7장. 정규 표현식
I. 정규 표현식 살펴보기
정규 표현식(Regular Expressions) 은 복잡한 문자열을 처리할 때 사용하는 기법으로 문자열을 처리하는 모든 곳에서 사용함
isdigit()는 음수나 소숫점이 포함된 숫자는 False를 리턴한다. 대충 생각해서는 왠지 될 것 같은데 안된다.
정규 표현식은 왜 필요한가?
주민등록번호를 포함하고 있는 텍스트가 있다. 이 텍스트에 포함된 모든 주민등 록번호의 뒷자리를 * 문자로 변경해 보자.
정규식을 모르면, 다음과 같은 순서로 프로그램을 작성해야 할 것임
1. 전체 텍스트를 공백 문자로 나눈다(split).
2. 나뉜 단어가 주민등록번호 형식인지 조사한다.
3. 단어가 주민등록번호 형식이라면 뒷자리를 *로 변환한다.
4. 나뉜 단어를 다시 조립한다.
주민등록번호의 뒷자리를 * 문자로 구현한 코드
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6] +"-" + "******"
word_result.append(word)
result.append(" ".join(word_result))
print("\n".join(result))
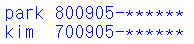
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):#공백 문자마다 나누기
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6]+"-"+"*******"
word_result.append(word)
result.append(" ".join(word_result))#나눈 단어 조립하기
print("\n".join(result))
주민등록번호의 뒷자리를 * 문자로 구현한 정규 표현식
import re
pat = re.compile("(\d{6})[-]\d{7}")#class가 만든 객체
#(\d{6})[-]\d{7}자열을 확인
#()->group으로 하기->g1
#\d 숫자인 것을 찾아내라
print(pat.sub("\g<1>-*******",data))#함수 호출
###########정규표현식
import re
pat = re.compile("(\d{6})[-]\d{7}")#class가 만든 객체
#(\d{6})[-]\d{7}자열을 확인
#()->group으로 하기->g1
#\d 숫자인 것을 찾아내라
print(pat.sub("\g<1>-*******",data))#함수 호출
정규 표현식을 사용하면 훨씬 간편하고 직관적인 코드를 작성할 수 있음
찾으려는 문자열 또는 바꾸어야 할 문자열의 규칙이 매우 복잡하다면, 정규식의 효용은 더 커지게 됨
II. 정규 표현식 시작하기
=>정규 표현식의 기초, 메타 문자
메타 문자란 원래 그 문자가 가진 뜻이 아닌 특별한 용도로 사용하는 문자를 말함
==>문자 클래스 [ ]
'[ ] 사이의 문자들과 매치’라는 의미를 갖음

하이픈(-)는 두 문자 사이의 범위(From - To)를 의미함
^는 반대(not)를 의미함
[a-zA-Z] :알파벳 모두
[0-9] : 숫자
자주 사용하는 문자 클래스

대문자로 사용된 것은 소문자의 반대임
==>Dot(.)
Dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미함
a.b “a + 모든 문자 + b” a하고 b사이 한문자
a와 b사이에 줄 바꿈 문자를 제외한 어떤 문자가 들어가도 모두 매치
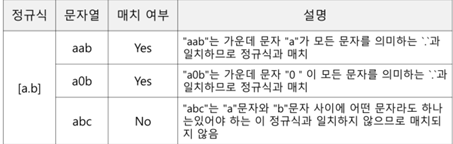
a[.]b는 문자 . 그대로를 의미함 (“a + Dot(.)문자 + b”)
이 경우에는 "a.b" 문자열과 매치되고 "a0b" 문자열과는 매치되지 않는다.
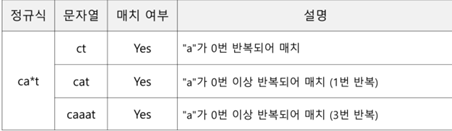
==>반복(*)
* 메타 문자는 반복을 의미함. 0부터 무한대로 반복될 수 있음
ca*t * 문자 바로 앞에 있는 a가 0번 이상 반복되면 매치
ca*t a를 0번부터 무한 반복
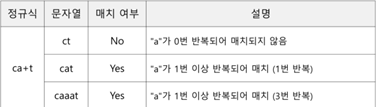
==>반복(+)
+ 메타 문자도 반복을 의미함. 최소 1번 이상 반복될 때 사용함
ca+t “c + a(1번 이상 반복) + t”
==>반복({m,n}, ?)
반복 횟수를 제한하고 싶을 때 사용
{m,n}는 반복 횟수가 m부터 n까지 매치할 수 있음. m 또는 n을 생략할 수도 있음
{m,}는 반복 횟수가 m 이상이고, {,n}는 반복 횟수가 n 이하를 의미함
{1,}은 +와 동일하고, {0,}은 *와 동일함
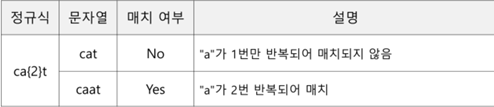
1. {m}
ca{2}t a가 2번 반복되면 매치, “c + a(반드시 2번 반복) + t”
2. {m,n}
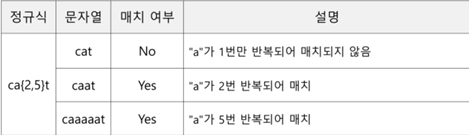
ca{2,5}t a가 2~5번 반복되면 매치, “c + a(2~5번 반복) + t”
3.?
? 메타 문자는 {0, 1}을 의미함
ab?c b가 0~1번 사용되면 매치, “a + b(있어도 되고 없어도 된다) + c"

