제약 조건
default 입력하지 않을 경우 값을 설정

network을 타고 간다. 데이터 변질 될 가능성이 있어서 데이터 검증해야 한다.
데이터베이스에서도 해야 한다.
r 데이터 있을 경우 먼저 정제 한다.->안맞는 데이터 빼기 정재한다.
client -> smart phone app, web brower
데이터입력: check
client ->javascript 불필요한 트래픽 안 쓴다. 보안 이슈
소스 보이면 해킹의 위험성 있다.
server->서버코드는 보이지 않는다.
response시 데이터 확인 그래서 체크 다시 한번 하는게 좋다.
request에서 도 데이터 다시 확인 하는게 좋다.안정성 문제가 있을 수 있다.
db에서 유효성 검사 를 하는게 좋다.->제약조건
데이터 변질 문제를 조심해야 한다.
데이터 생성 ->전송 처리 하고 분석
최근에는 발생한 곳에서 하는게 낳다.
unique 유일성
별명으로 쓰기
not null:필수
unique:유일성
primary key:테이블에서 행을 구분 not null이고 unique(1개만 지정가능)
check 데이터 종류 제한
테이블 설계=>이상현상 제거를 위해서 테이블 분석:정규화(mongodb차이점)
주민번호
이름
수강과목
수강료
전화번호

1번학생 전화 바꿔야 할 경우 2번 바꿔야 한다.
transaction문제 발생할 수 있다.
sql하나만 쓸 수 있다면
누군가가 다른 하나를 결정내릴 수 있다면 쪼개라
|
주민번호 |
이름 |
전화번호 |
|
1 |
김 |
010 |
|
2 |
최 |
011 |
|
1 |
김 |
010 |
|
주민번호 |
수강과목 |
|
1 |
python |
|
2 |
python |
|
1 |
java |
|
수강과목 |
수강료 |
|
python |
320,000 |
|
java |
330,000 |
1번학생이 수강료 합계:join을 하면 먼저 cartesion product생긴다. 모든 조합 만들어서 filter한다.
테이블 쪼개만 좋다. 현업에서는 조회속도가 늦어진 문제 때문에 합친다.
하나의 테이블로 하고 안쪼개는 것이 no sql이라고 한다.

no sql 트랜잭션 문제가 있다.
foreign key 예:학번이 3번인 분이 과목을 직접 신청할 경우 학생테이블에 없어서 여고 해야 하는 문제점을 해결
foreign key 설정
=>2개 테이블의 대응수(cardinality) 조사
1:1 : 양쪽의 기본키를 다른 테이블에 외래키로 추가
1:n : 1쪽의 기본키를 n쪽의 외래키로 추가
n:n : 양쪽의 기본키를 가지고 외래키로 갔는 별도의 테이블을 생성
회원의 게시판
회원정보
ID(primary key )
PW
NAME
게시물 정보
num(글번호 primary key)
title
content
file
id(foreign key 회원정보테이블 뒤에 옵션 추가(delete on cascade, delete set null))
이를 경우 글을 쓴 회원 회원테이블에서 못 지운다.
delete on cascade 회원테이블 삭제시 게시물에 있는것 다 지운다.
delete set null 회원테이블 삭제시 게시물에 null로 된다.
참조 안하게 하는 방법: delete on cascade, delete set null

무결성 제약 조건:
=>개체 무결성 : 기본키는 NULL이거나 중복 될 수 없다.(테이블 하나)
=>참조 무결성 : 외래키는 NULL이거나 참조 할 수 있는 값 만을 가져야 한다.(테이블 2개)
제약조건은 모든 관계형 데이터 같다.
sqllite등 제약조건은 같다. fk는 안된다. 참조 시 delete on cascade 설정은 되는데 삭제는 안되서 trigger해야 한다.
access에서는 화면에서 잘 사용한다. excel하고 비슷하다.
sqllite는 기능이 떨어진다.
hana db , access등 비슷하다.
sqllite는 일시적으로 데이터를 저장하려고 해서 안되는 것이 좀 있다.
**제약조건(constraint)
=>테이블에 데이터를 저장할 때 반드시 지켜야 하는 조건
=>제약조건을 위반해서 데이터 삽입이 안되는 경우
dept테이블의 기본키는 deptno
deptno 는 중복될 수 없고 null일 수 없습니다.
INSERT INTO DEPT (DEPTNO, DNAME,LOC)
VALUES (01, '영업','서울');
--10번이 존재하기 때문에 삽입 에러가 발생합니다.
