**인터페이스 사용
1. 인터페이스
=>final 상수와 추상 메소드 만을 가진 개체
=>최근에는 default method(구현된 메소드)를 소유 가능
=>다른 클래스에 implements 해서 사용, 다른 Property클래스인터페이스에 entends 가능
2. 사용 목적
=>다형성 구현을 위해서
=>템플릿 메소드 패턴을 구현하기 위해서
인터페이스에 메소드의 모형을 만들고 클래스에서 구현하는 방식
클래스가 인터페이스를 implements했다면 클래스에는 인터페이스의 메소드가 구현되어 있다는 보장을 할 수 있습니다.
추상메소드는 상속받은 곳에서 반드시 재정의 해야 합니다.
overring안하면 안된다.
최소한 메소드는 만들어져 있다 고 보장할 수 있다.
인터페이스를 다른 말로 부를 때 protocol(규칙,규약,약속)이라고도 합니다.
collection 인터페이스
**자료구조(Data Structure)
=>0개 이상의 데이터를 저장하는 방법
=>예전에는 각 자료구조의 특징을 숙지하고 직저 구현을 해서 사용했는데 최근에는 프로그래밍언어에서 자료 구조를 미리 구현해놓고 이 자료구조를 가져다 사용하는 경우가 많습니다.
제공되는 자료구조는 프로그래밍언어마다 다르고 부르는 이름도 다릅니다.
r은 다르다.
자료구조 특징만 알면 된다.
python에서는 list특징만 주고 사용법만 아시면 된다.
=>알고리즘을 잘 설계하더라도 자료구조를 선택하면 속도 향상은 한계가 있습니다.
자료구조 알고리즘 자료구조를 먼저 선택하고 알고리즘을 한다.
=>자바의 경우는 자료구조 관련 클래스들이 java.util패키지에서 제공합니다.
java.lang ->java.util
**java.util의 자료구조 관련 인테페이스와 클래스
1.Arrays 클래스
=>배열 관련된 작업을 위한 클래스
=>배열의 특징(Array)
배열은 한 번 생성되면 크기 변경이 안됩니다.
배열은 데이터를 연속적으로 빈 공간 없이 배치해야 합니다.
배열은 공간낭비가 없습니다.
연속적으로 배치할 수 있는 빈 공간이 없으면 생성이 불가능
데이터를 삽입하거나 삭제하고자 할 때는 복사해서 작업을 수행해야 합니다.
크기 변경이 안되기 때문에 삽입할려면 새로운 공간을 할당받아서 삽입해야 하고 연속적으로 배치되어야ㅑ 하기 때문에 삭제를 할려면 삭제된 이후의 데이터를 앞으로 당겨야 하는 문제가 발생하기 때문입니다.
c언어는 배열을 stack에서 한다.
stack은 기본적으로 1mb크기다.
int ar[1000000] =>stackOverflow
그래서 c언어는 point만들고 참조형으로 한다.
java는 참조형으로 되여있다.heap에 저장한다.
머신런닝은 c 해야 할 가능성이 있다. python의 모든 라이버러리가 c나 java 등으로 되여있다. 많은 양의 데이터 가지고 할때 내부적으로는 c로 하고 가져고 온다. 대부분의 알고리즘은 c로 한다.c가 빠르기 때문이다.
삽입은 크기를 추가한다는 옮겨야 하기 때문에 복사하고 해야 한다.
삭제를 할 경우 연속적으로 빈 공간 없이 배치해야 하는 것은 삭제하면 빈공간이 생겨서 앞으로 땡겨야 한다. 그래서 앞으로 땡기는데 시간이 걸린다.
삽입 삭제를 거의 안하면 arrays로 만드는 것이다.
수정은 개수의 변화가 아니라 값이 변하는 것이다.
ar[0] = 10;
ar[0] = 20;//으로 변경
2.collection 인터페이스
=>데이터의 모임과 인터페이스
=>List와 Set인터페이스에게 상속
=>Collection들에 공통으로 구현해야 할 메소드를 선언
stack -> push
-> pop
ArrayList : add
list 개열은 add로 하면 좋지 않는가 ?
각기 다를 경우 그래서 인터페이스를 만들고 : add라고 하고 implements stack, ArrayList로 해주면 된다.
이름을 통일하게 하기 위해서 정해줄려고 collection인터페이스를 만들었다.
다시 collection을 분할 시켰다. list, set
BeanContext, BeanContextServices, BlockingDeque<E>, BlockingQueue<E>, Deque<E>, List<E>, NavigableSet<E>, Queue<E>, Set<E>, SortedSet<E>, TransferQueue<E>
public interface Collection<E>
extends Iterable<E>
Iterable=> for써서 하나씩 접근 하는 것이다.
python __iterable__
3.List 인터페이스
=>데이터를 물리적 또는 논리적인 순서대로 연속해서 저장하는 자료구조 인터페이스
=>ArrayList, LinkedList, Stack, Queue, Deque등에서 구현하거나 상속
python은 기본적으로 LinkedList 이고 문제 생겨서 후에 queue.를 추가하였다.
