논문 : Going Deeper with Convolutions
NIN
inception
auxiliary classifier
optimal sparse structure :
1. 다른 Receptive filed를 사용
2. convolution 1, 3, 5 (patch-alignment issues)
3. pooling
4. higher layer로 갈수록 3x3 혹은 5x5 convolution의 비율이 증가해야 함을 암시한다.
Abstract

우리는 ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14)에서 classification and detection 새로운 state of the art 달성하는 deep convolutional neural network architecture codenamed Inception 을 제안했다. 이 architecture 의 주요 특징은 network 내부의 computing resources의 활용도 향상이다. 세심하게 crafted design에 의해 , 계산 비용을 유지하면서, network 의 depth and width 을 놀렸다. 품질을 최적화하기 위해, architectural decisions 은 Hebbian 와 multi-scale processing의 직관성에 기반으로 했다. ILSVRC14 에 대한 제출에 사용된 모델은 GoogLeNet으로, 22 layers deep network이며 그 품질은 classification and detection의 context에서 평가된다.
Hebbian principle : 벨을 흔들고 , 강자지 한테 먹는 것을 준다. 오래되면 강아지는 벨 소리를 들으면 저절로 침이 나온다.
1. Introduction


지난 3년 동안, deep learning and convolutional networks [10]의 발전으로 인해, object classification and detection이 크게 향상되었다. 한가지 격려의 뉴스는 이러한 발전의 대부분이 더 powerful hardware, larger datasets and bigger models일 뿐만 아니라 , 주로 새로운 아이디어, 알고리즘 및 향상된 네트워크 아키텍처의 결과라는 것이다. 예를 들어 ILSVRC 2014 competition 의 상위 항목에는 detection purposes으로 동일한 경쟁의 classification dataset세트 외에 데이터 소스가 사용되지 않았다. ILSVRC 2014에 제출한 GoogLeNet 을 실제로 2년 전의 Krizhevsky et al [9]등 winning architecture 보다 12 times fewer parameters사용하면서도 훨씬 더 정확하다. object detection측면에서 가장 큰 이점은 점점 bigger and bigger deep networks의 단순한 적용에서 나온 것이 아니라 Girshick et al [6] 의 R-CNN 알고리즘[6]과 같은 심층 아키텍처와 고전적인 컴퓨터 비전의 시너지에서 나왔다.
또 다른 주목할 만한 요인은 모바일 및 embedded computing의 지속적인 견인으로 알고리즘의 효율성, 특히 성능과 메모리 사용이 증가한다는 것이다. 이 논문에서 제시된 deep architecture 설계로 이어지는 고려사항에는 정확도 수치에 대한 집착보다는 이 요소가 포함되었다는 점이 주목할 만하다. 대부분의 실험에서 추론 시간에 에서 multiply-adds들의 1.5 billion 계산 비용을 유지하도록 설계되었으며, 따라서 모델은 순수한 academic curiosity으로 끝나지 않고 심지어 대규모 데이터셋에서도 합리적인 비용으로 실제 사용할 수 있다.본 논문에서 우리는 컴퓨터 비전을 위한 효율적인 심층 신경망 아키텍처에 초점을 맞출 것이다. 이 architecture의 이름은 Lin et al [12]에서 작성한 Network in network paper이름에서 유래한 것으로 유명한 "“we need to go deeper”" 로 internet meme [1] 과 관련있다. 이름은 Incetpion 이다. => Network in network
Incetpion "we need to go deeper"
우리의 경우 “deep”은 두가지 다른 의미로 사용된다.
1). “Inception module” 의 형태로 새로운 수준의 조직을 도입하고
2). 네트워크 깊이를 증가시킨다는 보다 직접적인 의미에서
일반적으로 사람들은 Arora et al [2]등의 theoretical work에서 영감을 얻고 지침을 얻으면서 Inception model을 [12]의 논리적 장점으로 볼 수 있다. architecture의 이점은 ILSVRC 2014 classification and detection challenges에 대해 실험적으로 증명되었으며, 이는 현재의 state of the art 을 능가한다.
2. Related Work




LeNet-5 를 시작으로, convolutional neural networks (CNN) 은 일반적으로 표준구조를 가지고 있다. 즉, stacked convolutional layers ( 선택적으로 대비 normalization and max-pooling)에 하나 이상의 fully-connected layers가 따라오는 구조 이다. 이러한 기본 구로를 변형한 모델들은 이미지 분류분야에 널리 사용되며, to-data MNIST, CIFAR 및 ImageNet classfication challenge[9, 21] 에서 최고의 성과를 얻었다. ImageNet 과 같은 대용량 데이터에서 최근 trend는 drouput[7] 로 overfitting문제를 해결하면서 레이어 수[12] 와 레이어 사이즈[21,14]를 늘이는 것이다.
max-pooling layers 은 정확한 spatial information을 손실함에서 불구하고 , alexNet[9]와 동일한 convolutional network architecture 가 localization [9, 14], object detection [6, 14, 18, 5] and human pose estimation [19] 에도 성공적으로 사용되였다.
primate visual cortex의 신경과학 모델에서 영감을 받은 Serre et al. [15] multiple scales를 처리하기 위해 크기가 다른 일련의 고정 Gabor filters 를 사용하였다. 우리는 여기서 비슷한 전략을 사용한다. 그러나 [15]의 고정된 2-layer deep mode과 반대로 , Inception architecture 의 필터는 모두 학습된다. 또한 Inception layers은 여러 번 반복되어 GoogLeNet 모델의 경우 22-layer deep model로 이어진다.