--제약조건 위반이라는 에러 메시지가 출력
--SQL Error [1] [23000]: ORA-00001: unique constraint (SCOTT.PK_DEPT) violated
--PK_DEPT라는 제약조건 위반
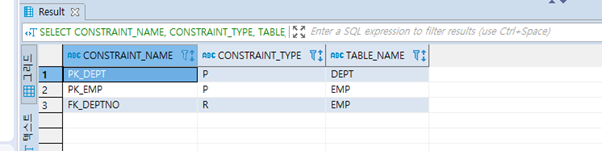
1.제약조건 확인
=>자신이 소유하고 있는 개체에 대한 정보는 USER_개체S 테이블에 저장되어 있습니다.
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME
FROM USER_CONSTRAINTS;
2.제약조건 type
1). P: primary key
2). R: foreign key
3). C: CHECK와 NOT NULL
4). U: UNIQUE
3,제약조건 설정
create table 테이블이름(
열이름 자료형 [constraint 제약조건이름] 제약조건 종류,
열이름 자료형 [constraint 제약조건이름] 제약조건 종류,
.........
[constraint 제약조건이름] 제약조건 종류(컬럼이름));
=>열을 만들때 설정하는 제약조건을 컬럼레벨 제약조건이라고 하고 열에 대한 정의를 전부하고 나중에 만드는 제약조건을 테이블 레벨 제약조건이라고 합니다.
=>예외는 하나 있다. not null은 반드시 컬럼 레벨에서 설정해야 합니다
null을 저장하는 방식에 대해서 알아두어야 한다.
4.데이터베이스에서 null저장
temp1 varchar(10) not null,
temp2 varchar(10)
temp1은 10byte를 할당 받는다.
temp2는 null 여부를 저장하기 위한 1바이트를 추가로 설정합니다.
temp2는 11바이트를 할당받아서 사용
a = null일 경우 a.하면 오류난다. nullpoint excetption
if a != null:
if a: ->저장공간에 가서 null인지 아닌지 확인해야 한다.
!a->절대 null일 수 없어
|
1 |
|
|
|
|
|
|
|
|
|
|
null허용시 1 byte더 준다.
1byte에서 확인한다.
5.작성
회원테이블
-email:문자 50자 이내 변경 불가능 -기분키
-pw:문자 15자 이내 변경을 자주 – 필수
- nickname:한글 10자 이내이고 변경 불가능 –중복 불가능 유일
==>컬럼 레벨 제약조건을 이용해서 테이블을 생성
=> varchar2는 저장되는 데이터 크기에 따라 저장공간이 변합니다.
char는 한 번 설정하면 저장되는 데이터 크기와 상관없이 크기는 고정
자주 변경되는 데이터는 char로 만드는데 varchar2 로 만들게 되면 데이터의 크기가 변경될 때저장 공간이 부족하면 row migaration( 행 이주)를 수행해서 작업 속도가 현저하게 떨어질 수 있습니다.
drop table member;--기존의 member 테이블이 존재하면 삭제
create table member(
email varchar2(50) primary key,
pw char(15) NOT NULL,
nickname varchar2(30) UNIQUE);
--컬럼레벨에서 설정 하는 것이다.
6.제약조건 이름
==>제약조건을 만들 때 제약조건 이름을 생략하면 오라클이 제약조건 이름을 임의로 생성합니다.
==>제약조건을 삭제하거나 변경하고자 할 때 자신이 만든 이름이 아니기 때문에 찾을 때 어렵습니다.
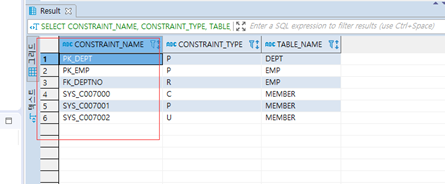
위처럼 제약조건 이름없이 생성하는 것 보다는 제약조건 이름을 추가해서 생성하는 것을 권장
drop table member;
create table member(
email varchar2(50) CONSTRAINT member_pk primary key,
pw char(15) CONSTRAINT member_nn NOT NULL,
nickname varchar2(30) CONSTRAINT member_uk UNIQUE);
=>제약조건 이름을 만들 때는 관습적으로 테이블이름 과 제약조건 종류를 합쳐서 만듭니다.

제약조건을 잘 해야 한다.
연동만 하고 제약조건을 하는게 좋다.
check는 열이름을 만든다.
7 체크 제약 조건 설정
check(컬럼이름 조건):
성별은 남 또는 여 만 가져야 한다.
gender varchar2(3) check(gender in (‘남’,’여’))
점수는 0-100사이의 값만 가져야 한다.
score number(3) check (score between 0 and 100)
데이터베이스 설계시 숫자데이터 확인하는게 좋다.
백분율 , 1.0 등 문제
--바로 하면 안된다.
데이터 정규화 와 표준화
case 1. 국어 0~100
영어 0 ~ 1000
case 2. 국어 80~100
영어 0 ~ 20
최대값 나눈다.
절대적인 수치를 저장할 수 있지만 상대적인 비율로 저장 하는 게 나중에 효율적이다.
색상 0 ~ 255
127
0.5 ->수정할 필요 없다.