4.Set 인터페이스
=>데이터를 중복없이 해싱을 이용해서 저장하는 자료구조 인터페이스
=>HashSet, LinkedHashSet , TreeSet 클래스에서 구현
5.Map 인터페이스
=>key와 Value를 쌍으로 저장하는 자료구조 인터페이스
=>Table 또는 Dictionary라고도 합니다.
=>HashMap, LinkedHashMap, TreeMap 클래스에서 구현
python에서 ordered dict= >treeMap
6.Property클래스
=>KEY와 Value를 쌍으로 저장하는데 자료형이 String만 가능한 클래스
=>설정이나 메시지 저장에 많이 사용되는 클래스
7.Iterator & Enumeration
=>데이터를 순서대로 하나씩 접근할 수 있도록 해주는 포인터 : Cursor라고도 합니다.
=>자바에서는 Enumeration이 먼저 나왔고 후에 비슷한 기능을 개량한 Iterator가 추가 되었습니다.
=>우리말로 번역할 때는 반복자(c++ enumeration) 또는 열거자(python iterator) 로 변역
=>인터페이스가 구현된 컬렉션의 데이터는 for(임시변수 : 컬렉션){}구문을 이용해서 컬렉션의 모든 데이터를 임시변수에 하나씩 대입해서 {}안에서 사용할 수 있습니다.
=>Iterator의 메소드 :hasNext()(다음데이터 있느냐?)와 next()(다음 데이터 이동해라)
=>Enumeration의 메소드:hasMoreElements()와 nextElement()
**List
=>데이터를 순서대로 저장하는 자료구조
=>자료구조에서는 배열을 Dense List라고 하기도 합니다.
1.ArrayList(Vecor는 ArrayList의 Legacy버전)
=>데이터를 물리적으로 연속해서 저장하는 List
=>크기 변경이 가능(확장과 축소가 가능)
=>제너릭이 구현(인스턴스를 만들 때 데이터 1개의 자료형을 확정을 해야 합니다.)
=>인스턴스를 만들 때 자료형을 확정하지 않으면 경고가 발생하고 데이터를 가져올 때 Object타입으로 리턴되서 사용을 하고자 하면 강제 형 변환을 해야 합니다.
=> LinkedList 에 비해서 메모리 낭비가 적고 접근 속도가 빠릅니다.
=> LinkedList에 비해서 데이터를 중간에 삽입하거나 삭제하는 경우 속도가 느립니다.
LinkedList는 논리적으로 연속해서 데이터를 저장
=>주요 메소드로느 boolean add(E e), E get(int index), int size(),E remove(int index)(지울때 데이터를 return한다.), void sort(Comparator <E>) (데이터가 많을 때 ) 등이 있습니다.
2. LinkedList
=>데이터를 논리적으로 (다음 데이터의 참조를 기억) 연속해서 저장하는 List
=>사용하는 모든 메소드가 ArrayList와 같은데 동작 방식이 다름
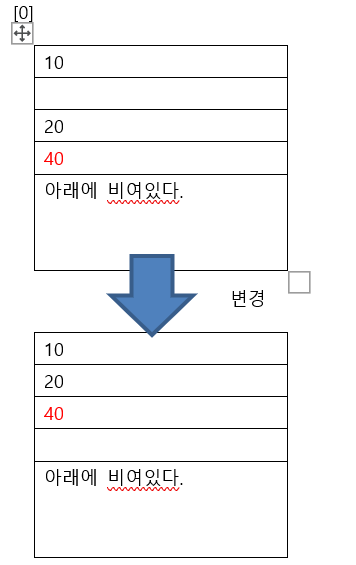
배열 10 , 30 ,20 하나하나 뛰여 쓰는 구조이다. 출발점 밖에 없다.
하나 뛰면 1 두개 뛰면 2


ArrayList 아래에 비여있다. 출발점 밖에 없다.

40추가시 복사 안하고 아래에 추가한다.
DoubleLinked List python 음수 양수 가능한 것은 head와 tail이 있기 때문이다.
0번이 없다. 한칸 가면 10
get할 때 음수를 사용할 수 있는 것

메모리가 심함 : 낭비가 적을 수도 있다.( 연속적인 공간, 확장이 가능하다.)
삽인과 삭제가 용이하다.
point로 한다.
메모리 충돌
재시작해서 하면 메모리 문제가 있ㄷ.

빈공간이 40m이지만 30m데이터를 열 경우
배열 과 arryaList. 는 저장이 불가하다. 연속적으로 해야 하기 때문에
그래서 DOuble Linked List 가능하다. 연결이 가능하다
공간1에서 20m할당하고 공간 2에서 10m할당한다.
ORACLE 9 I ->INTERNET
ORABLE 10 G -> 초과하면 메모리 따로 할당해서 가능하다.
30을 지울 경우
ArrayList 는 30을 지울 경우 땡겨줘야 한다. 아니면 접근이 불가하다.
