YOLO9000:Better, Faster, Stronger
Abstract
개선된 모델 YOLOv2는 PASCAL VOC and COCO 같은 standard detection tasks 에 대한 state-of-the-art 이다.
새롭고 다양한 규모의 학습 방법을 사용하면 동일한 Yolov2 모델을 다양한 sizes로 실행할 수 있으므로 속도와 정확도 사이에서 쉽게 trade-off 할 수 있따.
VOC 2007에서 67 FPS이고 76.8 mAP, 40 FPS에서 78.6 mAP를 획득하는 ResNet및 SSD를 사용하는 Faster RCNN과 함께 state-of-the-art methods 을 능가하는 동시에 훨씬 더 빠르다.
jointly train on object detection and classification ⇒ YOLO9000 을 COCO detection dataset과 ImageNet Classification dataset을 이용해 동시에 학습시킨다. 000개 이상의 서로 다른 개체 범주에 대한 탐지를 예측가능하며 여전히 실시간으로 실행된다.
1. Introduction
General purpose object detection 빠르고 정확하며 다양한 물체를 인식할 수 있어야 한다. fast and accurate을 증가 하였지만 여전히 a small set of objects제한이 있다.
현재의 object detection datasest는 classification 및 tagging 지정과 같은 other tasks을 위한 dataset에 비해 제한적이다.
hierarchical view of object classification
joint training algorithm, classification images to increase its vocabulary and robustness 활용하여 objects를 정확하게 지역한하는 방법을 학습
YOLO9000 a real-time object detector 9000 종에 대해서 할 수 있따.
- YOLOv2, a state-of-the-art, real-time detector
- our dataset combination method and joint training algorithm to train a model on more than 9000 classes from ImageNet as well as detection data from COCO
http://pjreddie.com/yolo9000/.
2. Better
Fast R-CNN과 비교한 YOLO의 Error analysis 은 Yolo 가 상단한 localization error 를 발생시킨다.
YOLO has relatively low recall compared to region proposal-based methods
따라서 우리는 분류 정확도를 유지하면서 recall과 localization를 개선하는 데 주로 중점을 둡니다.
larger, deeper networks 경향이 있다. 더 좋은 성능은 더 큰 network를 훈련하거나 여러 model을 함께 앙상블 하는데 달려있다. 그러나 Yolov2를 사용하면 여전히 빠른 더 정확한 detector가 필요한다. network를 확장하는 대신 network를 단순화한 다음 representation을 더 쉽게 배울 수 있도록 한다.
다양한 아이디어를 사용

Batch Normalization
다른 형태의 regularization에 대한 필요성을 제거하면서 수렴을 크게 향상시킨다. 모든 convolution layer에 batch normalization을 추가하면 mAP를 2% 향상시켰다. 모델을 정규화 하는데도 도움이 되고 overfitting 없이 dropout 를 제거할 수 있따.
High Resolution Classifier
YOLO classifier network를 224x224에 학습한 다음 448x448 의 해상도에서 detection network를 학습하였다. object detection을 학습하면서 동시에 새로운 input resolution 에 적용해야 하는 것을 의미한다.
YOLOv2 classifier network ImageNet full 448 × 448 resolution 10 epoch → 이는 network 가 더 높은 resolution input에서 더 잘 작동하도록 filter를 조정할 시간을 준다. 그다음에 fine tune the resulting network on detection. mAP를 4% 향상시켰다.
