터 분석이 많이 필요하다.
web platform
socket통신은 프로그램을 깔아야 한다.
web으로 구현하면 browser로 접속 가능하다.
substr 은 글자 단위로 하고
substrb byte단위로 한다.
한글 1글자 -> 2byte 혹은 3byte

사용하지 않을 경우 끄기
listener 외부에서 접근 못하게
localhost는 끄도 안끄도 상관없다.
192.이런식으로 할떄는 listener크고 방화벽 끄야 한다.
나가는 것 제외 proxy
밖에서 들어오는 것 제외 firewall
git 은 가능하는뎅 pip는 안된다.
tibero에서도 listener사용한다.
mysql에서도 service있고 listener열어야 한다.
오라클 구동확인
서비스에서 oracle service? 가 실행 중인지 확인:오라클 서버 구동 여부
listener가 실행 중인 지 확인:오라클을 외부에서 접속할 수 있도록 해주는 서비스
** 데이터베이스 접속 정보
1. 데이터베이스 종류
2. 데이터베이스 서버 url
3. 계정
4. 비밀번호
=>경우에 따라 3,4번은 없어도 되는 경우가 있습니다.
1521,8890
sid는 이름이고 xe
enterprise -> orcl
service name
substr 보고 판단하기
프로그램 언어마다 다 다르다.
substr:문자열에서 원하는 위치부터 원하는 글자 수만 큼 추출해주는 함수
SELECT SUBSTR('안녕하세요',2,4)
FROM DUAL;--녕하세요
--한글을 SUBSTRB잘 사용안한다.
SELECT SUBSTRB('안녕하세요',2,4)
FROM DUAL;--
--4번째 바이트 부터 3바이트 가져오기
SELECT SUBSTRB('안녕하세요',4,3)
FROM DUAL;--녕
영어는 결과가 같다.
--instr->index문자열에서 특정 문자열을 찾아주는 함수
instr( 문자열,검색할 문자열,시작위치,몇번째)
시작위치는 생략하면 1
몇번째는 생략하면 1
null일 경우 한번 해보기
--문자열 위치 조회
SELECT instr('Hello Oracle','Hello')
FROM DUAL;--1
SELECT instr('Hello Oracle','Hi')
FROM DUAL;--0
--프로그래밍에서는 없으면 -1이다. -1이 최대이다. 끝까지 가봤는데 없더라
--oralce은 0이다. 0은 의미 없는 값이다. 없으면 0이다.
--python문자열 함수 확인하여야 함
--slice
--python으로 bubble sort이랑 queue sort이다.
trim:
ltrim과 rtrim
trim은 좌우 공백을 제거해서 리턴해주는 함수
문자열 검색 알고리즘에서는 좌우 공백을 제거하고 조회합니다.
계정은 대소문자 구분하지 않고 공백도 제거한다.
--좌우공백
SELECT trim(' HI ')
FROM dual;--HI
-- 프로그램이나 데이터베이스에서 문자열을 비교할 때는 좌우공백을 제거하고 비교하는 경우가 많습니다
-- 영문인 경우는 대소문자 구분 여부를 설정해야 합니다.
-- 비밀번호를 제외하고는 대소문자 구분을 하지 않습니다.
-- 영문 텍스트 마이닝세어 제일 먼저 하는 일 중의 하나가 소문자로 전부 변화하는 것입니다.
--CONCAT
두개의 문자열을 합쳐서 하나의 문자열로 만들어주는 함수
함수 보다는 || 연산자를 더 많이 이용한다.
함수는 호출한다.

함수는 HEAP에 있는지 없는지 확인하고 메모리 만들고 리턴한다.
연산자를 더 많이 사용한다.
class는 함수 보다 더 늦다.
아래 두개 결과는 같다.