마지막 지우는 것은 괜찮은데 중간에것 은 문제가 생긴다.
DoubleLinked List 30을 살제 할 경우 포인터를 바꾼다.


데이터 하나하나 접근해서 가져올때 늦다.
일부분만 하면 된다.

연결해서 필요한 결과만 가져오면 된다.
지금은 디스크가 크기 때문에 arrayList를 많이 사용한다.
데이터를 그냥 쌓고 썼다 삭제 할 필요 없다.
게시판 등 읽기만 가능할 때 ArrayList 를 많이 사용한다.
웹프로그래밍은 대부분 ArrayList 사용한다. 읽기라도 빨리 읽자
Double Linked List 서버 등 추가 삭제 많이 할때
python은 기본을 list로 주고 queue를 준다. queue 순서대로 끄낸다. Linked List읽기 속도가 늦다.
읽기 - ArrayList
삽입 삭제 - Linked List
ArrayList는 데이터가 많을 수록 늦게 걸린다. 오래 걸린다.
ArrayLIST는 밀어내기 해서 늦게 걸린다.
실습은 정수로 했지만 실제 는 row단위로 하면 더 오래 걸릴것이다.
알고리즘을 할 경우 시간 측정하기
정밀도나 재현율 등으로 해서 알고리즘 한다.
회사 : 마이다스아이티
3.ArrayList와 LinkedList 작업 속도 측정
public class ListCompare {
public static void main(String[] args) {
// 정수 데이터를 저장하는 ArrayList생성
// 제너릭에서는 기본형은 사용할 수 없음 - 기본형을 대체하는 Wrapper클래스 사용
ArrayList<Integer> a1 = new ArrayList<>();// ArrayList<> 1.7부터 가증하다.
// 데이터 삽입
a1.add(10);
a1.add(30);
// 데이터 1개 가져오기
Integer e = a1.get(0);
System.out.println(e);
// 데이터 1개 삭제
a1.remove(0);
// 데이터 전체 출력
for (Integer imsi : a1) {
System.out.println(imsi);
}
// 10과 30을 갖는 ArrayList생성
a1 = new ArrayList<>();// ArrayList<> 1.7부터 가증하다.
// 데이터 삽입
a1.add(10);
a1.add(30);
// 현재 시간 저장
long start = System.currentTimeMillis();
// 20이라는 데이터를 10만번 2번째 칸에 삽입
for (int i = 0; i < 100000; i++) {
a1.add(1, 20);
}
// 현재 시간 저장
long end = System.currentTimeMillis();
System.out.println("a1:" + (end - start));
// LinkedList 생성
LinkedList<Integer> li = new LinkedList<>();
// 데이터 삽입
li.add(10);
li.add(30);
// 현재 시간 저장
start = System.currentTimeMillis();
// 20이라는 데이터를 10만번 2번째 칸에 삽입
for (int i = 0; i < 100000; i++) {
li.add(1, 20);
}
// 현재 시간 저장
end = System.currentTimeMillis();
System.out.println("li:" + (end - start));
//데이터 읽기 ================================
// 현재 시간 저장
start = System.currentTimeMillis();
for (int i = 0; i < a1.size(); i++) {
//System.out.println(a1.get(i));
a1.get(i);
}
// 현재 시간 저장
end = System.currentTimeMillis();
System.out.println("a1읽기:" + (end - start));
// 현재 시간 저장
start = System.currentTimeMillis();
for (int i = 0; i < li.size(); i++) {
//System.out.println(li.get(i));
li.get(i);
}
// 현재 시간 저장
end = System.currentTimeMillis();
System.out.println("li읽기:" + (end - start));
}
}

4. Vector
=>ArrayList가 만들어지기 전에 ArrayList와 동일한 용도로 사용하던 자료구조인데 데이터를 수정하거나 삭제 할 떄 다른 스레드가 사용 중인지 확인하고 작업을 수행하던 클래스
=>java에서 Vector클래스는 최근에는 거의 사용을 하지 않기 때문에 중요하지 않을 수 있는데 c++하던 분들이 ArrayList라고 하지 않고 Vector라고 합니다.
vector 데이터의 모임 , scalar등 도 vector이기도 한다.
5.Stack
=>LIFO(Last In First Out)
=>마지막에 삽입된 데이터가 가장 먼저 출력되는 자료구조 클래스
=>데이터를 삽입하는 동작을 push라고하고 마지막 데이터를 꺼내는 동작을 pop이라고 합니다.
=>실제 사용된 곳은 메소드를 호출할 때 메소드가 저장하는 자신의 데이터 영역을 stack으로 만들고 스마트폰 등에서 화면 저장도 Stack을 사용합니다.
안드로이드는 startActivity finish
아이폰은 push pop으로 사용한다.
겹쳐놓고 사용하는 것이 stack이라고 한다.
=> 삽입은 E push(E e), 삭제는 E pop(), 삭제하지 않고 마지막 데이러를 가져오는 E peek()
=> 제너릭이 적용되어 있어서 인스턴스를 만들 때 저장할 요소의 자료형을 설정해야 합니다.