비율 값을 저장하면 효율적이다
8.외래키 제약조건
=>컬럼레벨에서 설정
references 참조할 테이블 이름(참조할 열 이름)옵션
참조할 테이블 이름->부모이름
==>옵션을 생략하면 참조하는 테이블에 있는 값은 참조되는 테이블에서 삭제할 수 없습니다./옵션을 생략하면 부모테이블에서 외래키로 설정된 값을 삭제할 수 없습니다.
==>옵션은 2가지가 있는데 하나는 부모 테이블에서 삭제될 때 자식 테이블에서 같이 삭제되도록 할 수 있고 다른 하나는 값을 null로 변경해주는 것입니다.
on delete cascade:같이 삭제
on delete set null:null로 변경
==>외래키로 설정되는 키는 그 테이블에서 primary key 이거나 unique이어야 합니다.
데이터베이스 이론 책에는 primary key이어야 한다고 나옵니다.
==>dept테이블에서 deptno가 10인 데이터를 삭제
SELECT *
FROM DEPT d;
DELETE FROM DEPT d
WHERE DEPTNO = 10;
--SQL Error [2292] [23000]: ORA-02292: integrity constraint (SCOTT.FK_DEPTNO) violated - child record found
==>삭제 실패를 하게 되는데 emp 테이블에서 옵션없이 deptno를 참조하기 때문에 emp테이블에서 10을 저장하고 있으면 삭제가 안됩니다.
dept 테이블 자체도 삭제가 안됩니다.
drop table member;--기존의 member 테이블이 존재하면 삭제
create table member(
email varchar2(100) primary key,
pw char(15) NOT NULL,
nickname varchar2(30) UNIQUE);
--데이터 삽입
INSERT INTO MEMBER (email, pw, nickname)
values('djkfd@nave.com','1234','군계');
--게시판
CREATE TABLE board (
num NUMBER(5) PRIMARY KEY,
title varchar2(100),
content varchar2(1000),
email varchar2(100) REFERENCES "MEMBER"(email) ON DELETE CASCADE
);
INSERT INTO board (num, title,content,email)
values(1,'제목','내용','111@naver.com');
--삽입 실패 :email 이 member테이블의 email을 참조하는 외래키로 설정
--member테이블에 없는 값은 삽입할 수 없습니다.
--SQL Error [2291] [23000]: ORA-02291: integrity constraint (SCOTT.SYS_C007013) violated - parent key not found
INSERT INTO board (num, title,content,email)
values(1,'제목','내용','djkfd@nave.com');
SELECT *
FROM board;
=>member테이블에서 email이 djkfd@nave.com인 데이터를 삭제
borad테이블을 만 들 때 외래키 옵션이 on delete cascade라서 board테이블에서도 데이터가 삭제됩니다.
DELETE FROM MEMBER
WHERE EMAIL = 'djkfd@nave.com';

--부모 테이블 삭제 명령
drop table member;
==>SQL Error [2449] [72000]: ORA-02449: unique/primary keys in table referenced by foreign keys
테이블 drop할때는 안된다. 참조하는 테이블 이 없어도
drop, alter을 할경우 데이터 있는 것과 상관 없고 테이블 관계로 삭제하는지 한다.
그래서 drop할려면 게시판 테이블 부터 지워야 한다.
에러가 발생하는데 테이블의 구조를 변경하거나 삭제하는 명령은 데이터를 확인하지 않고 테이블 사이의 관계만 확인해서 수행여부를 결정합니다.
9.default
=>데이터를 입력하지 않았을 떄 자동으로 삽입하는 값을 설정할 때 사용하는 옵션
default 값의 형태로 설정
=>regdate는 오늘 날짜를 기본값을 설정
regdate default sysdate
=>readcnt값은 기본값으로 0을 설정
readcnt default 0
10.테이블 레벨 제약조건 설정
==>열을 생성할 때 제약조건을 설정하지 않고 열을 전부 생성한 후 마지막에 제약조건을 설정하는 것
제약조건이름(열 이름)의 형태로 설정
==>외래키는 foreign key(열 이름) references 부모테이블(열 이름) 옵션의 형태로 설정
==>반드시 테이블 레벨에서 제약조건을 설정해야 하는 경우가 있는데 기본키를 2개 이상의 열로 만들 때 입니다.
==>기본키를 2개 이상의 컬럼으로 만들게 되면 컬럼레벨에서 2개 열에 primary key를 설정해야 하는데 이러면 에러입니다.
primary key는 테이블을 만들 때 1번만 설정할 수 있습니다.
id varchar2(10) primary key,
num number(5) primary key
==>위와 같은 형태는 에러
==>만약에 id와 num을 합쳐서 primary key를 만들고자 하면 이 때는 모든 열을 정의하고 마지막에 primary key(id, num)의 형태로 설정해야 합니다.
