아래 내용은 Udemy에서 Pytorch: Deep Learning and Artificial Intelligence를 보고 정리한 내용이다.
Embeddings
Text is sequence data, but it is not continuous
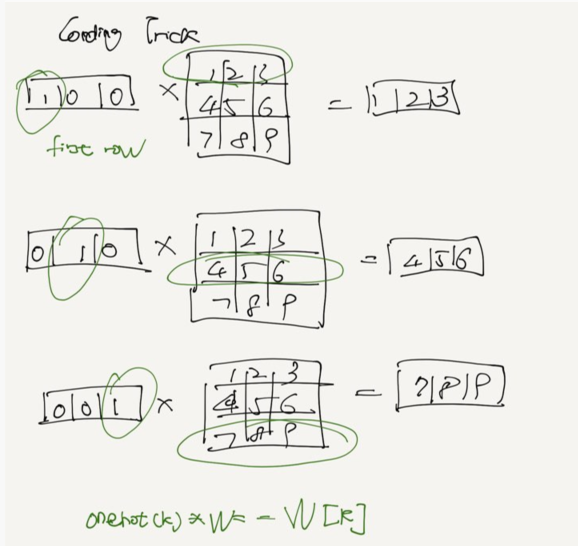
One-Hot Encoding?
vector = > 0을 포함한 것
map each word to an index
a => [1,0] 1
b => [0,1] 2
T words -> one hot encoded vector of size V
T x V matrix
data has no useful geometrical structure.
each word to a D-dimensional vector(not one-hot encoded)
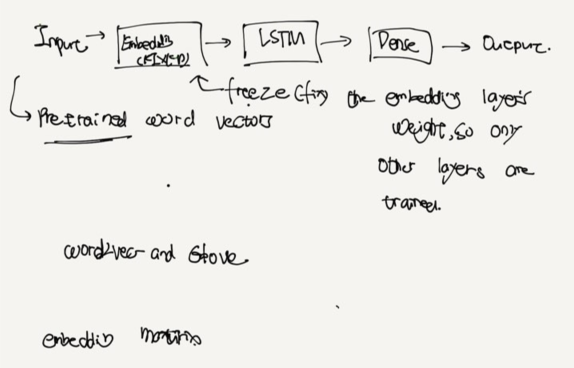
RNN with Embedding
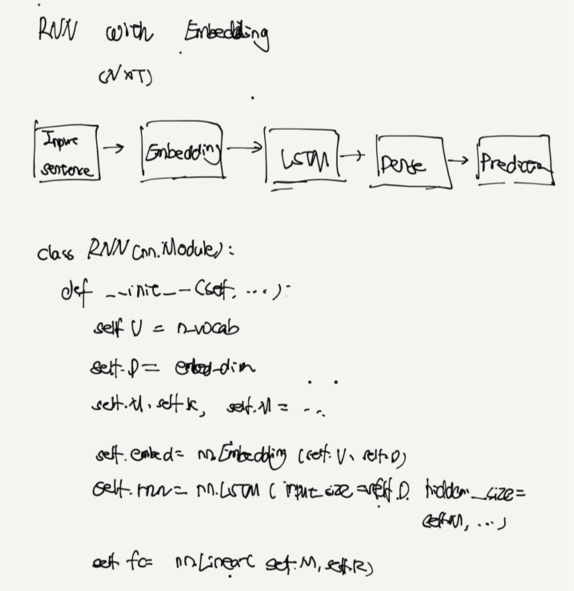
D = embedding dimension -> hypperparameter
V = vecab size (# of unique words)
Embedding matrix is V x D
Each row is a D-size vector for a word
forward Function
out = self.embed(x)
Text Preprocessing
Text Files
each word -> Integer ->vector
Structured Text Files
CSV(comma separated value)
dovument
pandas for CSV?
document
multiple words -> individual words
Multiple words to single words(Tokenization)
string.split() => a lot of cases
can't handle punctuation => .
remove 를 해야 한다.
Tokens to Integers
dataset = long sequence of words
current_idx = 0
word2idx = {}
for word in dataset:
if word not in word2idx :
word2idx[word] = current_idx
current_idx += 1
current_idx = 0 => 2로 한다.
보통 0으로 안한다.
1 = padding
0 = unknown => 우리는 학습을 못 할 떄
Constant-Length Sequence
길이를 같게 하고 하기 위해 padding 을 한다.
Pre-padding vs Post-padding