--concat
SELECT CONCAT(ename,job)
FROM EMP e;
SELECT ename || job
FROM EMP e;
convert
문자열의 charset(인코딩)을 변환해주는 함수
convert(데이터,변경할 인코딩,원래 인코딩)
많이 사용되는 인코딩 방식은 US7ACII, UTF8,WE8ISO8859-1
한글이 되는 것은 UTF8밖에없다. american standard
ASCII:영문 및 숫자 특수문자를 1byte로 표현하는 방식
utf8:전 세계 모든 문자를 표현하기 위한 코드 –한글자가 3bytes
WE8ISO8859-1:서유럽 문자로 한글이 표현되지 않은 iso latin -1이라고도 합니다.
convert 한글은 utf8로 밖에 표현이 안되기 때문에 거의 사용되지 않고 유럽 쪽에서는 많이 사용
**날짜 관련 함수
sysdate:현재 날짜 및 시간을 리턴
데이터베이스에스는 대부분의 관계형 데이터베이스는 하루를 수자 1로 간주해서 덧셈 및 뺄셈이 가능하다.
next_day:특정 날짜에서 입력한 요일이 언제인지 리턴해주는 함수
add_month :특정 날짜에서 월을 더해서 리턴해주는 함수
round,trunc를 이용해서 반올림이나 버림도 가능하다.
날짜 영역으로
주단위 월단위로 계산 하는 부분
구글 analytics
--날짜 사이에 연산자
--몇칠 근무했는지 확인
SELECT ENAME,TRUNC(SYSDATE-HIREDATE)
FROM EMP e;
SELECT SYSDATE-TO_DATE('1986/05/05','yyyy/MM/dd')
FROM DUAL;
형 변환함수
숫자 <-> 문자
문자 <-> 날짜
=>문자로 변환할 때는 to_char
=>날자로 변환할 때는 to_date
=>숫자로 변환할 때는 to_number
=>날짜 사이의 연산은 숫자로 변환해서 연산을 합니다.
날짜 – 날짜를 하면 숫자로 결과가 리턴
=>문자로 변환하는 경우는 대부분 출력을 하기 위해서
=>숫자나 날짜 변환하는 경우는 연산을 하기 위해서 입니다.
=>문자는 더하기 하면 뒤에 붙어진다.
=>숫자나 날짜 서식
1. 숫자서식
0:무조건 표시하는것으로 없으면 0
9:있으면 표시하고 없으면 생략
L:통화기호
.:소수점
,:천 단위 구분 기호
2. 날짜 서식
yyyy-연도 4자리
yy – 연도 2자리
mm-월 2자리
day –요일
dd-일
hh -12시간제
hh24 24시간제
mi 분
ss 초
am또는 pm:오전 오후
엑셀에서 한글 있는지 확인하고 , 이것 있는지 확인 천 단위 구분기호 있으면 문자로 인식한다.
1,234->엑셀에서는 숫자인데 , R이나 PYTHON 에서는 문자로 한다.
날짜 숫자 저장할때 자리수 맞추어 주는게 좋다.
7시 => 07
17시 => 17
mac 등 사용할때 9시간 차이난다.
날짜 오류 날 경우 날짜 바꿨다고 하면 된다.
날짜 다를 경우 운영체제
**null대체 함수
nvl(데이터,데이터가 null일때 사용할 값)
nvl2(데이터, 데이터가 null이 아닐 때 사용할 값,null일 때 사용할 값)
--emp테이블에서 enmae과comm의 값에 100을 더한 값을 조회
SELECT ENAME, comm+100
FROM EMP e;
--데이터베이스에서는 null과 연산을 하면 null
-- 프로그래밍 언어에서는 예외가 발생
SELECT ENAME, NVL(comm,0)+100
FROM EMP e;
SELECT ENAME, NVL2(comm,comm,0)+100
FROM EMP e;
null일 경우 결측치 라고 한다.
**그룹화
1. 그룹함수
=>다중 행 함수라고도 하는데 1개 이상의 행을 가지고 연산을 한 후 하나의 결과를 리턴하는 함수
=>sum,avg,max,min,count,stddev-표준편차,variance-분산
=>함수의 매개변수로 컬럼이름이나 연산식을 대입하는데 null인 데이터는 제외하고 연산을 합니다.
=>데이터의 개수를 셀때 count를 사용하는데 컬럼이름을 대입하면 null인 데디터는 제외하게 되는데 전체 데이터의 개수를 알고자 할 때는 컬럼 이름 대신에 * 을 대입합니다.