Network-in-Network 는 신경망의 표현력을 높이기 위해 Lin et al. [12] 이 제안한 방식이다. 모델에서 network에 1 × 1 convolutional 을 추가되어 그 깊이가 증가한다. 우리는 아키텍처에서 이 접근 방식을 많이 사용한다.
그러나 우리의 환경에서 1 × 1 convolutions 두가지 목적을 가지고 있다.
1) . 가장 중요한 것은 그것들은 주로 계산 병목 현상을 제거하기 위한 차원 축소 모듈로 사용되며
2) . 네트워크의 크기를 제한할 수 있다는 것이다.
bottlenecks: 병목현상 : 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상을 말한다.
이를 통해 성능을 크게 저하시키지 않으면서 , 네트워크의 depth뿐만 아리라 width도 증가시킬 수 있다.
마지막으로 object detection을 위한 state of the art기술은 Girshick et al.[6] Regions with Convolutional Neural Networks (R-CNN) 방법이다. R-CNN은 전제적인 detection problem두가지 하위 문제로 분해한다. category-agnostic 적인 방식으로 object location proposals을 생성하기 위해 color and texture 와 같은 low-level cues 를 활용하고 CNN classifiers를 사용하여 해당 위치에서 객체 범주를 식별한다. 이러한 2단계 접근방식은 state-of-the-art CNNs의 매우 강력한 classification 뿐만아니라 bounding box segmentation 의 정확성을 활용한다.우리는 detection submissions시 similar pipeline을 채택했지만 higher object bounding box recall을 위한 multi-box [5] prediction및 bounding box proposals의 더 나은 분류를 위한 ensemble approaches 같은 두 단계의 개선사항을 탐구했다.
class-agnostic 탐지기는 객체가 어떠한 분류(class)에 속해 있는지에 대해 구분하지 않고 객체만을 검출하여 bounding box로 인식한다.
ensemble
3. Motivation and High Level Considerations








deep neural networks 의 성능을 향상시키는 가장 간단한 방법은 size를 늘리는 것이다. 여기에는 depth , width 증가 두가지가 포함된다.
1). depth의 증가 - the number of network levers (layer )
2). width의 증가 - the number of units at each level
이는 특히 대량의 라벨링된 학습데이터를 사용할 수 있는 경우 고품질 모델을 쉽고 안전하게 교육할 수 있는 방법이다. 하지만 간단한 솔루션에는 두가지 주요 단점이 있다.
1). size가 클 수록 parameters의 수가 많아져 확장된 network가 over-fitting되기 쉬우며, 특히 학습 세트에서 라벨링된 예제의 수가 제한적일 경우 더욱 그러하다. 이는 라벨이 강한 데이터 세트를 얻기 어렵고 비용이 많이 들기 때문에 그림 1에서와 같 ImageNet(1000 클래스 ILSVRC 하위 집합에서도)과 같은 다양한 세분화된 시각적 범주를 전문 인간 평가자가 구별해야 하는 주요 병목 현상이다. => verfitting이 되기 쉽기 때문에 세분화한 라벨이 많이 필요하다.
2). 또 다른 단점은 네트워크의 크기를 늘리는 것은 컴퓨터 자원의 사용이 크게 증가한다.컴퓨터 계산 능력이 크게 요구된다. 예를 들어 , deep vision network에서 두개의 convolutional layers가 체인된 경우, filters 수가 증가하면 계산이 quadratic(예: x^2) 증가하게 된다. 추가된 용량이 비효율적으로 사용될 경우(예: 대부분의 가중치가 0에 가까운 경우) 계산의 많은 부분이 낭비된다. 계산 비용은 항상 한정되기 때문에, 주요 목적이 성능 품질을 높이는 것일지라도 크기를 무분별하게 증가시키는 것보다 컴퓨팅 자원의 효율적인 분배가 선호된다. (컴튜어 자원은 한정하기 때문에 , 네트워크의 사이즈를 늘리는 것 보다 컴퓨팅 자원을 효율적으로 분배하는 것이 더 중요하다.)