11.제약조건 변경
1)제약조건 추가
alter table 테이블이름
add [constraint 제약조건이름]
제약조건종류(열이름);
3)제약조건 수정
alter table 테이블이름
modify 열이름 [constraint 제약조건이름] 제약조건 종류;
=>not null을 추가하는 경우는 add가 modify입니다.
null이 가능한 상태에서 null이 불가능한 것으로 수정하는 것으로 간주합니다.
3).제약조건 삭제
alter table 테이블이름
drop constraint 제약조건이름;
12.제약조건의 비활성화 및 활성화
1)비활성화
alter table 테이블이름
disable constraint 제약조건이름;
2)활성화
alter table 테이블이름
enable constraint 제약조건이름;
===>테스트 할 때 많이 이용
회원 테이블
아이디는 필수
비밀번호는 필수
닉네임은 필수
=>샘플 데이터를 삽입해서 아이디 중복검사를 테스트
중복 검사해야 하는데 비밀번호와 닉네임은 입력해야 하는 불편적이 상황이 있을 경우 필수 조건을 비활성화 하고 중복아이디를 입력하여 테스트 진행한다.
**테이블을 제외한 개체
1. View
=>자주 사용하는 select구문을 하나의 이름으로 만들어두고 마치 테이블인 것 처럼 사용하는 가상의 테이블
1)사용이유
=>속도 때문 :select구문은 요청이 오면 그 때 구분을 확인해서 실행
뷰와 프로시저는 처음 한 번 수행하고 나면 메모리에 저장된 상태로 존재해서 다음 호출부터는 구문확인을 하지 않고 메모리에 적재된 내용을 바로 수행합니다.
=>보안:각 사용자에게 모든 데이터를 넘겨주지 않고 필요한 데이터만 별도의 이름으로 사용하게 해서 실제 구조를 알 수 없도록 할 수 있습니다.
2)View는 삽입 ,삭제 ,갱신에 제약이 있는 것이지 못하는게 아닙니다.
View에 데이터를 삽입하면 View를 만들 때 사용한 원본 데이블에 데이터가 삽입됩니다.
3)생성 구문
create [or replace] view 뷰이름
as
select 구문
[with check option]
[with read only]
==>or replace :뷰가 존재하면 수정
뷰는 alter view 명령이 없어서 구조변경이 안됩니다.
=>with check option은 select 구문에서 조회가 가능한 경우에만 삽입,삭제 ,갱신을 하도록 설정
with read only는 읽기 전용
두개 같이 쓰도 되지만 사용하지 않고 같이 있으면 안된다.
4)삭제
drop view 뷰이름:
5).실습
=>dept테이블의 모든 내용을 복사해서 tempdept테이블을 생성
create table tempdept
as
select *
from dept;
=>어떤 유저가 tempdept테이블에서 deptno와 dname 만 필요하다면 테이블을 주는 것이 아니라 뷰를 만들어서 제공
CREATE OR REPLACE VIEW deptView
AS
SELECT deptno,dname
FROM TEMPDEPT;
=>deptview테이블인 것 처럼 사용 가능
SELECT * FROM deptView;
deptView는 존재하지 않는 테이블이지만 사용은 테이블처럼이다.
=>별도의 옵션 없이 뷰를 생성했기 때문에 뷰에 데이터 삽입,삭제 ,갱신이 가능
뷰에 작업이 발생하는 것이 아니고 원본 테이블에 작업을 수행

INSERT INTO deptView(deptno, dname)
values(11,'마케팅');

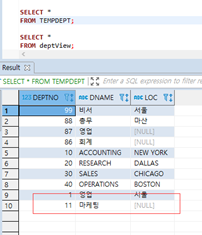
tempdept에 들어가서 deptView에 들어갔다.
=>원본 테이블에 데이터가 추가된 것이 확인 됨
=>뷰를 만들때 with read only옵션을 추가했으면 데이터 삽입에서 에러 발생
6)복합 뷰
=>2개 이상의 테이블을 join해서 만든 뷰
=>복합 뷰는 with read only옵션이 없어도 삽입 ,삭제 ,갱신 작업에 제약이 있습니다.
뷰는 alter가 안된다.
ALTER VIEW deptView
AS
SELECT deptno,dname
FROM TEMPDEPT;
--SQL Error [922] [42000]: ORA-00922: missing or invalid option
--OR REPLACE ALTER가 안되서 이런 방식으로 한다.
CREATE OR REPLACE VIEW deptView
AS
SELECT deptno,dname
FROM TEMPDEPT;
--뷰 삭제
DROP VIEW deptView;
오라클은 inlineview등으로 페이지 처리 해야 한다.
2. inline view
1). 오라클의 rownum
==>오라클이 부여하는 일련번호
==>select 구문을 수행해서 결과를 리턴할 때 보여지는 일련번호입니다.