네비게이션
최악이는 array
arrayList와 LinkedList 출발점을 끝까지 가야 한다.
최근에 데이터 사용해야 하는 것은 stack이 좋다.
public class StackTest {
public static void main(String[] args) {
//문자열 저장하는 스택 생성
Stack <String> stack = new Stack<>();
//데이터 저장은 push
stack.push("안중근");
stack.push("윤봉길");
stack.push("김좌진");
//마지막 데이터 제거하면서 가져오기
String human = stack.pop();
System.out.println(human);
//마지막 데이터를 제거하지 않고 가져오기
human = stack.peek();
System.out.println(human);
human = stack.peek();
System.out.println(human);
}
}

=>Stack의 size를 설정한 경우에 Stack에 이미 데이터가 전부 저장된 상태에서 데이터를 push하는 경우를 Stack Overflow라고 합니다.
Stack에서 데이터가 없는 상태에서 pop을 하는 경우를 Stack Underflow라고 합니다.
6.Queue
=>FIFO(First In First Out)
=>먼저 삽입된 데이터를 먼저 제거하는 자료구조
=>자바에서는 인터페이스로 제공되고 여러 List클래스에 구현되어 있습니다.
=>PriorityQueue라는 우선순위 큐에도 구현되어 있습니다.
우선순위 큐는 우선순위에 따라 데이터를 정렬하고 있는 큐입니다.
=>데이터를 삽입하는 메소드는 add이고 데이터를 꺼내는 메소드는 peek와 poll
=>용도는 스케쥴링에 주로 이용
=>입력받은 내용을 순서대로 실행하고자 할 때 Queue를 이용합니다.
인쇠
데이터를 입력하면 priorityqueue는 순서대로 한다.
데이터 입력할때 이것 사용하면 sort할 필요없다.
정렬 할 필요 없다. PriorityQueue로 바꾸지 않고 Set을 이용하면 중복도 처리 할 필요 없다.
0번과 2번 지운다. 0번과 2번 지우면 에러 난다.
0번 지우면
지울 때 마다 땡겨줘야 한다. 그다음 2로 지워면 오류 난다. 사이즈나 인덱스가 변할 수있다.
그래서 뒤에서 부터 지운다.
정렬 -데이터 정렬
정렬 - 트리 형태의 정렬
정렬후

데이터 확정되면 quicksort등으로 만들면 되나.
데이터를 추가할 때마다 정렬할 경우 tree를 만든다. 작으면 왼쪽 크면 오른쪽
tree 읽는 방법 : InOrder .왼쪽 ->부모 -> 오른쪽
FreeOrder -> 부모
FirstOder -> 부모 마지막
PriorityQueue는 InOrder
하나씩 접근할 경우는 예측할 수 없다 . 전체 해야만 정렬이 된다.







이진트리 검색 이진트리 정렬
건물의 arrayList로 만들면 삽입과 삭제가 늦어서 버벅거린다.
실습
public class QueueTest {
public static void main(String[] args) {
//운선순위 큐: 데이터를 크기 순서대로 접근할 수 있도록 만든 큐
//내부적으로 데이터가 정렬된 것이 아니고 정렬된 순서대로 접근할 수 있는 이진 트리를 생성
//문자열 저장하는 스택 생성
PriorityQueue <String> pq = new PriorityQueue<>();
//데이터 저장은 push
pq.add("서울");
pq.add("런던");
pq.add("크라이스 처치");
pq.add("블라디보스톡");
pq.add("불산");
//PriorityQueue 크기 순서대로 저장 되였다고 했는데
//빠른 열거를 이용해서 데이터를 1개 씩 꺼내와서 출력
//sort가 되지 않았다.
//하나씩 꺼내면 트리의 순회를 이용하지 않기 때문에 데이터가 정렬된 순서가 아닐 수 있음
for(String city :pq) {
System.out.print(city + "\t");
}
System.out.print("\n");
//데이터를 poll이용해서 1개씩 가져와서 출력
//sort된 순서데로 나온다.
//pq.size()쓰면 안된다 . 5로 사용해야 한다.
//poll은 제거하면서 가져오기 때문에
//지우면서 가져올 때 데이터의 개수나 인덱스가 변할 수 있으므로 주의
//트리의 순회를 이용하기 때문에 데이터가 정렬된 순서대로 출력
int len = pq.size();
for (int i = 0; i < len; i++) { //5를 고정하거나 데이터 개수를 고정해야 한다.
System.out.print(pq.poll() + "\t");
}
// i pq. size()
// 0 5 pq.poll()삭제씩 한다.
// 1 4
// 2 3
//장바구니 할 경우 조심해야 한다.
}
}

7.Deque
=>양쪽에서 삽입과 삭제가 가능한 자료구조
=>자바에서는 인터페이스 형태로 제공
=>ArrayDeque라는 클래스가 Deque인터페이스를 Implements
=>Deque를 구현한 경우는 ScrollView 계열이 전부 Deque를 이용합니다.