이 두 가지 문제를 해결하는 근본적인 방법은 sparsity 을 도입하고 , fully connected layers 를 convolutions내부에서도 layers by the sparse로 대체하는 것이다.
spare connected : 다 연결되는 것이 아니다.
fully connected : 다 연결한다.
biological systems모방하는 것 외에도 , 이것은 또한 Arora et al. [2]의 획기적인 연구로 인해 보다 확고한 이론적 토대를 가질 수 있다. 이들의 주요 결과에 따르면, 데이터 세트의 probability distribution가 크고 very sparse deep neural network에 의해 표현될 수 있는 경우, 이전 계층 활성화의 상관 통계를 분석하고 상관 관계가 높은 출력과 함께 뉴런을 클러스터링하여 optimal network topology 를 계층별로 구성할 수 있다. 엄격한 mathematical 증명은 매우 강한 조건을 요구하지만, 이 진술이 잘 알려진 Hebbian principle-함께 작동되는 뉴런들- 사실은 근본적인 아이디어가 덜 엄격한 조건에서도 실제로 적용 가능하다는 것을 암시한다.
불행히도, 오늘날의 컴퓨팅 인프라는 non-uniform sparse data structures에 대한 수치 계산에서 매우 비효율적이다. arithmetic operations의 수가 100배 감소하더라도, 검색과 캐시 누락의 오버헤드가 지배할 것이다: sparse matrices로 전환하는 것은 성과를 거두지 못할 수 있다. 이 격차는 매우 빠른 dense matrix multiplication을 가능하게 하는 꾸준히 개선되고 highly tuned numerical libraries를 사용하여 기본 CPU or GPU hardware[16, 9]의 미세한 세부정보를 함으로써 더욱 확대된다. 또한 non-uniform sparse models은 sophisticated engineering and computing infrastructure이 더 필요하다. 대부분의 현재 vision oriented machine learning systems은 단지 convolutions을 채택함으로써 spatial domain 의 희소성을 활용한다. 그러나 convolutions 은 이전 계층의 patches 에 대해 dense connections의 집합으로 구현된다. ConvNets 의 대칭성을 깨고 학습을 개선하기 위해 [11] 이후 feature dimensions에 랜덤 및 parse connection tables 을 사용해 왔지만, parallel computation을 최적화하기 위해 추세는 [9]와의 완전 연결로 다시 바뀌었다. computer vision 을 위한 현재의 state-of-the-art architectures은 균일한 구조를 가지고 있다. filters 수가 많고 배치 크기가 크기 때문에 dense computation을 효율적으로 할 수 있다.
균등 공간 (Uniform space) : 두 점이 서로 "가까운지" 여부가 주어진 집합이다.
이는 다음 중간 단계, 즉 이론에서 제안한 대로 filter-level sparsity을 사용하지만 밀도가 높은 행렬에 대한 연산을 활용하여 현재 하드웨어를 활용하는 아키텍처에 대한 희망이 있는지에 대한 의문을 제기한다. => filter-level sparsity dense matricessparse matrix computations (e.g. [3])에 대한 방대한 논문은 sparse matrices을 상대적으로 상대적으로 밀도가 높은 하위 행렬로 클러스터링하는 것이 sparse matrix multiplication에 대한 경쟁적 성능을 제공하는 경향이 있음을 시사한다. (하위 행렬로 ) 가까운 미래에 대한 non-uniform deep-learning architectures의 자동 구축을 위해 유사한 방법이 활용될 것이라고 생각하는 것은 믿기지 않은 일이 아닌 것 같다.
Inception architecture는 [2] for vision networks 에서 암시하는 sparse structure를 비슷하게 하고 dense가 높고 쉽게 사용할 수 있는 구성요소로 가정된 결과를 다루는 sophisticated network topology construction algorithm의 가상 출력을 평가하기 위한 사례 연구로 시작되었다. highly speculative undertaking에도 불구하고, Network in network [12]에 기초한 기준 네트워크와 비교했을 때 초기에 약간의 이득이 관찰되었다. 약간의 뉴닝으로 격차는 더욱 벌어졌고, 인셉션은 [6] 및 [5]의 기본 네트워크로서 localization 및 object detection의 context에서 특히 유용하다는 것이 입증되었다. 흥미롭게도 , 대부분의 초기 아키텍처 선택에 의문을 제기하고 분리하여 철저히 테스트했지만, locally으로 최적에 가까운 것으로 드러났다. 그러나 주의해야 할 것은 nception architecture가 컴퓨터 비전의 성공이 되었지만, 이것이 그것의 구축을 이끈 지침 원리에 기인할 수 있는지는 여전히 의문이라는 점이다. 이것을 확실히 하려면 훨씬 더 철저한 분석과 검증이 필요할 것이다.