모든 컬럼이 null이 아니라면 개수를 세는데 포함이 됩니다
=>avg 를 이용해서 평균을 구할때 null인 데이터를 치환을 해서 계산을 하는 경우가 많습니다.
comm컬럼의 경우 14개의 데이터 중에서 4개의 데이터만 입력이 되어있습니다.
avg를 바로 구하면 4개 데이터의 평균이 리턴됩니다.
=>그룹 함수는 group by 절의 내용과만 같이 출력이 가능합니다.
그룹화하지 않은 컬럼과는 같이 출력할 수 없습니다.
=>평균과 최대 ,최소 그리고 사분위 수는 같이 출력하는 것이 좋습니다.
이 값들을 보고 데이터의 대략적인 분포를 알고 이상치 여부를 판단하거나 대표값을 선정합니다.
평균과 확 차이가 나면 noisy나 outline이라고 한다.
boxplot
기술 통계학 보고 판단 데이터 분포 확인
대표값 평균값
70,70,68,72,70 평균 70 일 경우 70이 대표값
85,85,85,85,10 평균 70이지만 대표값은 85이다.
--emp테이블에서 sal의 평균
SELECT avg(SAL) AS 급여평균
FROM EMP e;
--emp에서 comm의 평균: comm에는 null데이터가 포함되어 있습니다.
SELECT avg(comm) AS 상여금평균
FROM EMP e;
SELECT avg(nvl(comm,0)) AS 상여금평균
FROM EMP e;
--상여금을 받는 사원의 수
SELECT count(COMM)
FROM EMP e;
--전체 사원의 수
SELECT count(*)
FROM EMP e;
--sal이 가장 많은 사원의 ename과 sal값을 출력
--ename은 여러개의 값이고 max(sal)은 하나의 값이라서 같이 출력할 수 없습니다.
--이런 경우는 서브쿼리나 조인을 이용해서 해결해야 합니다.
SELECT ename,max(sal)
FROM emp
GROUP BY ENAME
ORDER BY max(sal) DESC;
2. group by
=>그룹화에 사용하는 절
=>컬럼이나 연산식을 이용해서 그룹화
=>group by 절에 기재한 내용은 그룹 함수와 같이 출력 가능
--emp테이블에서 job별로 평균 sal의 랎을 조회
SELECT JOB, AVG(SAL)
FROM EMP e
GROUP BY JOB;
--emp테이ㅂㄹ에서 입사년도 별 인원수를 조회
--입사년도는 hiredate컬럼
SELECT TO_CHAR(HIREDATE,'yyyy') ,count(*)
FROM EMP e
GROUP BY TO_CHAR(HIREDATE,'yyyy')
SELECT SUBSTR(HIREDATE,1,2) ,count(*)
FROM EMP e
GROUP BY SUBSTR(HIREDATE,1,2);
SELECT SUBSTR(HIREDATE,1,2) AS 입사년도,count(*) AS 인원수
FROM EMP e
GROUP BY SUBSTR(HIREDATE,1,2)
ORDER BY 인원수 DESC;
SELECT TO_CHAR(HIREDATE, 'yyyy/mm/dd day')
FROM EMP e;
--요일별로 인원수를 조회
SELECT TO_CHAR(HIREDATE, 'day') AS 입사요일,count(*) AS 인원수
FROM EMP e
GROUP BY TO_CHAR(HIREDATE, 'day')
ORDER BY 인원수 DESC;
=>group by 절에 여러개의 컬럼이나 연산식을 작성할 수 있는데 첫번째로 그룹화하고 그안에서 다시 그룹화
**having
=>그룹화 한 이후에 조건을 적용할 때 사용
=>where절은 group by 보다 먼저 실행되기 때문에 그룹 함수를 사용할 수 없습니ㅏㄷ.