메모리는 위에것을 재사용한다. deque를 재사용하는 것이다. 핸드폰 넘길 때
애플의 api를 한번 확인해보라
애플은 일반 숫자면 shift사용하면 된다.
windows안된다.
0 1 2 3
0 1 2 4 8
애플 된다. shift계산
0 1 2
0 << 0 1 << 0 1 << 2
=>삽입하거나 꺼내는 메소드 이름들에 First와 Last가 붙습니다.
어떤 종류의 데이트를 저장할 지 먼저 생각해야 한다.
ArrayDeque <String> deque = new ArrayDeque <>();
//데이터를 앞에서 저장
deque.addFirst("한국");
//데이터를 뒤에 저장
deque.addLast("미국");
deque.addLast("중국");
deque. addFirst("뉴질랜드");
저장 순서는 뉴질랜드 -> 한국->미국 -> 중국
String nation = deque.pollFirst();//뉴질랜드
nation = deque.pollLast();//중국
8. 사용자 정의 클래스의 List 정렬
=>사용자 정의클래스의 LIST가 테이블 구조
몽고 디비의 COLLECTION이라고 보면 된다.
// 선수번호(정수인데 Primary Key) ,선수이름, 타율
//primary key는 정수 인것이 좋다. 속도 때문에
public class Player {
private int num;
private String name;
private double hitrate;
//매개변수가 없는 생성자
public Player() {
super();
}
//모든 필드를 매개변수로 받아서 인스턴스 필드에 대입해주는 생성자
public Player(int num, String name, double hitrate) {
super();
this.num = num;
this.name = name;
this.hitrate = hitrate;
}
//인스턴스 필드들을 private로 만들어서 인스턴스가 접근을 못합니다.
//인스턴스가 필드들에 접근할 수 있도록 해주는 메소드: 접근자 메소드(getters & setters)
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getHitrate() {
return hitrate;
}
public void setHitrate(double hitrate) {
this.hitrate = hitrate;
}
//필드의 값을 빠르게 확인하기 위한 메소드 : 디버깅을 위한 메소드
@Override
public String toString() {
return "Player [num=" + num + ", name=" + name + ", hitrate=" + hitrate + "]";
}
}
public class ListMain {
public static void main(String[] args) {
//매개변수가 없는 생성자를 이용한 인스턴스 생성 및 필드값 실행
Player player1 = new Player();
player1.setNum(1);
player1.setName("백인천1");
player1.setHitrate(0.412);
//매개변수가 있는 생성자를 이용한 인스턴스 생성 및 필드값 설정
Player player2 = new Player(2,"이종범2",0.393);
Player player3 = new Player(3,"이종범3",0.381);
Player player4 = new Player(4,"이종범4",0.387);
Player player5 = new Player(5,"이종범5",0.376);
//5개의 인스턴스를 소유한 ArrayList 인스턴스 생성
ArrayList<Player> list = new ArrayList<>();
list.add(player1);
list.add(player2);
list.add(player3);
list.add(player4);
list.add(player5);
//Player 클래스의 인스턴스 비교 인스턴스 파율의 오름차순
//anorymose, new Comparator<Player> 를 쓰야 한다.
//이것이 된다면 어떤 종류에서도 다 가능핟.
Comparator<Player> comparator = new Comparator<Player>() {
@Override
public int compare(Player arg0, Player arg1) {
/*if(arg0.getHitrate() > arg1.getHitrate()) {
return 1;
}else if(arg0.getHitrate() == arg1.getHitrate()) {
return 0;
}else {
return -1;
}*/
return arg0.getName().compareTo(arg1.getName()) * -1;
}
};
list.sort(comparator);
//데이터 출력
for(Player player: list) {
System.out.println(player);
}
}
}
** Set
=>데이터를 해싱을 이용해서 저장위치를 선정하고 중복된 데이터는 저장하지 않는 자료구조
=>데이터의 저장 순서를 모르기 때문에 인덱스의 개념이 없습니다.
=>제너릭이 구현:인스턴스를 만들 때 요소의 자료형을 결정
1.구현된 클래스
HashSet: 저장 순서를 알 수 없는 sET
LinkedHashSet: 저장 순서를 알 수 있는 Set으로 전체를 순서래도 접근하면 저장된 순서래도 리턴
TreeSet :Comparator 인터페이스의 compareTo 멤서도를 이용해서 크기 순서대로 리턴하는 sET
2.주요 메소드
boolean add(E e): 데이터를 추가하고 성공 여부를 리턴 ,동일한 값의 데이터를 삽입할려고 하면 데이터를 삽입하지 않고 FALSE를 리턴
boolean remove(E e): e에 해당하는 데이터가 있음녀 삭제하고 결과를 리턴
int size(): 데이터 개수 리턴
데이터 1개를 접근하는 메소드는 없고 FOR(임수 변수 , set)을 이용해서 데이터 전체를 접근
데이터 한개를 꺼내는 메소드가 없다.