Convolutional With Anchor Boxes
Yolo는 convolutional feature extractor 위에 fully -connected layer를 통해 직접 bounding box 좌료를 예측, 우리는 Yolo에서 fully-connected layer를 제거하고 bounding box 예측을 위해 anchor box를 사용한다. pooling layer를 제거하고 network의 convolution layer의 출력을 더 높은 해상도로 만든다. 448 x 448 대신 416개의 input image에서 작동하도록 network에서 축소한다.
a single center cell 을 갖는 feature map을 위해 홀 수 개의 위치를 갖는다 . 이는 큰 물체는 이미지의 중앙을 차지하는 경향이 있으므로 모두 근처에 있는 4개 위치 대신 이런한 물체를 예측하기 위해 중앙에 단일 위치를 갖는 것이 좋다. YOLO의 convolutional layer는 32배 만큼 이미지를 downsampling하므로 416 input image를 사용하여 13x13 출력 feature map을 얻는다. ⇒ 조금 더 작은 물체
anchor box로 이동할 때 class prediction mechanism 을 spatial location 에서 분리하고 대신 모든 anchor box에 대한 class와 객체성을 예측한다. Yolo에 이어 objectness prediction 은 여전히 ground truth의 IOU를 예측하고 제안된 box 및 class predictions은 object가 있는 경우 해당 class의 conditional probablility 을 예측한다.
Anchor box를 사용하면 정확도가 약감 감소한다. Yolo는 이미지당 98(772)개의 box만 예측하지만 anchor box는 천 개 이상을 예측한다. anchor boxes가 없으면 중간 모델은 81%의 recall과 함께 69.5mAP를 얻는다. mAP가 감소하더라도 recall의 증가는 우리 모델이 개선할 여지가 더 많다는 것을 의미한다. ⇒ recall이 좋아졌다는 의미는 물체를 더 잘 찾아난다는 것이기 때문에 성능만 조금 더 개선하면 improve 한다는 여지가 있다.
Dimension Clusters
box dimension는 수동적으로 결정하였따. ⇒ k-Means Clustering 방법으로 개선
Euclidean distance와 함께 standard k-means clustering을 사용하는 경우 큰 box는 작은 box보다 더 많은 오류를 생성한다. 그러나 원하는 것은 box의 크기와 무관한 좋은 IOU scores로 이어지는 사전 순위이다. distance metric
d(box,centroid)=1−IOU(box,centroid)
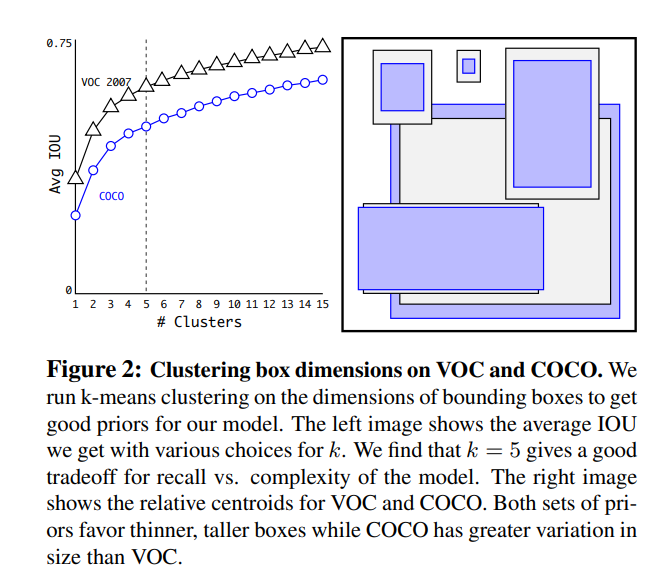
k= 5가 모델의 recall vs. model complexity 에 대해 좋은 tradeoff을 제공한다는 것을 발견하였다.
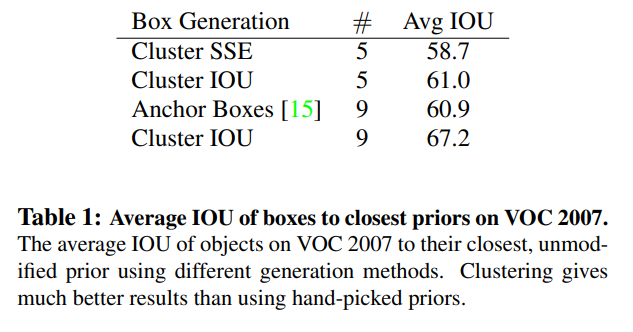
Cluster SSE (Sum of Square Error) 5
anchor box를 9개에서 5개로 줄임,
9개의 Cluster IOU를 사용하면 훨씬 더 높은 IOU를 볼 수 있다. 이것은 bounding box 를 생성하기 위해 k-평균을 사용하면 더 나은 representation으로 model을 시작하고 task을 더 쉽게 학습할 수 있다.