4. Architectural Details




Inception architecture의 주요 아이디어는 convolutional vision network의 최적의 local sparse structure 를 어떻게 근사하고 쉽게 이요할 수 있는 dense components로 구성할 수 있을지를 알아내는 것이다. translation invariance을 가정하면 convolutional building blocks 으로 구축하는 것을 의미한다. 우리가 필요한 것은 local construction 을 찾고 , 그것을 공간적으로 반복하는 것이다. Arora et al. [2] 는 마지막 계층의 상관관계 통계를 분석하여 높은 상관관계를 가진 단위 그룹으로 군집화해야 하는 계층별 구성을 제안한다. 이러한 clusters 는 다음 계층의 단위를 형성하고 이전 계층의 단위에 연결된다. 이전 계층의 각 장치는 입력 이미지의 일부 영역에 해당하며 이러한 장치는 filter banks로 그룹화된다고 가정한다. 하위 계층 (입력 가까이에 있는 계층)에서는 상관된 단위가 로컬 영역에 집중된다. 따라서, 우리는 많은 클러스터가 단일 영역에 집중될 것이고, 그것들은 [12]에서 제시된 바와 같이, 다음 계층의 1×1 컨볼루션 층으로 덮일 수 있다. 그러나 더 큰 패치에서 컨볼루션에 의해 커버될 수 있는 공간적으로 분산된 클러스터가 더 적을 것이며 더 큰 영역에 걸쳐 패치의 수가 줄어들 것으로 기대할 수 있다. (????) (큰 patch size의 convolution을 사용함으로써, 적은 수의 cluster로도 더 넓게 펼쳐질 수 있으며, 이를 통해 patch의 수가 감소될 수도 있다. Patch는 filter로 생각하면 된다. ) patch-alignment issues를 피하기 위해, Inception architecture의 구성 요소는 1×1, 3×3 and 5×5로 제한한다. 이 결정은 필요성보다는 편의성에 더 중점을 두었다. 즉 , 제안된 아키텍처가 다음 단계의 입력을 형성하는 a single output vector로 연결된 output filter banks의 모든 layer들의 결합이라는 것을 의미한다. 또한 pooling operations은 현재 convolutional networks의 성공에 필수적으므로 , 그러한 각 단계에서 alternative parallel pooling path 를 추가하는 것도 이점을 가질 수 있다는 것을 암시한다. (see Figure 2(a)).
filter banks : 신호 처리에서 필터 뱅크는 입력 신호를 여러 구성 요소로 분리하는 대역 통과 필터의 배열이며, 각 구성 요소는 원래 신호의 단일 주파수 하위 대역을 전달합니다.
이런 “Inception modules”모델이 서로 겹쳐 쌓이면 출력의 output correlation statistics가 달라질 수 밖에 없는데, higher abstraction의 특징이 higher layers에 의해 포착되면 간 집중도가 감소할 것으로 예상된다. 이는 3×3과 5×5 컨볼루션의 비율이 더 높은 계층으로 이동함에 따라 증가해야 함을 암시한다.
위의 모델에서의 한가지 문제점은 naive form 에서 filter 수가 많은 컨볼루션 레이어 위에 적당한 수의 5×5 컨볼루션도 엄청나게 비쌀 수 있다는 것이다. 이 문제는 pooling units이 추가되면 훨씬 더 부각된다. output filters 의 수는 이전 단계의 필터 수와 같다. pooling layer 의 출력과 convolutional layers 출력의 병합은 단계마다 출력의 수의 불가피한 증가를 초래할 것이다. 이 아키텍처는 optimal sparse structure를 포함할 수 있지만, 매우 비효율적으로 수행할 수 있으며, 몇 단계 내에 계산 폭발을 초래할 수 있다.
이것은 인셉션 아키텍처의 두 번째 아이디어로 이어진다. 즉, 계산 요구 사항이 지나치게 증가할 경우 신중하게 차원을 줄이는 것이다. (=> reducing dimension) 이는 임베딩의 성공에 기반을 두고 있다 . low dimensional embeddings에도 많은 정보가 포함될 수 있다, 하지만 embeddings 은 information in a dense가 압축된 형태로 나타내며 압축된 정보는 처리하기가 더 어렵다. 표현은([2]의 조건에 의해 요구되는) 대부분의 장소에서 sparse 하게 유지되어야 하며 신호를 일괄 집계해야 할 때마다 압축해야 한다. 즉 계산량이 많은 3x3이나 5x5 convolution 이전에는 reduction을 위한 1x1 convolution이 사용된다. reduction은 rectified linear activation의 사용함으로써 dual-purpose 으로 활용된다. 최종 결과는 그림 2(b)에 나타나 있다.
일반적으로 Inception network는 위 유형의 모듈들이 서로 겹쳐져 있는 네트워크이며, grid의 해상도를 절반으로 줄이기 위해 stride 2가 있는 max-pooling layers 를 사용한다. 기술적인 이유(훈련 중 메모리 효율성)로 인해, lower layers 전통적인 convolutional 방식으로 유지하면서 higher layers에서만 사용하는 것이 유익하다. 이

는 엄격하게 필요하지 않으며 단지 현재 구현의 비효율적인 infrastructural 을 고려한 것이다.
이 architecture 의 유용한 측면은 이후의 stage 에서 omputational complexity의 제어되지 않은 blow-up in computational 증가 없이 각 단계에서 unit 수 를 크게 늘릴 수 있다는 것이다. 이는 patch sizes 를 갖는 expensive convolutions 에 앞서 어디에서나 dimensionality reduction를 사용함으로써 달성된다. 또한 디자인은 visual information를 different scales로 처리하고 그 다음 단계가 다른 척도에서 동시에 특징을 추상화할 수 있도록 종합해야 한다는 실용적인 직관을 따른다.
computational resources의 사용이 개선되어 , 각 stage 의 width 은 computational 에 빠지지 않게 단계 수를 늘릴 수 있다.