==>이 번호를 FROM절에서 WHERE로 조건 비교를 할 때 임시로 부여된 후 WHERE 절에 조건을 만족하면 확정되는 형태로 번호가 설정됩니다.

==>어떤 행을 가져왔는데 이 행이 WHERE 절의 조건을 만족하면 ROWNUM 은 1증가해서 설정되지만 WHERE절의 조건을 만족하지 못하면 다음 행을 가져 올 떄 ROWNUM은 이전과 같은 값으로 설정됩니다.
STUDENT
|
NAME |
SCORE |
|
김 |
80 |
|
이 |
90 |
|
박 |
87 |
|
최 |
91 |
SELECT *
FROM STUDENT;
|
ROWNUM |
NAME |
SCORE |
|
1 |
김 |
80 |
|
2 |
이 |
90 |
|
3 |
박 |
87 |
|
4 |
최 |
91 |
우리 눈에는 안보이지만 ROWNUM이 있다.
데이터베이슨 ROWNUM이 있다.
SELECT ROWNUM,NAME,SCORE
FROM STUDENT;
|
ROWNUM |
NAME |
SCORE |
|
1 |
김 |
80 |
|
2 |
이 |
90 |
|
3 |
박 |
87 |
|
4 |
최 |
91 |
우리 눈에 보이지 않는 오라클이 만든 컬럼이다.
번호가 만들어진 원리가 생각보다 쉽지 않다.
SELECT ROWNUM,NAME,SCORE
FROM STUDENT;
출력을 할려고 할때 STUDENT하고 WHERE 를 확인한다. WHERE 조건이 없어서 통과한다.
|
1 |
김 |
80 |
WHERE 조건 확인
|
2 |
이 |
90 |
WHERE 조건 확인하고
|
3(MAX) |
박 |
87 |
WHERE 조건확인하고
|
4 |
최 |
91 |
SELECT ROWNUM,NAME,SCORE
FROM STUDENT
WHERE score >= 90
|
ROWNUM |
NAME |
SCORE |
|
1 |
김 |
80 |
|
2 |
이 |
90 |
|
3 |
박 |
87 |
|
4 |
최 |
91 |
1번 확인하고 80이여서 출력은 안한다.
데이터가 없어서 다시 1번으로 한다.
|
1 |
이 |
90 |
2번으로 부터 확인한다.
87이 90보다 작아서 못 연다.
번호는 테이블 확인한다.
|
2 |
최 |
91 |
출력결과
|
1 |
김 |
80 |
|
2 |
최 |
91 |
오라클에서 페이지를 하려고 한다.
페이지 처리시 rownum과 inline view가 필요하다.
select ROWNUM,name,score
from student
where rownum <= 2;
|
1 |
김 |
80 |
|
2 |
이 |
90 |
3 번데이터 확인하고 못들어간다.
그리고 3번으로 student테이블의 4번과 비교한다.
select ROWNUM,name,score
from student
where rownum > 2;
데이터가 안나온다.
페이지 처리시 sort한다음 처리
select rownum,name,score
from student
wehre rownum <= 2
order by score desc; 점수 내림차순
|
rownum |
NAME |
SCORE |
|
1 |
이 |
90 |
|
2 |
김 |
80 |
rownum <= 2 먼저하고 order by 한다.
행번호 설정되고 정렬된다.
inline view
=>from 절에 사용하는 select구문
select rownum,name,score
from (select * from student order by score desc)
where rownum <= 2
1. select * from student order by score desc
점수 정렬한다.
|
NAME |
SCORE |
|
최 |
91 |
|
이 |
90 |
|
박 |
87 |
|
김 |
80 |
2. rownum
|
rownum |
NAME |
SCORE |
|
1 |
최 |
91 |
|
2 |
이 |
90 |
rownum <= 할수 있지만 >것은 안된다.
>2를 가져오려면 번호를 한다.
select rownum,name,score
from ( select rownum rnum, name,score
from (select * from student order by score desc))
where rnum >2;
항상 괄호 안에 있는 것이 먼저이다.
1.select * from student order by score desc;
|
NAME |
SCORE |
|
최 |
91 |
|
이 |
90 |
|
박 |
87 |
|
김 |
80 |
2.
select rownum rnum, name,score
from (select * from student order by score desc)
where 이 없어서 순서데로 한다.
|
rnum |
NAME |
SCORE |
|
1 |
최 |
91 |
|
2 |
이 |
90 |
|
3 |
박 |
87 |
|
4 |
김 |
80 |
rownum은 where절을 통과하면 되지만 rnum은 행번호가 아니라 컬럼의 값이다.
다음 2개를 뽑아올 수 있는 것이다.
rnum >= 1 and rnum <= 10
rnum >= 11 and rnum <= 20
mysql 은 limit사용한다.
mongoDB limit 10이다.
oracle은 inline view를 이용해야 한다.