Cluster SSE (Sum of Square Error) 5
anchor box를 9개에서 5개로 줄임,
9개의 Cluster IOU를 사용하면 훨씬 더 높은 IOU를 볼 수 있다. 이것은 bounding box 를 생성하기 위해 k-평균을 사용하면 더 나은 representation으로 model을 시작하고 task을 더 쉽게 학습할 수 있다.
Direct location prediction
anchor box의 문제점 2: model instability 특히 초기 iteration 동안
원인은 : box의 (x,y)위치를 예측하는데서 발생 ,
region proposal networks에서 network는 tx및 ty값을 예측하고 (x,y) center coordinates는 다음과 같이 계산한다.
x=(tx∗wa)−xa
y=(ty∗ha)−ya
이 공식은 제한이 없으므로 bounding box를 예측한 위치에 관계 없이 모든 anchor box가 image의 어느 지점에서나 깥날 수 있다. random 초기화 를 사용하면 model이 합리적인 offset을 예측하기 위해 안정화되는데 오랜 시간이 걸린다.
각 cell에 5개의 bounding box 예측
5 coordinates : tx, ty, tw, th, and to
cell의 image의 left corner (cx,cy)만큼 offset되고 bounding box 이전의 width와 height가 pw, ph 인 경우 예측은 다음과 같다.
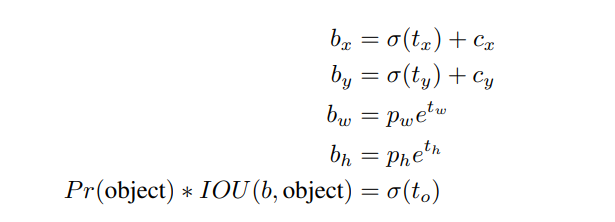
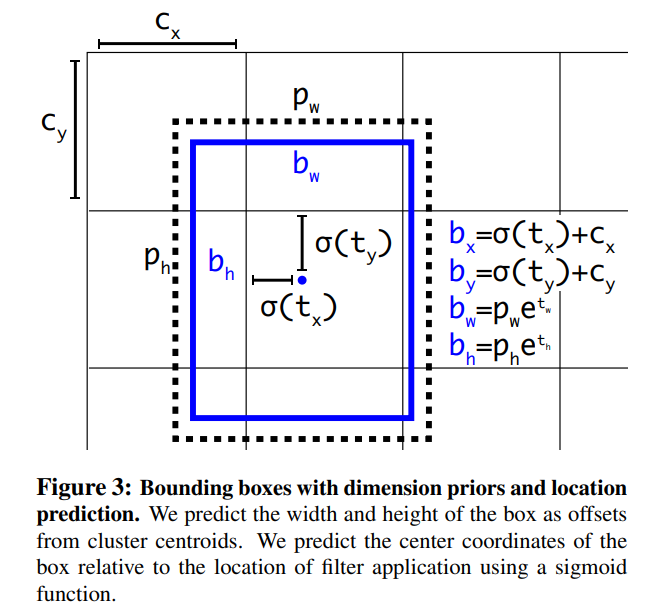
pw,ph: anchor box의 너비 및 높이
bounding box center location을 directly predicting 하는 것과 함께 Dimension clustering을 사용하면 anchor box가 있는 버전보다 5%의 성능 향상된다.
Fine-Grained Features
passthrough layer
26 × 26 × 512 feature map → 13 × 13 × 2048 feature map → 큰물체 작은 물체를 더 잘 뽑아내게
13 × 13 × 2048 feature map 큰 물체를 탐지 못할 수 있다.