Inception architecture를 사용하여 약간의 열등하지만 계산적으로는 더 저렴한 버전을 만들 수 있다. 우리는 사용 가능한 모든 knobs and levers 를 통해 계산 리소스의 제어된 밸런싱을 허용하여 비인셉션 아키텍처의 유사한 수행 네트워크보다 3~10배 빠른 네트워크를 만들 수 있지만, 이 시점에서 신중한 수동 설계가 필요하다는 것을 발견했다.
NIN
컴퓨팅 자원 등
5. GoogLeNet





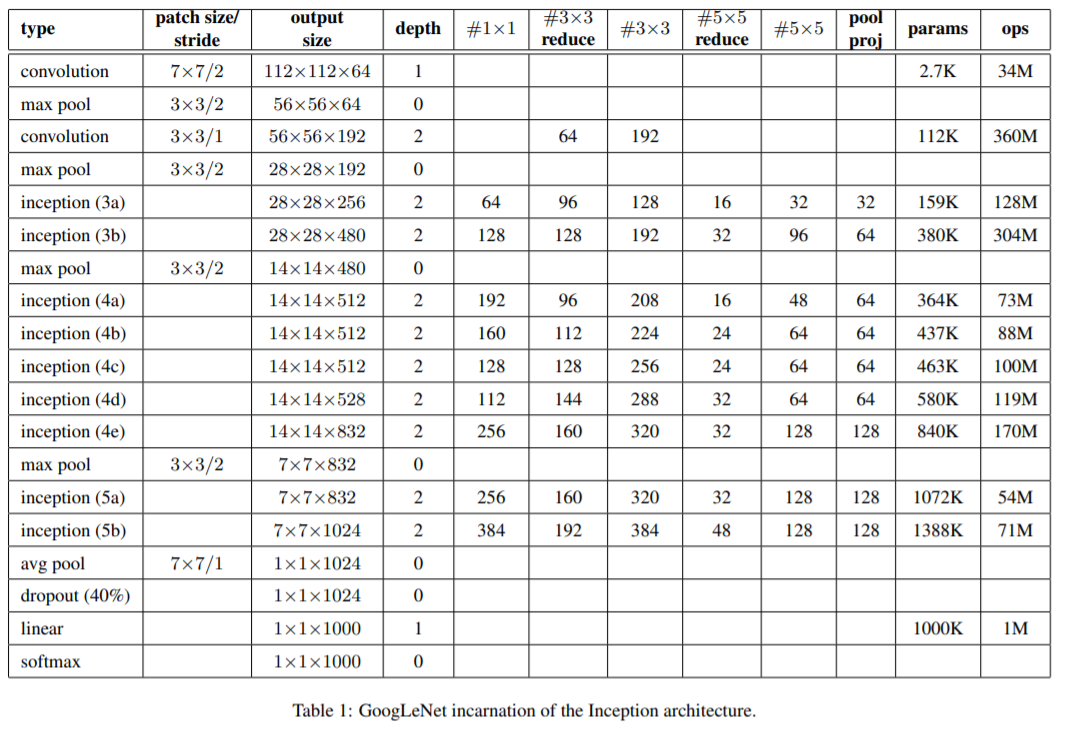
“GoogLeNet”이름으로 우리는 ILSVRC 2014 competition submission Inception architecture의 특징 형태를 말한다 . 우리는 약간 우수한 품질의 깊고 넓은 Inception network를 사용했고 그 네트워크는 앙상블에 추가하니 결과만 조금 나아지는 것 같았다. 경험에 따르면 , exact architectural parameters 의 영향은 상대적으로 미미하며, network의 세부 사항은 생략한다. Table 1은 competition에서 가장 흔히 사용되는 인셉션의 예를 보여준다. 이 네트워크(다른 이미지 패치 샘플링 방법으로 훈련됨)는 앙상블의 7개 모델 중 6개 모델에 사용되었다.
Inception modules 내부를 포함한 모든 convolutions은 rectified linear activation를 사용한다. receptive field의 크기는 the RGB color space with zero mean에서 224×224이다. “#3×3 reduce” 와 “#5×5 reduce” 는 3×3 and 5×5 convolutions 이전에 사용된 reduction layer 1×1 filters를 볼 수 있다. pool proj column에 내장된 max-pooling후 projection layer 에서 1×1 filters를 볼 수 있다. 이 모든 reduction/projection layers은 rectified linear activation도 사용한다.
네트워크는 계산 효율성과 실용성을 염두에 두고 설계되었으며, 특히 메모리 공간이 적은 계산 자원을 가진 장치를 포함하여 개별 장치에서 추론을 실행할 수 있다.
이 네트워크는 parameters 가 있는 layer만 셀 때 22 layers deep
pooling까지 계산하면 27 layers이다.