재일 안쪽에는 무조건 sort하고 바깥에서는 rownum부여하고 밖의 where절에서 이거 가지고 잘라내면 된다.
3)오라클에서 데이터를 page단위 또는 top-N을 구현할 떄 사용
4)구조
select 필요한 컬럼 이름 나열
from (select rownum 별명, 컬럼이름 나열
from (select 필요한 컬럼이름
from 테이블이름 order by 원하는 컬럼으로 정렬))
where 별명을 가지고 페이지 단위 또는 더보기 작성
5).실습
=>emp테이블에서 입사일(hiredate)이 가장 늦은 사원 5명의 이름(ename)과 입사일을 가져오기
SELECT *
FROM EMP e
ORDER BY HIREDATE DESC;
--ADAMS,SCOTT,MILLER,FORD,JAMES
SELECT ENAME, HIREDATE
FROM (SELECT ROWNUM RNUM, ENAME, HIREDATE
FROM (SELECT *
FROM EMP e
ORDER BY HIREDATE DESC))
WHERE RNUM >= 1 AND RNUM <= 5;
top-n paging
inline –view
**sequence
=>오라클에 존재하는 일련번호 생성을 위한 개체
=>기본키를 생성하는 것이 애매한 경우 시퀀스를 이용해서 생성하는 경우가 있음
1.생성
create sequence 시퀀스이름
[start with 시작번호]
[increment by 간격]
[maxvalue 최대값 | nomaxvalue]
[minvalue 최소값 | nominvalue]
[cycle | nocycle]
[cache | nocache]
start with는 생략하면 관리자 계정에서는 1인데 나머지 계정은 1이 아닐 수 있습니다.
increment by 는 생략하면 1
maxvalue는 생략하면 10의 27승
minvalue는 생략하면 1
cycle은 마지막 숫자에 도달하면 맨 처음 숫자로 이동할 지 여부인 nocycle을 지정하면 마지막 숫자 다음에서 오류가 발생하면 cycle을 설정하면 primary key로 사용할 수 없습니다.
기본은 nocycle
cache는 시퀀스의 값을 메모리에서 관리할 것인지의 여부로 기본은 nocache
실제적으로 start withi와 increment by만 많이 사용하고 다른 것은 잘 사용하지 않는다.
2.값사용
시퀀스.nextval:다음 시퀀스 값
시퀀스.currval:현재 시퀀스 값- nextval은 한 번이라도 호출 한 후에 사용해야 합니다.
3. 시퀀스 수정
alter sequence 시퀀스이름
옵션 다시 설정
=>start with는 수정할 수 없습니다.
4.시퀀스 삭제
drop sequence 시퀀스 이름
5.실습
=>1 부터 1씩 증가하는 시퀀스 생성
create sequence boardseq
start with 1;
=>시퀀스 다음 값 확인
select boardseq.nextval
from dual;
=>현재 시퀀스 확인
select boardseq.currval
from dual;
=>시퀀스 삭제
drop sequence boardseq;
select boardseq.currval
from dual;->이것 먼저 수행시
--SQL Error [8002] [72000]: ORA-08002: sequence BOARDSEQ.CURRVAL is not yet defined in this session
순서는 boardseq.nextval-> boardseq.currval이다.
6.데이터베이스 연동 프로그래밍에서는 sequence대신에 가장 큰 값을 찾아서 +1을 하는 경우도 있습니다.
**index
=>데이터를 빠르게 조회하기 위한 포인터
=>책에서 특정 쳅터를 빠르게 보기 위해서 꽂아놓는 책갈피와 유사
=>데이타베이스 종류에 따라 구현하는 방법은 여러 가지
=>오라클이 사용하는 방식은 b(balance)*트리
=>인덱스를 사용하면 빠르게 조회할 수 있다는 장점이 있지만 인덱스 만큼 메모리 할당을 더 해야 하고 삽입이나 삭제 및 갱신 작업이 발생하면 인덱스 조정으로 인한 속도 저하가 발생할 수 있습니다.
데이터가 연속적인 단위
배열 : 크기가 고정
LIST : 크기가 가변
Linked List :데이터와 다음데이터를 가리키는 포인터를 갖는 자료구조
List ->배열
ArrayList
|
10 |
30 |
40 |
배열은 못 지운다. 크기가 변경이 안된다 데이터가 연속적으로 저장 되여야 한다.
중간에 30을 지우면 배열이 안된다.
|
|
|
|
배열하고 비슷한데 arrayList는 비여있다.grow ,shirink한다.
ArrayList 연속적으로 사용하고 땡기고 밀어여고 하는 구조여서 중간에 데이터가 삭제되면 문제가 생겨서 Linked List이다.
특징알고 장단점은 알아야 한다.
arrayList ->stack lifo
->queue 자판기 fifo 문류 먼저 들어간것이 먼저 들어간다.
