본 내용은 fastcampus 딥러닝/인공지능 올인원 패키지 online을 정리한 것이다.
WARNING:
tensorflow:Layer mymodel_2 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because its dtype defaults to floatx. If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2. To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.

해결방법:
X_train= X_train[..., tf.newaxis].astype(np.float32)
X_test= X_test[..., tf.newaxis].astype(np.float32)
Residual Unit 개발 주의 할점
Pre-Active
batch normalization ->relu -> conv
채널 개수 같아야 한다.
학습 할때는 training = True
test할 떄는 training = False
DenseNet 개발 주의 할점
concatenate
concatenate([input, batch normalization ->relu -> conv ])
growth rate
학습 할때는 training = True
test할 떄는 training = False
순차 데이터의 이해
순서가 의미가 있으며, 순서가 달라질 경우 의미가 손상되는 데이터를 순차 데이터라고 한다.
Resampling : 일정한 간격으로 다시 samping해주면
심층 신경망과 순차 데이터
다중 입력, 단일 출력
다중 입력, 다중 출력
단일 입력, 다중 출력
Memory System => 그 전의 내용을 기억해야 한다.
Memoryless System 무기억 시스템 :
shallow neural network 이전 입력에 영향을 받지 않는다. 출력에도 영향을 받지 않는다.
vanilla Recurrent Network: 기본적인 순환 신경망
얕은 신경망 구조에 '순환'이 추가된 것으로
이전의 모든 입력에 영향을 받는다.
기울기 소실 문제 때문에 잘 사용하지 않는다.
multi-layer RNN: 다중 계층 순환 신경망
권장되는 구조는 아니다. 학습이 잘 되지 않는다.
LSTM LONG Short-Term Memory
필요한 시간 만큼 기억한다.
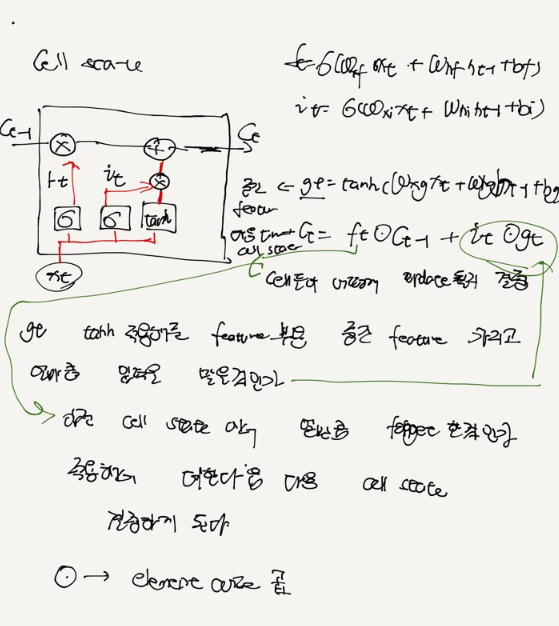
Cell State가 추가 됬다. -> 오래동안 기억을 잘 하기 위해서 덧셈
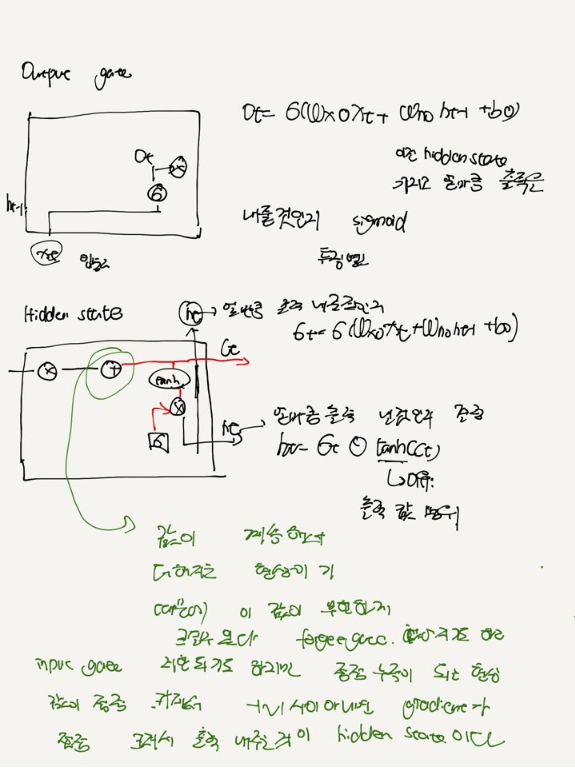
Hidden State -> 출력
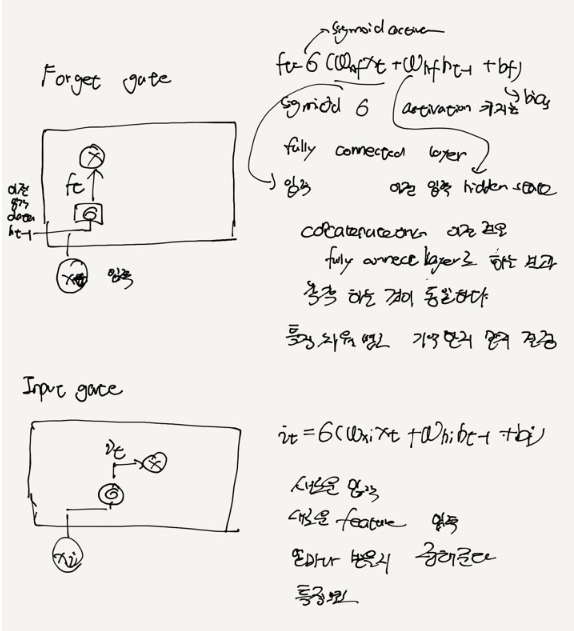
Forget Gate -> sigmoid로 얼만큼 잊을 지 결정
0 이 곱해진것은 잊어버리고 1곱한것은 남는다.