*, +, ? 메타 문자는 모두 {m, n} 형태로 고쳐 쓰는 것이 가능하지만, 가급적 간결한 *, +, ? 메타 문자를 사용하는 것이 좋음
파이썬에서 정규 표현식을 지원하는 re 모듈
re 모듈은 파이썬 설치할 때 자동으로 설치되는 기본 라이브러리임
>>> import re
>>> p = re.compile('ab*')
re.compile을 사용하여 정규 표현식을 컴파일함
re.compile의 결과로 돌려주는 객체 p (컴파일된 패턴 객체) 를 사용하여 그 이후의 작업을 수행함
==>정규식을 사용한 문자열 검색
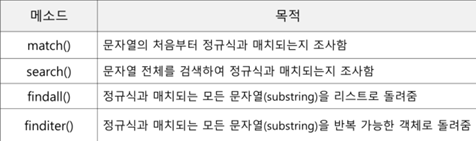
컴파일된 패턴 객체는 4가지 메소드를 제공함
match() 문자열의 처음부터 정규식과 매치되는지 조사함
처음부분
search() 문자열 전체를 검색하여 정규식과 매치되는지 조사함
어디 있는 지 관계없다.
findall() 정규식과 매치되는 모든 문자열(substring)을 리스트로 돌려줌
객체로 돌려주면 class
findall은 함수이다.
finditer() 정규식과 매치되는 모든 문자열(substring)을 반복 가능한 객체로 돌려줌
match, search는 정규식과 매치될 때는 match 객체를 돌려주고, 매치되지 않을 때는 None을 돌려줌
#########match
>>> import re
>>> p = re.compile('[a-z]+')
>>> m = p.match("python")
>>> print(m)
>>> m = p.match("3 python")
>>> print(m)

match의 결과로 객체 또는 None 을 돌려주기 때문에 다음의 흐름으로 작성함

###########[]
#+최소한 한번 와야 한다 match
data=('python','3 python')
p = re.compile('[a-z]+')
for i in data:
m = p.match(i)
#print(m)
#<re.Match object; span=(0, 6), match='python'>
#None
if m:
print("Match Found match: ",m.group())
print("Match Found match: ",m.start())
print("Match Found match: ",m.end())
print("Match Found match: ",m.span())
else:
print("No match match")

#########search
문자열 전체를 검색하여 정규식과 매치되는지 조사함
>>> import re
>>> p = re.compile('[a-z]+')
>>> m = p.search("python")
>>> print(m)
>>> m = p.search("3 python")
>>> print(m)

문자열 전체를 검색하기 때문에 “3” 이후의 “python” 문자열과 매치됨
for i in data:
m = p.search(i)
#print(m)
#<re.Match object; span=(0, 6), match='python'>
#<re.Match object; span=(2, 8), match='python'>
if m:
print("Match Found search: ",m.group())
else:
print("No match search")