3.Set사용
public class SetUse {//Set로 이름 하면 에러가 난다.
public static void main(String[] args) {
// Set 인스턴스 생성 - HashSet ,LinkedHashSet , TreeSet으로 변경하면서 확인
System.out.println("HashSet");
Set<Integer> set = new HashSet<Integer>();
// Set 에 데이터 추가
set.add(100);
set.add(300);
set.add(200);
set.add(500);
set.add(400);
// 데이터 전부 출력
for (Integer temp : set) {
System.out.println(temp);
}
System.out.println("LinkedHashSet");
// Set 인스턴스 생서
Set<Integer> linkedHashSet = new LinkedHashSet<Integer>();
// Set 에 데이터 추가
linkedHashSet.add(100);
linkedHashSet.add(300);
linkedHashSet.add(200);
linkedHashSet.add(500);
linkedHashSet.add(400);
// 데이터 전부 출력
for (Integer temp : linkedHashSet) {
System.out.println(temp);
}
System.out.println("TreeSet");
// Set 인스턴스 생서
Set<Integer> treeSet = new TreeSet<Integer>();
// Set 에 데이터 추가
treeSet.add(100);
treeSet.add(300);
treeSet.add(200);
treeSet.add(500);
treeSet.add(400);
// 데이터 전부 출력
for (Integer temp : treeSet) {
System.out.println(temp);
}
}
}

4. 1-45사이의 숫자를 6개 입력받아서 오름 차순 정렬해서 출력
=>데이터 6개는 하나의 이름으로 저장
=>동일한 데이터는 입력받지 않아야 합니다.
=>데이터는 오름차순 정렬
=>데이터 6개를 하나의 이름으로 저장할 수 있는 자료구조 :배열 ,ArrayList, LinkedList, Stack ,ProrityQueue, ArrayQueue, HashSet,LinkedHashSet, TreeSet
public class LottoInput {
public static void main(String[] args) {
//1-45까지의 정수를 저장할 자료구조를 생성
TreeSet<Integer> lotto = new TreeSet<Integer>();
//키보드로 부터 입력받기 위한 인스턴스 생성
Scanner sc = new Scanner(System.in);
while(lotto.size() < 6) {
try {
System.out.print("1-45까지의 중복되지 않은 숫자 :");
//문자를 입력해서 예외가 발생하면 catch구문이 동작하고 그러면 반복문의 시작 부분으로 돌아가서 수행
int su = sc.nextInt();
if(su < 1 || su > 45) {
System.out.println("1-45 사이의 숫자만 입력하세요 !!!");
continue;
}
//입력받은 숫자를 set에 추가 : 숫자가 중복되면 false
boolean result = lotto.add(su);
if(result == false) {
System.out.println("중복된 숫자는 안됩니다.");
}
}catch(Exception e) {
System.out.println("1-45 사이의 숫자만 입력하세요 !!!");
sc.nextLine();
}
}
//lotto 데이터 출력
for(Integer su : lotto) {
System.out.print(su + "\t");
}
sc.close();
}
}
**Map
=>key와 Value를 쌍으로 저장하는 자료구조
=>key는 중복될 수 없지만 Value는 중복되거나 null일 수 있습니다.
=>제너릭 미지정 자료형이 2개라서 인스턴스를 생성할 떄 key와 Value자료형 2개를 설정해야 합니다.
key는 특별한 경우가 아니라면 String
=>여러 종류의 데이터를 하나로 묶기 위한 용도로 주로 이용
DTO클래스의 용도와 유사
=>관계형 데이터베이스의 테이블은 DTO클래스의 List이고 No SQL의 Collection은 Map의 List입니다.
=>Map.은 Key를 무한정 추가시킬 수 있습니다.
DTO클래스는 클래스를 만들 때 사용한 필드를 제외하고는 확장이 안됩니다.
1.Map 구현 클래스
1) HashMap(Hashtable): Key를 해싱에 의해서 저장하기 때문에 key의 순서를 알 수 없습니다.
2) LinkedHashMap : KEY가 데이터를 저장한 순서대로 배치
3) TreeMap: key 가 COMPAREtO메소드를 이용해서 비교한 후 크기 순선대로 배치
2.인스턴스 생성
HashMap<String ,실제데이터의 자료형> map = new HashMap<String ,실제데이터의 자료형>();
HashMap<String ,실제데이터의 자료형> map = new HashMap<? ,?>();
3.데이터 관련 메소드
void put(key ,value): key 값에 VALUE를 저장, 동일한 KEY이름을 입력하면 수정
Object get(key) :key에 해당하는 값 리턴, key가 없으면 null리턴
리턴되는 데이터가 Object라서 출력하는 것이 아니고 사용할 거라면 저장할 때의 자료형으로 강제 형 변환해서 사용
Object remove(key) : key에 해당하는 데이터 삭제
Set<Key의 자료형> keySet(); Map의 모든 key를 Set으로 리턴
4.Map의 기본방법
public class MapUse {
public static void main(String[] args) {
// Map 인스턴스 생성
HashMap<String, Object> map = new HashMap<String, Object>();
// 데이터 저장
map.put("baseball", "야구");
map.put("soccer", "축구");
map.put("volleyball", "배구");
// 데이터 가져오기
// Object obj = map.get("soccer");
/// 출력을 할 때는 강제 형 변환이 필요없지만 다른 용도로 사용할 때는 강제 형 변환을 해서 가져옵니다.