->deque 양쪽으로 들어오고 나가는 것 지도 위으로도 가고 아래로도 간다.
Linked List ->
|
data |
다음 데이터 위치 |
10,40,30
|
head |
다음 데이터 위치 3000번지 |
3000번지
|
10 |
700번지 |
700번지
|
40 |
290번지 |
290번지
|
30 |
|
읽어오는 속도가 늦다. head부터 해서 다음 위치 가르키는 것
삽입과 삭제가 강하다.
ArrayList
|
10 |
40 |
30 |
40을 상제하면
|
10 |
30 |
가끔식 삭제 하면 괜찮은데 많이 사용하면 문제가 많다.
Linked List
40지워지면
|
10 |
700번지 |
700번지는 연결이 안되였다. 포인터가 삭제된다.복구 할 것을 위하여
파일 삭제하면 삭제되는 것이 아니라 휴지통으로 간다.
포인터들만 지운다.
10g 1개
100m 50개 5 g 가 지우면
개수가 많는게 오래 걸린다. 진짜로 지우는 것이 아니라 포인터 지우는데 오래 걸린다.
한쪽으로 연결하면 끊어지면 연결이 안되서
doubleLinkedList
point가 2개 있다.앞에 뒤에 끊어져도 반대편에 있다.
python list 는 doubleLinkedList이다. reverse기능
|
|
|
|
포인트 앞뒤에 있다.
python의 lib는 대다수 c나 java이다.
트리는 부모자식의 관계가 있다.
파일시스템 ->트리
부모는 첫번째 자식 밖에 못 가르킨다.
위에서 아래로
balance
b트리:포인터의 1/2이상 채워진 트리
b*트리: 포인터의 2/3이상 채워진 트리
100,300,70,40

문제가 클 경우 출발점 70으로 되여있다. 70을삭제시 트리를 다시 만들어야 한다.index조정 작업 필요

60추가시 쪼개야 한다. 분할 작업 진행 필요
index는 빨리 조회되지만 삽입,삭제,갱신 등 작업이 늦을 수있다.
mysql은 설정을 한다.
읽기만하면 index구조
삽입,삭제,갱신 index사용하면 늦어지고 버벅거린다.
적절한 자료구조 선택해야 한다.
python 는 배열이나 arraylist가 없다.
1. 인덱스 생성
create index 인덱스이름
on 테이블이름(컬럼이름);
2. 인덱스 제거
drop index 인덱스이름;
=>blob나 clob는 인덱스 설정을 할 수 없습니다.(데이터가 크서 안한다.)
3. 인덱스를 생성해야 하는 경우
=>행의 개수가 너무 많을 때
=>특정 열이 where절에서 자주 사용될 때
=>null이 많은 열
=>join이 자주 사용되는 열
=>검색할 때 전체 데이터의 2~4%정도 검색할 때
4. 인덱스를 생성하면 안되는 경우
=>행의 개수가 너무 적을 때
=>삽입,삭제,갱신 작업이 빈번히 발생할 때
=>검색 결과가 전체 데이터의 10%이상 일 때
5. primary key나 unique속성을 설정하면 자동으로 인덱스가 생성됩니다.
**동의어(synonym)
=>데이터베이스 개체에 별명을 부여하는 것
1.생성
create synonym 별명
for 원래이름
2.삭제
drop sysnonym 별명;
=>데이터베이스를 프로그래밍 언어와 연동할 때 별명을 사용하면 유지보수가 편합니다.
emp - 데이터베이스
python 개발자 한테 테이블 이름 으로 개발한다. emp로
emp는 함부로 못 바꾼다.
emp바꿀시 화면에서도 다 바꿔야 한다
create synonym e
for emp;
구조가 바꾸지 않았더라면 이름 바꾸는데 편해진다.
유지보수 편하게 하려면 항상 별명을 하는게 좋다.
**stored procesure
=>자주 사용하는 sql구문을 프로그래밍 언어의 함수처러 하나의 이름으로 만들어 두고 그 이름을 이용해서 sql구문을 실행하는 것
1. 장점
=>sql구문을 실행하는 것 보다는 실행 속도가 빠르고 보안이 유지
2. 생성
create [or replace] procedure 프로시저이름(매개변수이름 [mode] 자료형 , ...)
is
지역변수
begin
수행할 sql 구문
end;
/
=>dbeaver에서는 마지막 슬래시를 제외해야 합니다.
=> or replace는 있는 경우 수정할 때 사용
=> mode는 in,out 그리고 생략도 가능
in이면 입력받는 매개변수이고 out이면 출력을 위한 매개변수
=>자료형을 작성할 때는 직접 자료형을 작성해도 되지만 테이블이름.열이름%TYPE으로 다른 열의 자료형을 이용해도 됩니다.
=>주의할 점은 sql을 작성할 때도 마지막에 ;을 해주어야 합니다.