1% performance increase
YOLO v2의 13x13 feature map은 큰 물체를 탐지하는데 충분할 수 있으나 작은 물체를 잘 탐지하지 못 할 수 있다. 이를 해결하기 위해 13x13 feature map을 얻기 전의 앞 쪽의 layer에서 26x26 해상도의 feature map을 passthrough layer를 통해 얻는다.
사진 4. fine-grained features
위의 사진 4와 같이 26x26x512 -> 13x13x2048로 분해한 후 기존의 output인 13x13 feature map과 concatenate를 수행한다. 이러한 방법으로 1%의 성능을 향상시켰다.
Multi-scale Training
multi-scale training {320, 352, ..., 608}. 32배 사이즈로 다양하게 학습 ⇒ 같은 network인데 다양한 resolution을 예측할 수 있다.
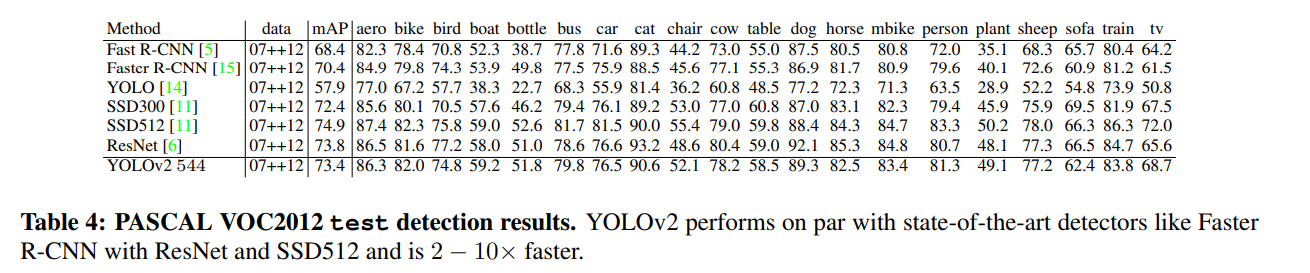
Further Experiments.
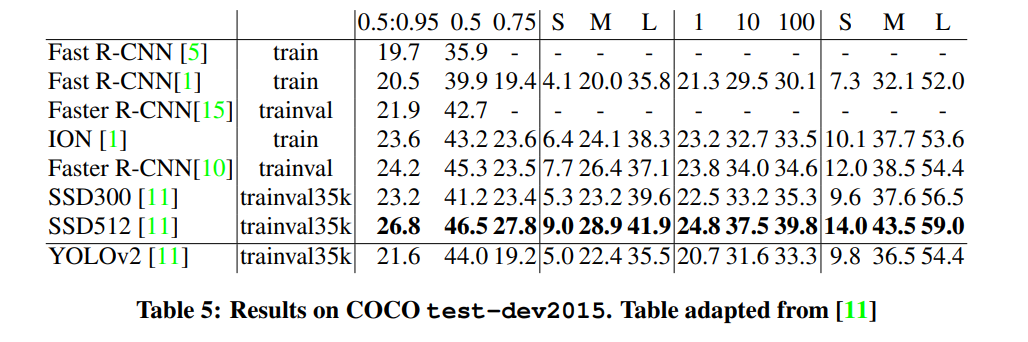
3. Faster
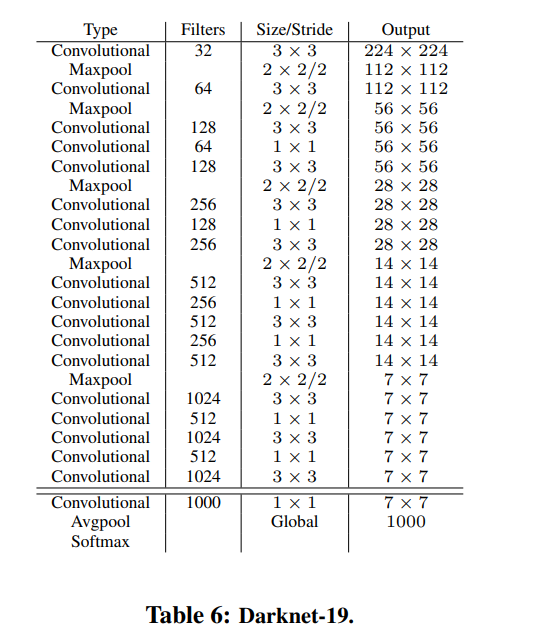
Darknet-19을 backbone network로 사용한다.