#########findall
정규식과 매치되는 모든 문자열(substring)을 리스트로 돌려줌
>>> import re
>>> p = re.compile('[a-z]+')
>>> result = p.findall("life is too short")
>>> print(result)

result = p.findall("life1 is tooA short")
print(result)
#print(result[0])
#########finditer
정규식과 매치되는 모든 문자열(substring)을 반복 가능한 객체로 돌려줌
>>> result = p.finditer("life is too short")
>>> print(result)
>>> for r in result:print(r)

result = p.finditer("life is too short")
#print(result)#<callable_iterator object at 0x000002CE171C4CA0>
for i in result:
print(i.group())
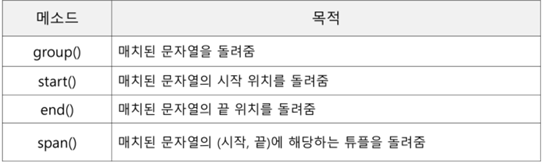
===> match, search 객체의 메소드
어떤 문자열이 매치되었는가?
매치된 문자열의 인덱스는 어디부터 어디까지인가?
match, search 객체의 메소드 사용 예:
>>> import re
>>> p = re.compile('[a-z]+')
>>> m = p.match("python")
>>> m.start()
>>> m.end()
>>> m.span()
>>> m = p.search("3 python")
>>> m.start()
>>> m.end()
>>> m.span()


메소드 결과값이 다르게 나오는 것을 확인할 수 있음
==>[모듈 단위로 수행하기]
re 모듈은 축약된 형태로 사용할 수 있는 방법을 제공함
이 방식은 잘 사용하지 않는다. 메소드를 다양하게 사용해야 하는데
이것은 한번밖에 사용 안 된다.
#m = re.match(patten,string)
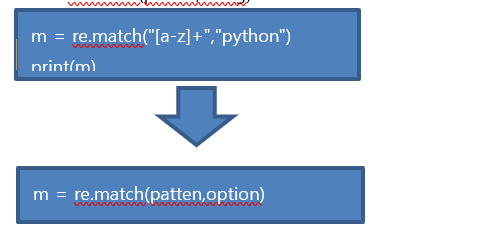
한 번 만든 패턴 객체를 여러 번 사용해야 할 때는 re.compile을 사용하는 것이 좋음
=>컴파일 옵션
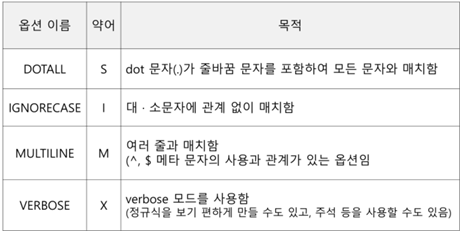
DOTALL S dot 문자(.)가 줄바꿈 문자를 포함하여 모든 문자와 매치함
IGNORECASE I 대 · 소문자에 관계 없이 매치함
MULTILINE M 여러 줄과 매치함 (^, $ 메타 문자의 사용과 관계가 있는 옵션임
각 라인의 처음 ^ 각 라인의 마지막 $
VERBOSE X verbose 모드를 사용함 (정규식을 보기 편하게 만들 수도 있고, 주석 등을 사용할 수도 있음)
verbose 주석을 다라 주는 것
==> DOTALL, S
dot 문자(.)가 줄바꿈 문자(\n)를 포함하여 모든 문자와 매치함
re.DATALL 또는 re.S 옵션을 사용해 정규식을 컴파일하면 됨
>>> import re
>>> p = re.compile('a.b')
>>> m = p.match('a\nb')
>>> print(m) # 문자열과 정규식이 매치되지 않음
>>> p = re.compile('a.b',re.DOTALL)
>>> m = p.match('a\nb')
>>> print(m)
>>> p = re.compile('a.b',re.S)
>>> m = p.match('a\nb')
>>> print(m)


==> IGNORECASE, I
re.IGNORECASE 또는 re.I 옵션은 대 · 소문자에 관계 없이 매치함
>>> p = re.compile('[a-z]',re.I)
>>> p.match('python')
<re.Match object; span=(0, 1), match='p'>
>>> p.match('Python')
<re.Match object; span=(0, 1), match='P'>
>>> p.match('PYTHON')
<re.Match object; span=(0, 1), match='P'>
==> MULTILINE, M
re.MULTILINE 또는 re.M 옵션은 메타 문자인 ^, $와 연관된 옵션임
^는 문자열의 처음을 의미하고, $은 문자열의 마지막을 의미함
>>> import re
>>> p = re.compile("^python\s\w+")
>>> data = """python one
life is too short
python two
you need python
python three"""
>>> print(p.findall(data))
['python one']
re.MULTILINE 또는 re.M 옵션은 ^, $ 를 문자열의 각 줄마다 적용해 주는 것임
>>> import re
>>> p = re.compile("^python\s\w+",re.MULTILINE)
>>> data = """python one
life is too short
python two
you need python
python three"""
>>> print(p.findall(data))
['python one', 'python two', 'python three']
==> VERBOSE, X
re.VERBOSE 또는 re.X 옵션은 정규식을 보기 편하게 주석 또는 줄 단위로 구분 할 수도 있음