=>그룹 함수를 이용한 조건은 having에 작서해야 합니다.
select -5
from -1
where -2
group by -3
having -4
order by – 6
--5명 이상입사한 해를 조회
SELECT SUBSTR(HIREDATE,1,2) ,count(*)
FROM EMP e
GROUP BY SUBSTR(HIREDATE,1,2)
HAVING count(*) >= 5;
--그룹함수를 사용하지 않는 조건을 having에 사용하는 것은 비효율적입니다.
sql은 절 단위로 수행해서 하나의 결과를 만들어냅니다.
selece일 때만 효율을 많이 사용합니다.
emp테이블에서 deptno가 10인 데이터의 sal의 평균 조회
4.select avg(sal)
1.from emp
2.where deptno = ‘10’
3.group by deptno ;->추천
=> 결과 1.에서 5개
2.5개 가지고 group by 한다.
filter은 where에서 하는 것이 좋다.
4.select avg(sal)
1.from emp
2.group by deptno
3.having deptno = ‘10’;->비효율적이다 .그룹함수가 없다.
=>결과 1.에서 15개
2.에서 3개씩 group by
3.에서 5개
emp
deptno 10->5
20->5
30->5

데이터 처리 부분
뭐 하기전에 필터링 먼저 하자
자료형 ,
이상치 제거,
null치환(null제거),
기술통계,
시각화 ,
미리 필터링,
원핫인코딩(a문자를 숫자로 바꿔야 한다.),
필터링, 표준화(데이터를 맞춰야 한다. 정규화)
필터링을 먼저 하는게 좋다.
solaris ->sun ->oracle인수
예약 application->코레일
** join
=>2개의 테이블을 조합하는 것
=>구조가 다른 테이블 들끼리 합쳐서 하나의 테이블을 테이블을 만드는 것은 join이라고 동일한 구조를 가진 테이블끼리 세로로 합치는 것을 merge라고 합니다
1. cartesian porduct
=>cross join 이라고도 하는데 2개의 테이블의 모든 테이블들을 조합하는 것
=>from 절에 테이블이름을 2개를 기재하면 기본적으로 cartesian porduct
=>행의 개수는 양쪽 테이블의 행의 개수의 곱이되고 열의 개수는 양쪽 테이블의 열의 개수의 합이 됩니다.
=>관계형 테이터베이스에서 테이블을 너무 많이 분할했을 때 발생하는 문제점입니다.
emp테이블에는 8개의 열과 14개의 행이 존재
dept테이블에는 3개의 열과 4개의 행이 존재
emp테이블과 dept테이블을 cartesian product함ㄴ 11개의 열과 56개의 행이 생성
SELECT *
FROM EMP,DEPT d;

2.equi joinn
=>2개 테이블의 공통된 의미를 갖는 열의 값이 같을 때만 결합하도록 하는 것
=>실제 동작은 공통된 의미가 아니라 자료형만 같으면 수행할 수 있습니다.
=>where 절에 양쪽 테이블의 공통된 의미를 갖는 데이터가 같을 때만 결합하도록 기재
=>양쪽 테이블에 있는 열의 이름이 같으면 앞에 테이블이름.을 추가해서 구분을 해주어야 합니다.
SELECT *
FROM EMP e,DEPT d
WHERE e.DEPTNO = d.DEPTNO;
=>테이블 이름을 생략하면 열의 이름이 애매하다고 에러 발생
=>새로운 조건을 추가해서 필터링을 할 때는 위치는 상관없지만 일반적으로 join조건 뒤에 and를 추가하고 작성
-emp테이블에서 sal이 3000이상인 사원의 ename과 deptno그리고 dept테이블의 loc를 조회
=>ename과 deptno는 emp 테이블에 존재
=>loc는 dept테이블에 존재
=>emp테이블과 dept테이블에 공통된 의미를 갖는 열은 deptno
SELECT e.ENAME, e.DEPTNO,d.LOC
FROM EMP e,DEPT d
WHERE e.DEPTNO = d.DEPTNO
AND e.SAL >= 3000;
3. 테이블에 별명 부여
=>테이블 이름이 너무 길거나 알아보기 어려운 경우 또는 self join의 경우에는 테이블 이름에 별명을 부여할 수 있습니다.