Input Gate -> sigmoid 새롭게 추출한 특징을 얼만큼 사용할 지 결정
얼마큼 기억할 것인지
Output Gate -> sigmoid Cell 로부터 출력을 얼마나 내보낼지 결정
GRU Gated Recurrent Unit
LSTM을 간소화한 버전
Cell state가 없고, hidden state만 존재
Forget Gate와 Input Gate합쳐졌다. -> Forget Gate를 사용
잊은것을 채워주는 기억을 어떻게 할것인지
Reset Gate sigmoid 곱해진다. 새로운 Feature를 뽑기전에 기억을 얼마나 죽여줄지
순환 신경망은 기본 역전파 학습법으로는 학습할 수없다.
순차 데이터셋의 구조
순차 데이터 -> 순환 신경망
순방향 추론 : 입력을 여러번 해주면 마지막 출력이 나온다.
시간 펼침 역전파 Back Propagation Through Time
사이의 미분을 다 알아야 한다.
시간적으로 펼쳐진 변수들은 동일한 변수라는 점에 유의해야 한다.
All -Zero 입력
LSTM LONG Short-Term Memory
Cell state, hidden state, forget gate, input gate, output gate , hidden state
forget gate input gate Cell state output gate hidden state
forget gate 기억을 '잊고자 하는 정도'를 나타낸다.
simoid activation 이므로 값의 범위는 0~1이다.
특징별로 기억할지 말지를 결정할 수 있다.
input gate : 새로운 입력을 받고자 하는 정도를 나타낸다. sigmoid activation 이므로 값의 범위는 0~ 1이다.
특징은 여러 차원으로 되어있으므로 , 특징별로 받아들일지 말지를 결정할 수 있다.
Cell state '기억'을 총괄하는 메모리 역할을한다. 여러 차원으로 되어있어 , 각차원은 특정 정보를 기억한다.
hadamard연산자의 특성으로 인해 , 특징 별로 기억하고 , 잊고 ,새로이 정보를 받을 수 있다.
output gate 는 cell state중 어떤 특징을 출력할지 결정하는 역할을 한다. sigmoid
hidden state Cell state에 tanh activation을 적용한 후, output gate로 선별하여 출력한다.
tanh -1~1로 bound되게 하기 위함이다.
GRU수식
Reset gate forget gate hidden state
Reset gate : hidden state중 어떤 특징을 reset할지 결정한다.
forget처럼 바로 잊어버리는것이 아니고
기억을 해야 하지만 큰 맥락에서는 feature를 뽑는 방해가 되는것이 있을 수 있다.
forget gate: 이전 time 의 hidden state를 잊어버린다 . 1- 에서 빼준다.
hidden state: 이전 reset gate,forget gate를 모두 적용하여 hidden state를 계산한다.
제어가 된만큼 넘어오고 입력과 이전 time의 reset gate를 정의해서 reset gate에의해서전에것
잊어버리고 다시 한다.
계속 누적해서가 아니고 이전의 잊어버린 만큼만 하기 때문에 tanh가 필요없다.
'교육동영상 > 01. 딥러닝인공지능' 카테고리의 다른 글
| 11 . 순환 신경망 (0) | 2020.12.07 |
|---|---|
| 09. 딥러닝 기초-2 (0) | 2020.12.04 |
| 08. 딥러닝 기초 (0) | 2020.12.02 |
| 07. 이미지 분석 pytorch (0) | 2020.12.01 |
| 06. 이미지 분석 tensorflow 2.0 (0) | 2020.11.25 |