네트워크 구축에 사용되는 전체 계층(independent building blocks) 수는 약 100개이다. exact number는 machine learning infrastructure에 의해 layers 계산하는 방식에 따라 달라진다. 분류기 이전의 평균 풀링의 사용은 [12]에 에 두고 있어나 우리의 구현은 추가적인 linear layer를 가지고 있다. linear layer를 사용하면 네트워크를 다른 레이블 세트에 쉽게 적응시킬 수 있지만, 주로 편의상 사용되며 큰 효과를 기대할 수 없다. fully connected layers에서 average pooling 사용하면 top-1 정확도를 0.6% 정도 증가했으나 dropout의 중요성은 fully connected layers층이 없음에도 중요한 역할을 보였다.
linear layer => fully connected layers
네트워크의 비교적 큰 깊이를 고려할 때, gradients 를 효과적으로 모든 계층을 통해 다시 전파할 수 있는 능력이 관심사였다. 이 작업에서 shallower networks의 강력한 성능은 네트워크 중간에 있는 층에 의해 생성된 기능이 매우 차별적이어야 함을 시사한다.이러한 중간 계층에 연결된 auxiliary classifiers를 추가함으로써, 분류기에서 하위 단계의 차별이 예상되었다. 또한, 저자들은 보조 분류기의 추가가 regularization 효과와 함께 vanishing gradient problem를 해결해주는 것으로 생각한다. 이러한 분류기는 인셉션 (4a) 및 (4d) 모듈의 출력 위에 놓인 더 작은 컨볼루션 네트워크의 형태를 취한다. 학습 기간에는 그들의 손실은 할인 가중치로 네트워크의 전체 손실에 더해진다. (보조 분류기의 손실은 0.3으로 가중되었다.) (보조 분류기의 loss는 30%만 고려하고 있다.) 추론 에서는 auxiliary networks를 사용하지 않는다. 이후 control experiments 결과 auxiliary networks의 효과는 상대적으로 미미하며(약 0.5%) 동일한 효과를 달성하는 데 두 네트워크 중 하나만 필요하다는 것이 밝혀졌다.
auxiliary classifier를 포함한 extra network on the side의 정확한 구조는 다음과 같다.
• filter size 5×5 와 stride 3 인 average pooling layer 출력의 shape은 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
• dimension reduction을 위한 1×1 convolution with 128 filters및 rectified linear activation.
• fully connected layer 1024 units 및 rectified linear activation.
• 70% ratio dropout layer
• linear layer 를 사용한 softmax loss as the classifier 1000(predicting the same 1000 classes as the main classifier, but removed at inference time).
결과적으로 얻은 schematic view은 그림 3에 설명되어 있다.

6. Training Methodology


GoogLeNet 네트워크는 적당한 양의 모델과 데이터 병렬주의를 사용하여 DistBelief[4] 분산 머신러닝 시스템을 사용하여 훈련되었다. CPU based implementation 으로 사용했지만, 대략적인 추정에 따르면 GoogLeNet 네트워크는 일주일 내에 고급 GPU 몇 개를 사용하여 수렴하도록 훈련될 수 있으며, 주요 제한 사항은 메모리 사용량이다. 우리의 학습에서는 asynchronous stochastic gradient descent with 0.9 momentum [17]
fixed learning rate schedule (decreasing the learning rate by 4% every 8 epochs)
을 사용했다. 추론 시간에 사용된 최종 모델을 만들기 위해 Polyak averaging [13]을 사용했다.
Image sampling방법은 competition의 몇달 동안 크게 변화하였으며, 이미 converged models은 다른 옵션과 함께 학습되었으며, 때로는 dropout 및 learning rate과 같은 hyperparameters를 변화했기도 했다. 따라서 이러한 네트워크를 학습시키는 가장 효과적인 단일 방법에 대한 명확한 지침을 제공하는 것은 어렵다. 상황을 더 복잡하게 만든다면, 일부 모델은 주로 [8]에서 영감을 받아 작은 crop에 대해 주로 학습하였고 , 다른 모델은 더 큰 crop에 대해 학습되었다. 그러나 competition후 매우 잘 작동하는 것으로 확인된 한 가지 처방에는 가로 세로 비율이 간격에 제한된 이미지 영역의 8%와 100% 사이에 크기가 고르게 분포된 이미지의 다양한 크기의 패치 샘플링이 포함된다 [ 3/4,4/3]. ([ 3/4,4/3] 로 제한하여 8%와 100% 크기에서 균등 분포로 patch sampling 하는 것이 매우 잘 동작한다. 다양한 patch의 크기를 사용한다. ) 또한 Andrew Howard[8]의 photometric distortions 이 훈련 데이터의 imaging 조건에 overfitting 하는데 유용하는 것을 발견되였다.
7. ILSVRC 2014 Classification Challenge Setup and Results





ILSVRC 2014 classification challenge 과제는 Imagenet 에서 1000개의 leaf-node categories에서 하나 선택하는 것이다.
training 1.2 million images
validation 50,000 images
testing 100,000 images
각 이미지는 하나의 ground truth category와 연결되며, 성능은 가장 높은 점수 분류기 예측을 기반으로 측정된다. 두가지 종류의 수치를 본다.
the top-1 accuracy rate : ground truth가 와 first predicted class비교
the top-5 error rate : ground truth가 와 first 5 predicted class비교 top-5 개의 class 안에 ground truth가 올바를 경우 순위에 상관 없이 정답이라고 한다.