=>테이블 이름 뒤에 공백을 추가하고 별명을 입려하면 됩니다.
=>select에서 컬럼의 이름에 별명을 붙인 경우에는 oder by 절에서 별명을 사용해도 되고 원래 이름을 사용해도 되지만 from 절에 테이블 이름에 별명을 붙인 경우에는 이후에는 반드시 테이블 이름 대신 별명을 사용해야 합니다.
R은 install하면 kernel restart한다.
4. non equi join
=>join을 할때 = 대신에 다른 연산자로 join 하는 것
salgrade테이블은 grade와 losal그리고 hisal열로 구성
grade는 급여 등급이고 losal은 그 등급에서 최저 급여 그리고 hisal은 최고 급여입니다.
emp테이블에서 가져온 sal과 losal이나 hisal과 비교하게 되면 = 로는 안될 수 있습니다.
--emp테이블의 ename과 sal 그리고 salgrade테이블에서 sal에 해당하는 grade를 조회하고 자 합니다.
SELECT e.ENAME, e.SAL, s.GRADE
FROM EMP e, SALGRADE s
WHERE (e.SAL >= s.LOSAL AND e.SAL <= s.HISAL);
--학점이나 등급 계산 할때
SELECT e.ENAME, e.SAL, s.GRADE
FROM EMP e, SALGRADE s
WHERE e.SAL BETWEEN s.LOSAL AND s.HISAL;
5. self join
=>자신의 테이블과 join
=>하나의 테이블에 동일한 의미를 갖는 열이 2개 이상 있는 경우에 사용
=>from절에 동일한 테이블의 이름을 2번 기재하므로 반드시 별명을 부여해야 합니다.
emp테이블에서 empno는 사원번호 이고 mgr는 관리자 사원번호
이런 경우 사원이름과 관리자의 이름을 같이 조회할려고 하면 self join을 사용해야 합니다.
친구 추천
추천 시스템 -> 감성을 이용해서 추천 ,내가 좋아요 눌리면 다른 사람 것 추천
è 구매목록을 확인하여 확률 높은 것을 추천
è
è SELECT e1.ENAME , e2.ENAME 관리자
è FROM EMP e1 , EMP e2
è WHERE e1.mgr = e2.EMPNO;
=>emp테이블에서 ename 이 scott인 사원의 관리자 이름을 조회
결과는 jones
SELECT E2.ENAME
FROM EMP e , EMP e2
WHERE e.MGR = e2.EMPNO
AND UPPER(e.ENAME)='SCOTT';
=>EMP테이블에서 ENAME이 SCOTT인 사원의 관리자의 관리자 사원번호를 조회
결과는 7839
SELECT E2.MGR
FROM EMP e , EMP e2
WHERE e.MGR = e2.EMPNO
AND UPPER(e.ENAME)='SCOTT';
6. outer join
=>inner join 은 equi join
=>outer joind은 어느 한쪽에만 존재하는 데이터도 join에 참여시키는 것
=>emp테이블에는 deptno가 10,20,30 이 있고 dept테이블에는 deptno가 10,20,30,40이 존재
이 경우 equi join을 하게 되면 양쪽 테이블에 모두 존재하는 10,20,30 만 조회
이때 DEPT테이블에만 존재하는 40도 JOIN에 참여시키고자 할 떄 수행하는 JOIN이 OUTER JOIN입니다.
=>OUTER JOIN을 할 떄는 참여시키고자 하는 테이블의 조인조건 기술할 떄 반대편에 (+)에 추가
EMP.DEPTNO(+) = DEPT.DEPTNO
=>DEPTNO테이블에 있는 모든 데이터가 JOIN에 참가
=>양쪽 모두에 사용하는 것은 안됩니다.
SELECT D.DEPTNO,D.DNAME,E.ENAME
FROM EMP e , DEPT d
WHERE E.DEPTNO(+) = D.DEPTNO;--15개
=>40번도 나온다. 이름이 없는데 나온다.