3. 프로시저 호출
1) sqlplus : execute프로시저이름(매개변수);
2) dbeaver, sqldeveloper:
begin
프로시저이름(매개변수);
end;
4. 프로시저를 만드는 문법은 관계형 데이터베이스 종류마다 다름
오라클의 프로시저 만드는 문법을 pl/sql이라고 합니다.
pl/sql ->오라클의 프로시저 사용가능 하는 것
5. 프로시저 삭제
drop procedure 프로시저 이름;
6. 실습
=>deptno,dname,loc를 입력받아서 dept테이블에 데이터를 삽입하는 프로시저를 만들고 호출
1)프로시저 생성
create or replace procedure insert_dept(
vdeptno dept.deptno%type, ,--여기 변수명은 DEPTNO이면 안된다.입력시 문제 생긴다. vdeptno
vdname dept.dname%type,
vloc dept.loc%type)
is
begin
insert into dept(deptno,dname,loc)
VALUES (vdeptno,vdname,vloc);
END;
/(DBeaver가 아닌 경우는 /까지)
2.프로시저 실행
BEGIN insert_dept(22,'총무','수원');END;
3.확인 하는 것은
SELECT *
FROM dept ;
**트리거
=>테이블에 데이터를 삽입,삭제 ,갱신할 때 작업 전후에 다른 작업을 수행하도록 하는 개체
=>작업 전에 수행하는 동작은 유효성을 검사해서 유효성 검사에 실패하면 작업을 수행하지 않기 위해서 이고 작업 후에 수행하는 동작은 작업을 하고 다른 작업을 연쇄적으로 실행하기 위해서 입니다.
=>프로그래밍에서는 이와 유사한 개념으로 필터와 AOP가 있습니다.
데이터 작업을 수행하고 로그를 기록해야 하는 경우
실제 수행해야 할 작업을 비지니스 로직이라고 하고 로그를 기록하는 것처럼 실제 작업은 아닌데 별도로 해야 하는 작업을 공통 관심 사항이라고 합니다.
비지니스 로직의 수행이 끝나고 공통 관심 사항을 실행하도록 일반 코드로 작성하게 되면
-비지니스 로직 수행
-공통 관심 사항 수행
데이터베이스에서는 트리거를 이용해서 비지니스로직을 수행하면 공통 관심 사항이 자동으로 수행되록 해서 비지니스 로직을 담당하는 개발자는 비지니스 로직 개발에만 집중하도록 합니다.
업무 -> 관리
순차적으로 작성 할 경우 업무를 하면 관리가 보인다.
업무를 담당할 경우에는 업무만 관련된 것만 만들고
관리하는 분은 업무와 관리를 합치는 것을 만든다.자동으로 붙인다.이것을 aop라고 한다.
카드업무 -> 관리
카드업무 만들고
관리 만들고
관리 할 경우 카드업무 수행해야 작업이 가능할 현상이 생긴다.
이럴 경우 문제가 생겨서
카드업무하고 관리를 따로 따로 하고 후에 설정을 한다.
유지보수 차원에서 편하다.
sqllite에서는 외래키를 설정하고 on delete cascade옵션을 설정해도 부모테이블에서 데이터가 삭제될 때 자식 테이블에서 데이터가 연쇄적으로 삭제되지를 않습니다.
이런 경우에도 트리거를 이용하면 부모 테이블에서 데이터가 삭제될 때 자식 테이블에서 자동으로 삭제되도록 구현할 수 있습니다.
1.생성
create or replace trigger 트리거이름
[before| after] [insert|update|delete] on 테이블이름
[for each row]
[when 조건]
begin
수행할 내용
end;
=>for each row는 여러 개의 행에 update,delete,insert가 발생할 때 반드시 트리거를 여러 번 수행하고자 할 때 사용하는 옵션으로 생략하면 여러 개의 행에 작업이 발생해도 트리거는 한 번만 동작
=>when에 조건을 설정해서 조건에 맞는 경우에만 수행하도록 할 수 있고 수행하지 않도록 할 수도 있습니다.
:old.컬럼이름,:new.컬럼이름 을 사용할 수 있는데 앞에 old가 붙으면 이전 데이터인데 delete는 삭제되는 데이터의 값이고 update에서 변경되기 전의 값입니다.
insert에서는 old를 사용 못합
new는 새로 대입되는 값으로 update와 insert에서 사용할 수 있습니다.
=>수행할 내용 자리에
raise_application_error(에러코드번호,메시지);
을 입력하면 작업을 수행하지 않고 에러 메시지를 출력합니다.
when 정기정검시간인지 확인
raise_application_error(에러코드번호,메시지);
포인터가 0보다 작으면 여기에 에러코드한다.
관리자가 되면 트리거를 사용
로그인 마지막 날짜 업데이트 등 트리거 가지고 한다.
작업을 못하게 하는 것 등은 트리거 가지고 한다.