대회에서 순위를 할 경우에는 top-5 error rate 을 사용한다.
우리는 external data를 학습하지 않은 상태로 대회에 참가했다. 본 논문에서 언급한 학습기법 외에도 , 우리는 더 높은 성능을 얻기 위해 테스트 중에 일련의 기술을 채택했으며, 이 기술은 다음에 설명한다.
1. 앙상블 - 동일한 GoogLeNet 모델 7개 버전(더 넓은 버전 1개 포함)을 독립적으로 교육하고 앙상블 예측을 수행했다. 각 모델들은 동일한 widht initialization (감독으로 인해 동일한 초기 가중치를 사용하더라도) 과 learning rate policies학습하였다. 그들은 sampling methodologies와 randomized input image order만 달랐다.
2. testing동안 우리는 Krizhevsky et al. [9] 그것보다 더 aggressive cropping 자르기 접근법을 채택했다.구체적으로 더 짧은 dimension (height or width) 가 각각 256, 288, 320 및 352인 4개의 scale으로 이미지의 크기를 조정한 다음 크기가 조정된 이미지의 왼쪽, 가운데, 오른쪽 정사각형을 취한다(세로 이미지의 경우 위쪽, 가운데, 아래쪽 정사각형을 취한다). 정 사각형에 대해, 4 corners and the center 224×224 crop 그리고 square resized to 224×224와 조정된 their mirrored versions을 취한다. 이는 이미지당 4×3×6×2 = 144개의 crops로 이어진다. 유사한 접근방식은 전년도의 출품작에서 Andrew Howard[8]에 의해 사용되었으며, 우리는 제안된 계획보다 약간 더 나쁜 성능을 수행하는 것으로 경험적으로 검증했다. 적정한 수의 crops 이 존재하면 더 많은 crops의 이점이 미미해지기 때문에 실제 적용에서는 그러한 공격적인 crops이 필요하지 않을 수 있다는 점에 주목한다.
3. softmax probabilities 은 최종 예측을 얻기 위해 여러 crops과 모든 개별 분류자에 걸쳐 평균화된다. 실험에서 crops에 대한 max pooling 및 분류기에 대한 평균화와 같은 검증 데이터에 대한 대체 접근 방식을 분석했지만, 단순한 평균보다 성능이 떨어진다.
이 논문의 나머지 부분에서는 최종 성과에 기여하는 여러 요인을 분석한다.
우리의 final submission to the challenges는 검증 및 테스트 데이터 모두에서 상위 5개 오류를 6.67% 얻어 다른 참가자 중 1위를 차지했다. 이는 2012년 SuperVision 접근법에 비해 56.5%의 상대적 감소이며, 두 가지 모두 분류기 교육에 외부 데이터를 사용한 전년도 최우수 접근법(Clarifai)에 비해 약 40%의 상대적 감소이다.Table 2 는 지난 3년간 가장 실적이 좋은 접근법의 통계를
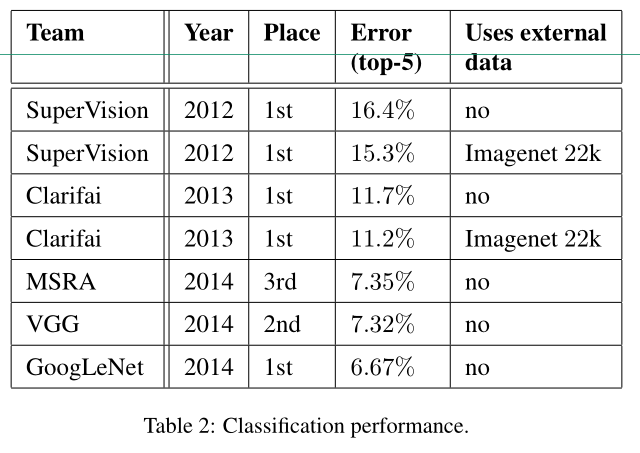
보여준다.
또한 Table 3 에서 이미지를 예측할 때 사용되는 모델 수 와 crops수를 변경하여 여러 테스트 선택의 성능을 분석하고 보고한다. 하나의 모델을 선택할 때, 우리는 validation data에서 가 top-1 error rate 가 잴 낮은 것을 선택했다. 모든 숫자는 testing data statistics에 overfit 되지 않도록 validation dataset에 대해 보고했다.