SELECT D.DEPTNO,D.DNAME,E.ENAME
FROM EMP e , DEPT d
WHERE E.DEPTNO = D.DEPTNO(+);--14개
sqllite는 외래키 이런것 문법적으로 되는데 기능제약이 있다.
embeded 간단하게 나와서 복잡해서 안될 경우가 있다.
7. ansi join
=>미국 표준 협회에서 만든 join문법으로 대다수의 관계형 데이터베이스에서 적용이 되지만 일부 관계형 데이터베이스에서는 안될 수도 있습니다.
1). cartesian porduct(cross join)
from 테이블이름 cross join 테이블이름
SELECT *
FROM EMP e cross join DEPT d ;
2). equi join-join조건을 on절에 기재: join조건과 where 를 구분하기 위해서 사용
from 테이블이름1 inner join 테이블이름2
on 테이블이름1.컬럼이름 = 테이블이름2.컬럼이름
SELECT D.DEPTNO,D.DNAME,E.ENAME
FROM EMP e INNER join DEPT d
ON e.DEPTNO = d.DEPTNO;
이 경우 양쪽 컬럼이름이 같으면 on대신에 using 사용할 수 있습니다
from 테이블이름1 inner join 테이블이름2
using(컬럼이름)
SELECT *
FROM EMP e INNER join DEPT d
USING(DEPTNO);
컬럼이름이 같으면 inner join대신에 natural jon이라고 입력하고 조인 조건 생략 가능
from 테이블이름1 natural join 테이블이름2
SELECT *
FROM EMP e natural join DEPT d ;
3).outer join
from 테이블이름1 [left|right|full] outer join 테이블이름2
on 테이블이름1.컬럼이름 = 테이블이름2.컬럼이름
=>full은 어느 한쪽 테이블에만 존재하는 데이터도 조인에 참여
SELECT D.DEPTNO,D.DNAME,E.ENAME
FROM EMP e , DEPT d
WHERE E.DEPTNO(+) = D.DEPTNO;
SELECT D.DEPTNO,D.DNAME,E.ENAME
FROM EMP e RIGHT OUTER join DEPT d
ON E.DEPTNO = D.DEPTNO;
8. set연산
=>동일한 구조를 가진 2개의 테이블에서 가능
=>구조가 같다는 의미는 열의 개수가 같아야 하고 각 열의 자료형이 같아야 한다.
=>세로 방향으로 작업을 한다.
구별 경찰서와 강력 범죄 발생 건수
구별 경찰서와 위치
1) 합집합 –union(중복제거),union all(중복 제거하지 않는다.)
2) 교집합-intersect 공통적인 부분
3) 차집합-minus
select 구문
set 연산자
select 구문
select deptno
from emp
UNION all
select deptno
from dept;--18
select deptno
from emp
UNION
select deptno
from dept;--4
select deptno
from emp
INTERSECT
select deptno
from dept;--3
select deptno
from emp
MINUS
select deptno
from dept;--0
예측은 데이터 많으면 많을 수록 오른 결과가 나올 수 있을 가능성이 높다.
머신런닝은
join하면 시간이 오래 걸린다.
**sub query
=>sql문장안에 포함된 sql
=>대부분의 경우는 select
1.작성 방법
=>포함된 구문은 반드시 ()로 감싸서 우선순위를 높여서 먼저 실행하도록 해야 합니다.
2.서브쿼리의 실행
=>서브쿼리는 메인쿼리가 실행되기 전에 1번만 실행
3. 종류
1) 단일 행 서브쿼리: 서브쿼리의 결과가 하나의 행인 경우
=>단일 행 연산자를 사용가능(=,!=,>,>=,<,<=)
2) 다중 행 서브쿼리: 서브쿼리의 결과가 2개 이상의 행인 경우
=>단일 행 연산자를 단독으로 사용 불가능
=> in,not in ,all, any 와 같은 다중 행 연산자를 같이 사용해야 합니다.
4. 단일 행 서브쿼리
1) emp 테이블에서 ename이 scott인 사원의 관리자 이름을 조회
=>join으로 해결
select
from emp e1, emp e2
where e1.ename = ‘SCOTT’ and e1.mgr = e2.empno
SUB QUERY로 하면 하는게 좋다 .JOIN일 경우 데이터 사용량이 많다.