- Text classification RNN reads the input from left-to-right, the pre-padding 이 더 좋다.
시작 -> 끝
- challenging for RNNs to learn long-term dependencies!
convert to csv
Tokenization
map each token to a unique integer
The task
text classification(many-to-one)
Input: sequence of words, output: a single label (spam or not spam)
Field Objects
import torchtext.data as ttd
TEXT = ttd.Field(
sequentail = True,
batch_first = True,
lower = True,
pad_first = True
)
LABEL = ttd.Field(sequentail = False, use_vocab = False, is_target = True)
TabularDataset Object
split train, test data
dataset.split()
build vocab
TEXT.build_vocab(train_dataset)
vocab = TEXT.vocab
vocab object
stoi(C-style naming) 문자 -> 숫자
itos(reverse mapping) 숫자 -> 문자
stoi and itos
Dictionary = keys -> values
List = keys -> value
pytorch Text Preprocessing
import torch
import torch.nn as nn
import torchtext.data as ttd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetimedata = {
"label" : [0,1,1] ,
"data" :[
"I like eggs and ham.",
"Eggs I like!",
"Ham and eggs or just ham?"
]
}
df = pd.DataFrame(data)
df.head()df.to_csv("data.csv", index = False)TEXT = ttd.Field(
sequential = True,
batch_first = True,
lower = True,
tokenize = 'spacy',
pad_first = True
)
LABEL = ttd.Field(sequential=False, use_vocab=False, is_target=True)dataset = ttd.TabularDataset(
path = 'data.csv',
format = 'csv',
skip_header = True,
fields = [('label', LABEL) ,('data' , TEXT)]
)ex = dataset.examples[0]train_dataset , test_dataset = dataset.split(0.66)
TEXT.build_vocab(train_dataset,)
vocab = TEXT.vocab
vocab.stoi
vocab.itostrain_iter, test_iter = ttd.Iterator.splits(
(train_dataset, test_dataset) , sort_key = lambda x: len(x.data),
batch_sizes = (2,2) , device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
)for inputs, targets in train_iter:
print("inputs:" , inputs, "shape:", inputs.shape)
print("targets:" , targets, "shape:" ,targets.shape)
break
for inputs, targets in test_iter:
print("inputs:" , inputs, "shape:", inputs.shape)
print("targets:" , targets, "shape:" ,targets.shape)
break

CNNs for Text
sequence
1-D convolution

For images:
2 spatial dimensions + 1 input feature dimensions + 1 output feature dimension = 4
for sequences:
1 time dimension + 1 input feature dimension + 1 output feature dimension = 3
경고: feature first
Recall that for images , pytorch cnn expects image to be N x C x H x W
"feature first"
whereas, in Tensorflow / OpenCV/ others, it's N x H x W x C
"feature last"
the torchvision data generators hide this detail
NLP, output of embedding is N x T x D ("feature last")
nn.Conv1d(), we expect N x D x T as input!("feature first")
그래서 , must reshape before and after convolutions
Text Classification with CNNs
output of embediding is alwasy (N, T,D)
conv1d expects (N, D, T)
=> out.permute(0,2,1)
change it back
out.permute(0,2,1)
cnn 도 경과가 좋게 나온다.
class CNN(nn.Module):
def __init__(self, n_vocab, embed_dim, n_outputs):
super(CNN, self).__init__()
self.V = n_vocab
self.D = embed_dim
self.K = n_outputs
self.embed = nn.Embedding(self.V, self.D)
self.conv1 = nn.Conv1d(self.D, 32, 3, padding = 1)
self.pool1 = nn.MaxPool1d(2)
self.conv2 = nn.Conv1d(32, 64, 3, padding = 1)
self.pool2 = nn.MaxPool1d(2)
self.conv3 = nn.Conv1d(64, 128, 3, padding = 1)
self.fc = nn.Linear(128, self.K)
def forward(self, X):
out = self.embed(X)
out = out.permute(0,2,1)
out = self.conv1(out)
out = F.relu(out)
out = self.pool1(out)
out = self.conv2(out)
out = F.relu(out)
out = self.pool2(out)
out = self.conv3(out)
out = F.relu(out)
out = out.permute(0,2,1)
out, _ = torch.max(out, 1)
out = self.fc(out)
return out
making predicions with Trained NLP Model
single_sentence = 'Our dating service has been asked 2 contast U by someone shy!'
toks= TEXT.preprocess(single_sentence)
sent_idx = TEXT.numericalize([toks])
model(sent_idx.to(device))
'교육동영상 > 02. pytorch: Deep Learning' 카테고리의 다른 글
| 09. Transfer Learning (0) | 2020.12.23 |
|---|---|
| 08. Recommender System (0) | 2020.12.21 |
| 06-2. Recurrent Neural Networks, Time Series, and Sequence Data (0) | 2020.12.14 |
| 06. Recurrent Neural Networks, Time Series, and Sequence Data (0) | 2020.11.20 |
| 05. Convolutional Nerual Networks (0) | 2020.11.19 |