8. ILSVRC 2014 Detection Challenge Setup and








Results
ILSVRC detection task은 200개의 가능한 클래스 중 이미지의 객체 주위에 경계 상자를 생성하는 것이다. 감지된 객체가 ground truth 와 class 일치 bounding boxes overlap by at least 50%이 되는 경우에 정답인 것으로 계산된다. 관련 없는 검출은 잘못된 긍정으로 계산되고 penalized을 받는다. classification task와 반대로 , 각 이미지에는 많은 개체가 포함되어 있거나 개체가 없을 수 있으며 그 크기는 다를 수 있다. 결과는 평균 평균 정밀도(mAP)를 사용하여 보고된다. GoogLeNet이 감지를 위해 취하는 접근 방식은 [6]의 R-CNN과 유사하지만, 영역 분류기로 인셉션 모델을 통해 강화된다. 또한 selective search [20] 접근법과 더 높은 object bounding box recall을 위한 multi-box [5] 예측을 결합함으로써 region proposal step 가 개선된다. false positives의 수를 줄이기 위해 super-pixel size를 2배 증가시켰다. 이것은 selective search algorithm에서 나오는 제안들을 반으로 줄였다. 우리는 multi-box [5] 에서 나온 200 region proposals을 추가했고 , 그 결과 [6]에서 사용한 제안의 약 60%가 적용 범위를 92%에서 93%로 늘렸다. coverage 가 확대된 proposals 수를 삭감하는 전체적인 효과는 single model case의 mean average precision가 1% 향상된 것이다. 마지막으로 , 우리는 each region을 classifying 할 때 6개의 GoogLeNets 앙상블을 사용한다. 따라서 정확도가 40%에서 43.9%로 향상된다. R-CNN과는 달리, 시간 부족으로 인해 bounding box regression를 사용하지 않았다.
우리는 먼저 top detection results를 보고 detection task의 first edition이후 진행 상황을 보여준다. 2013년 결과와 비교하면 정확도가 두 배 가까이 높아졌다. top performing teams은 모두 convolutional networks를 사용한다. Table 4의 official scores와 각 팀의 common strategies : external data, ensemble models 혹은 contextual models사용)을 보고한다. external data는 일반적으로 나중에 detection data에서 세부화된 pre-training을 위한 ILSVRC12 분류 데이터이다. Some teams은 localization data의 사용을 언급하기도 한다. localization task bounding boxes 의 상당 부분이 detection dataset에 포함되지 않기 때문에, pre-train에 사용되는 분류와 동일한 방식으로 이 데이터로 일반 경계 상자 회귀기를 pre-training할 수 있다. GoogLeNet 항목은 pretraining에 localization data를 사용하지 않는다.
Table 5에서는 우리는 single model만을 사용하여 비교한다. 최고 성능 모델은 Deep Insight 에 의해 이루어지며, 3개 모델의 앙상블에서 0.3%만 놀랍게도 향상된다.GoogLeNet이 앙상블을 통해 상당히 더 강력한 결과를 얻는다.
9. Conclusions
우리의 결과는 쉽게 구현 가능한 dense building blocks요소를 통해 예상되는 optimal sparse structure를 근사화 하는 것이 , computer vision을 위한 neural networks을 개선하기 위한 실행 가능하는 방법이라는 것을 확실한 증거를 산출한다. 이 방법의 장점은 shallower and narrower architectures에 비해 computational requirements 이 약간 증가할 때 상당한 품질 향상이다. 우리의 object detection work은 context 를 활용하지 않거나 bounding box regression를 수행하지 않음에도 불구하고 competitive , 이는 Inception architecture 의 강점에 대한 추가적인 증거를 시사한다.
classification and detection는 모두 depth and width 비슷한 훨씬 비싼 non-Inception-type networks를 통해 유사한 품질의 결과를 얻을 수 있을 것으로 기대된다. 여전히 우리의 접근 방식은 sparser architectures 로의 이동이 일반적으로 실현 가능하고 유용한 아이디어라는 확실한 증거를 제시한다. 이는 Inception architecture 의 통찰력을 다른 도메인에 적용하는 것뿐만 아니라 [2]를 기반으로 자동화된 방법으로 더 희소하고 정교한 구조를 만드는 향후 작업을 시사한다.
[참고 논문]:
Going Deeper with Convolutions
[참고]:
[논문] GoogleNet - Inception 리뷰 : Going deeper with convolutions
논문 링크 : https://arxiv.org/pdf/1409.4842.pdf Abstract 본 논문은 ImageNet Large-Scale Visual Recognition Challenge 2014(ILSVRC14)에서 classification 및 detection를 위한 최점단 기술인 codename In..
leedakyeong.tistory.com
https://ko.wikipedia.org/wiki/%EA%B7%A0%EB%93%B1_%EA%B3%B5%EA%B0%84
균등 공간 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 일반위상수학에서, 균등 공간(均等空間, 영어: uniform space)은 두 점이 서로 "가까운지" 여부가 주어진 집합이다. 균등 공간 위에는 균등 연속 함수 · 코시 그물 ·
ko.wikipedia.org
https://sike6054.github.io/blog/paper/second-post/
(GoogLeNet) Going deeper with convolutions 번역 및 추가 설명과 Keras 구현
Paper Information
sike6054.github.io
요즘 파파고도 잘 되어 있어서 파파고 번역을 많이 참고하였다.