SELECT e.ename
FROM EMP e
WHERE e.EMPNO = (SELECT MGR
FROM EMP
WHERE ename ='SCOTT');
=>SELECT절에 출력하는 열의 이름들이 하나의 테이블에서 추출이 가능하다면 SUB QUERY로 해결 가능하다.
괄호가 먼저 해야 해서
2) emp테이블과 dept테이블은 deptno를 같이 소유하고 있습니다.
dept테이블의 loc가 dallas인 사원의 emp테이블의 ename과 sal
SELECT ename,SAL
FROM emp
WHERE DEPTNO = (SELECT DEPTNO
FROM DEPT d
WHERE loc ='DALLAS');
3).detp테이블의 dname이 sales인 데이터의 ename과 job을 조회
부서명이 sales인 사원의 이름과 직무를 조회
ename과 job은 emp에 존재
dept테이블과 emp테이블은 deptno를 공유
SELECT ename,job
FROM EMP
WHERE DEPTNO = (SELECT DEPTNO
FROM DEPT d
WHERE DNAME = 'SALES');
5.다중 행 서브쿼리
emp테이블과 dept테이블은 deptno를 같이 소유하고 있습니다.
dept테이블의 loc가 dallas나 chicago인 사원의 emp테이블의 ename과 sal을 조회
select ename,sal
from emp
where deptno = (select deptno
from dept
where loc ='DALLAS' OR loc ='CHICAGO' );
=>이 문장은 에러
문법적으로는 에러가 아닐 수 있지만 'DALLAS', 'CHICAGO'에 근무하는 사원의 DEPTNO가 20과 30 두개입니다.
두개의 데이터를 =로 비교할 수 없습니다.
이 경우에는 = 대신에 in을 사용해야 합니다.
!= 의 경우에는 not in 을 사용해야 합니다.
select ename,sal
from emp
where deptno in (select deptno
from dept
where loc ='DALLAS' OR loc ='CHICAGO' );
=>2개 이상의 숫자가 결과로 리턴되는 경우에 2개 숫자보다 모두 큰 경우에 해당하는 데이터를 조회 할 때 > (100,200)의 형식은 안됩니다.
크다나 작다는 하나의 값과만 비교 가능
여러 개의 데이터와 크다 작다로 비교하는 경우에는 all이나 any 라는 연산자를 이용할 수 있습니다.
>ALL (100,200): 100과 200보다 모두 큰 경우에는 TRUE리턴
이와 동일한 결과를 가져오는 형태는 >MAX(100,200)
>ANY(100,200):100이나 200데이터 중에서 하나라도 크면 TRUE리턴
이와 동일한 결과를 가져오는 형태는 >MIN(100,200)
=>emp테이블에서 deptno가 10 또는 20인 부서의 평균 sal보다 sal이 더 큰 사원의 이름과 sal을 조회
SELECT ENAME,SAL
FROM EMP e
WHERE sal >(SELECT AVG(SAL)
FROM EMP e
WHERE DEPTNO IN ('10','20')
GROUP BY DEPTNO );
-- single-row subquery returns more than one row
--이 문장은 서브쿼리의 결과가 2개라서 에러가 발생
SELECT ENAME,SAL
FROM EMP e
WHERE sal > ALL (SELECT AVG(SAL)
FROM EMP e
WHERE DEPTNO IN ('10','20')
GROUP BY DEPTNO );
SELECT ENAME,SAL
FROM EMP e
WHERE sal > (SELECT max(AVG(SAL))
FROM EMP e
WHERE DEPTNO IN ('10','20')
GROUP BY DEPTNO );
---------------------
SELECT ENAME,SAL
FROM EMP e
WHERE sal > ANY (SELECT AVG(SAL)
FROM EMP e
WHERE DEPTNO IN ('10','20')
GROUP BY DEPTNO );
SELECT ENAME,SAL
FROM EMP e
WHERE sal > (SELECT min(AVG(SAL))
FROM EMP e
WHERE DEPTNO IN ('10','20')
GROUP BY DEPTNO );