VGG-16 대신 Googlenet architecture을 사용 Googlenet architecture 속도가 더 빠르지만 정확도가 조금 낮다.
Darknet-19
VGG와 비슷(3 × 3 filters 사용)
Network in Network (NIN) 작업에 이어 global average pooling 을 사용하여 predictions를 수행하고 1 × 1 filters 를 사용하여 3 × 3 convolutions 사이의 특징 표현을 압축한다. 훈련을 안정화하고 수렴 속도를 높이며 모델을 정규화하기 위해 batch normalization를 사용한다.
19 convolutional layers and 5 maxpooling layers.
Training for classification
ImageNet 1000 class classification dataset 160 epochs
g stochastic gradient descent, learning rate 시작은 0.1,
polynomial rate decay with a power of 4
weight decay of 0.0005
momentum 0.9
standard data augmentation : random crops, rotations, and hue, saturation, and exposure shifts.
224x224 해상도로 학습한 후 448로
fine tuning : 위의 parameter 사용 , 10 epochs , learning rate of 10−3
Training for detection
last convolutional layer을 제거하고 3개의 3 × 3 convolutional layers with 1024 filters each followed by a final 1 × 1 convolutional layer with the number of outputs we need for detection.
4. Stronger
jointly training on classification and detection data.
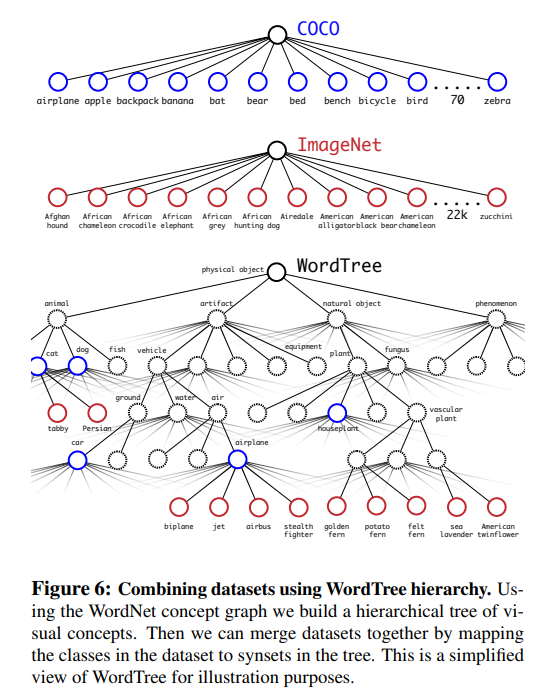
Hierarchical classification : 계층적인 분류를 사용한다.
WordNet는 data구조이고 tree는 아니다.
softmax
Hierarchical classification
조건부 확률고 계산

absolute probability for 특정 node

P r(physical object) = 1.
Dataset combination with WordTree
Joint classification and detection
Yolo9000
output size를 제한하기 위해 5개 대신 3개만 사용
detection backpropagate loss as normal
classification loss only classification loss is backpropagated at or above the corresponding level of the label.
5. Conclusion
real-time detection system YOLOv2 and YOLO9000
Yolov2 state-of-the-art faster , accuracy
YOLO9000 a real-time framework jointly optimizing detection and classification WordTree
hierarchical classification
multi-scale training
논문 출처 : YOLO9000: Better, Faster, Stronger
파파고, 구글 번역을 많이 사용하였다.
'논문 > Object Detection' 카테고리의 다른 글
| YOLOv3: An Incremental Improvement (0) | 2022.07.27 |
|---|---|
| You Only Look Once:Unified, Real-Time Object Detection (0) | 2021.05.04 |