String obj = (String) map.get("soccer");
System.out.println(obj.toUpperCase());
// 없는 key의 값 가져오기 -언어마다 다르므로 확인
Object value = map.get("basketball");
System.out.println(value);// java- null python은 튕긴다.
map.put("soccer", "발로하는 축구");
obj = (String) map.get("soccer");
System.out.println(obj.toUpperCase());
// Map의 모든 데이터를 출력 -key의 이름을 사용하지 않음
System.out.println("===============================");
Set<String> keys = map.keySet();
// Set을 순회
for (String key : keys) {
System.out.println(key + " : " + map.get(key));
}
System.out.println("=============LinkedHashMap==================");
// 순서대로 하고 싶다면 LinkedHashMap으로 바꾸면 된다.
// Map 인스턴스 생성
LinkedHashMap<String, Object> map1 = new LinkedHashMap<String, Object>();
// 데이터 저장
map1.put("baseball", "야구");
map1.put("soccer", "축구");
map1.put("volleyball", "배구");
// 데이터 가져오기
// Object obj = map.get("soccer");
/// 출력을 할 때는 강제 형 변환이 필요없지만 다른 용도로 사용할 때는 강제 형 변환을 해서 가져옵니다.
String obj1 = (String) map1.get("soccer");
System.out.println(obj1.toUpperCase());
// 없는 key의 값 가져오기 -언어마다 다르므로 확인
Object value1 = map1.get("basketball");
System.out.println(value1);// java- null python은 튕긴다.
map1.put("soccer", "발로하는 축구");
obj1 = (String) map1.get("soccer");
System.out.println(obj1.toUpperCase());
// Map의 모든 데이터를 출력 -key의 이름을 사용하지 않음
System.out.println("===============================");
Set<String> keys1 = map1.keySet();
// Set을 순회
for (String key : keys1) {
System.out.println(key + " : " + map1.get(key));
}
}
}
mac은 메뉴 눌리다가 실수 할 가능성이 없다.
windows는 여러가 나온다.
5. class와 Map을 이용한 저장의 차이
public class ClassAndMap {
public static void main(String[] args) {
//번호 ,이름,타율을 저장하는 Player클래스의 인스턴스를 만들어서 데이터를 저장
Player player = new Player(1, "이종범" , 0.393);
//Player 코드 셋
//3개를 저장하는 map을 인스턴스를 생성해서 데이터를 저장
HashMap<String,Object> map = new HashMap<String,Object>();
map.put("num", 2);
map.put("name", "정호조");
map.put("hitrate", 0.387);
//서로간의 장단점이 있다.
//대부분의 IDE에서 일반 인스턴스를 사용할 때 Code sense가 동작
//하나의 속석을 가져올 때는 클래스가 유용
//map은 key를 기억해야 합니다.
String name = player.getName();//오타칠 가능성이 별로 없다.
name = (String)map.get("name");
//전체를 출력할 떄나 속성을 확장할 떄는 Map이 유리
//Dto클래스의 인스턴스는 속성 확장이 안됩니다.
//dto클래스의 인스턴스는 속성을 확장할려면 클래스 구조를 변경해야 합니다.
//테이블 설계하면 아무것도 추가 못한다. ->관계형 데이터베이스
//map은 제한이 없음
map.put("homerun", 31);//필요하면 얼마든지 확장 할 수 있다.
//전체를 출력한다면 map이 훨씬 편하다.
//DTO클래스의 인스턴스는 각각의 데이터를 하나씩 출력해야 한다면 메소드를 일일이 호출 : 반복문 사용 불가
System.out.println(player.getNum());
System.out.println(player.getName());
System.out.println(player.getHitrate());
//mAP의 인스턴스는 KEYSET()을 이용해서 반복문으로 출력 가능
Set<String> keys = map.keySet();
for(String key : keys) {
System.out.println(key + " : " + map.get(key));
}
}
}
6. 이차원 배열과 Map의 List
List의 List(Matrix - numpy 머신런닝)와 Map의 List(DataFrame - pandas기술통계 )
데이터가 바꿔더라도 연산의 결과등으로 사용 가능하게 해야 한다.
자바스크립트
angular react native
map을 잘 사용하면 mvc를 하는데 도움이 된다.
배열에 배열 나올 것 같으면 고민해야 한다.
머신런닝 이름이 필요없기 때문에 배열의 배열을 사용한다.
2차원 벼열 : 제목이 없는 matrix 계산
|
74
|
83
|
76
|
|
32
|
54
|
68
|
|
64
|
74
|
83
|
map의 List 출력이나 분석
|
국어
|
영어
|
수학
|
|
74
|
83
|
76
|
|
32
|
54
|
68
|
|
64
|
74
|
83
|
합계를 구할 때 map의 list는 제목을 빼고 해야 한다. .values()
microsoft는 windows는 list안에 list
mac은 map으로 한다음 다시 map의 list로 만든다.
출력은 운영체제가 해버린다.
public class DoubleArray {
public static void main(String[] args) {
//각 팀별 선수 명단
ArrayList<String> kia = new ArrayList<>();
kia.add("최형우");
kia.add("김주찬");
kia.add("김선빈");
ArrayList<String> dusan = new ArrayList<>();
dusan.add("권혁");
dusan.add("정수빈");
dusan.add("최주환");//데이터 추가시 출력하는데 문제가 없다.
//팀이름은 가지고 있지 않다
//후에 추가한다.
ArrayList<String> hanhwa = new ArrayList<>();
hanhwa.add("김태군");
hanhwa.add("이성열");
//팀별 명단을 다시 List로 만들기
ArrayList<ArrayList<String>> players = new ArrayList<ArrayList<String>>();
players.add(kia);
players.add(dusan);
//팀이 추가되는 경우 팀 이름을 출력하기 위해서 출력하는 로직을 수정
players.add(hanhwa);
//데이터 출력하기
//전체 리스트를 하나 하나의 리스트로 imsi에 대입
for(ArrayList<String> imsi: players) {
//imsi의 데이터를 하나씩 temp에 대입
for(String temp : imsi) {
System.out.print(temp + "\t");
}
System.out.println();
}
//팁이 불 명확하다.
System.out.println("=======================");
for(int i = 0 ; i < players.size(); i++) {
//팀이 추가할 경우 문제가 생긴다.
if(i == 0) {
System.out.println("기아:");
}else {
System.out.println("두산:");
}
ArrayList<String> imsi = players.get(i);
//imsi의 데이터를 하나씩 temp에 대입
for(String temp : imsi) {
System.out.print(temp + "\t");
}
System.out.println();
}
System.out.println("=======================");
//앞에서의 문제는 List의 List를 만들 때 각 List의 특징을 같이 저장하지 못한다는데 있습니다.
//팀이름은 문자열이고 팀의 선수 명단은 배열이라서 같이 List에 저장을 못합니다.
//이 부분을 Map이나 Class로 해결해야 합니다.
//List와 팀이륾을 갖는 Map을 생성
Map<String, Object> map1 = new HashMap<String, Object>();
map1.put("team", "기아");
map1.put("player", kia);
Map<String, Object> map2 = new HashMap<String, Object>();
map2.put("team", "두산");
map2.put("player", dusan);
//후에 추가하기
Map<String, Object> map3 = new HashMap<String, Object>();
map3.put("team", "한화");
map3.put("player", hanhwa);
//MAP의 lIST를 생성
ArrayList<Map<String, Object>> kbo = new ArrayList<Map<String, Object>>();
kbo.add(map1);
kbo.add(map2);
kbo.add(map3);
for(Map<String,Object> map : kbo) {
System.out.print(map.get("team") + ":");
ArrayList<String> p = (ArrayList<String>)map.get("player");
for(String temp : p) {
System.out.print(temp + "\t");
}
System.out.println();
}
}
}
7.데이터 저장
1)하나의 행은 Map이나 DTO클래스를 이용
=>mAP이나 DTO클래스는 서로 다른 자료형의 데이터를 묶어서 저장이 가능합니다.
=>lIST나 배열은 동일한 종류의 데이터를 묶어줍니다.
=>lIST나 배열로는 특성이 다른 데이터를 묶을 수 없습니다.
PYTHON에는 ["Hi" ,1 ] : ? =>이렇게 안한다.
list는 열

문자와 숫자가 있을 경우 숫자로 바꾼다. 수자인데 문자로 들어오면 오류 나기 때문이다.
2)하나의 열을 만들 떄 List나 배열을 사용
=>열 방향의 데이터는 일반적으로 동일한 자료형으로 구성되기 때문입니다.
**MVC(Model -View - Contrlloer)패턴
=>애플리케이션을 구현 할 때 역할 별로 분리해서 구현하도록 하는 패턴
=>애플리케이션을 역할 별로 잘 구별해서 분리하지 않으면 어느 하나의 변경이 다른 하나의 변경에 영향을 미치게 됩니다.
유지보수가 어려워집니다
=>Model에 변화가 생기더라도 View를 변경하지 않아도 되도록 구현하라는 패턴
***** dto클래스를 만들때와 map일떄를 비교해라
관계형 데이터베이스는 dto클래스의 리스트
nosql은 MAP의 리스트
MAP은 . 찍으면 안나와서 실수 문제
"NUM" -> "num"
대소문자 실수 많이 한다.
문자열로 할 경웨에는 주의 해서 봐야 한다.