문자열에 사용된 whitespace는 컴파일할 때 제거됨([ ]안은 제외)
줄 단위로 #기호를 사용하여 주석문을 작성할 수 있음
=> 백슬래시 문제
“\section”와 같이 \ 문자가 포함된 문자열을 찾을 때 혼란을 줌
\section
\s 문자가 whitespace로 해석되어 의도한 대로 매치가 이루어지지 않음
[ \t\n\r\f\v]ection 도 동일하게 whitespace로 해석됨
정규식에서 사용한 \ 문자가 문자열 자체임을 알려 주기 위해 백슬래시 2개를 사용하여 이스케이프 처리를 해야 함
>>> p = re.compile('\\section')
>>> p = re.compile('\\\\section')
\를 사용한 표현이 너무 복잡하여 Raw String 규칙이 생겨나게 됨
>>> p = re.compile(r'\\section')
정규식 문자열 앞에 r 문자를 삽입하면, Raw String 규칙에 의하여 백슬래시 2개 대신 1개만 써도 2개를 쓴 것과 동일한 의미를 갖게 됨
import re
p = re.compile('\\section')
print(p.match('\section'))
#None
p = re.compile('\\\\section')
print(p.match('\section'))
#<re.Match object; span=(0, 8), match='\\section'>
#\를 사용한 표현이 너무 복잡하여 Raw String 규칙이 생겨나게 됨
p = re.compile(r'\\section')
print(p.match('\section'))
#<re.Match object; span=(0, 8), match='\\section'>
III. 강력한 정규 표현식의 세계로
그룹(Group)을 만드는 법, 전방 탐색 등 강력한 정규 표현식을 살펴봄
=>메타 문자
+, *, [], {} 등의 메타 문자는 매치가 진행될 때 매치되고 있는 문자열의 위치가 변경되지만 (소비된다고 표현) , 문자열을 소비시키지 않는 메타 문자도 있음
==>|
| 메타 문자는 or과 동일한 의미로 사용됨
>>> p = re.compile('Crow|Servo')
>>> m = p.match('CrowHello')
>>> print(m)
<re.Match object; span=(0, 4), match='Crow'>
==>^
^ 메타 문자는 문자열의 맨 처음과 일치함을 의미함
>>> print(re.search('^Life','Life is too short'))
<re.Match object; span=(0, 4), match='Life'>
>>> print(re.search('^Life','MyLife'))
None
p = re.compile('^Life')
print(p.search('Life is too short'))
#<re.Match object; span=(0, 4), match='Life'>
re 모듈의 축약된 형태
re.MULTILINE을 사용할 경우에는 여러 줄의 문자열일 때 각 줄의 처음과 일치함
==>$
$ 메타 문자는 문자열의 끝과 매치함을 의미함
>>> print(re.search('short$','Life is too short'))
<re.Match object; span=(12, 17), match='short'>
>>> print(re.search('short$','Life is too short,you need python'))
None
p = re.compile('short$')
print(p.search('Life is too short'))
#<re.Match object; span=(12, 17), match='short'>
==>\A
\A는 문자열의 처음과 매치됨을 의미함
\A는 줄과 상관없이 전체 문자열의 처음하고만 매치됨
==>\Z
\Z는 문자열의 끝과 매치됨을 의미함
\Z는 줄과 상관없이 전체 문자열의 끝과 매치됨
==>\b
\b는 단어 구분자(Word boundary)이며, 단어는 whitespace에 의해 구분됨
>>> p = re.compile(r'\bclass\b')
>>>
>>> print(p.search('no class at all'))
<re.Match object; span=(3, 8), match='class'>
>>> print(p.search('the declassified algorithm'))
None
>>> print(p.search('one subclass is'))
None
\b는 파이썬 리터럴 규칙에 의하면 백스페이스(BackSpace)를 의미하므로, 구분자임을 알려 주기 위해 r’\bclass\b’처럼 Raw string임을 알려주는 기호r을 반드시 붙여 주어야 함
==>\B
\b의 반대로, \B는 whitespace로 구분된 단어가 아닌 경우에만 매치됨
>>> p = re.compile(r'\Bclass\B')
>>>
>>> print(p.search('no class at all'))
None
>>> print(p.search('the declassified algorithm'))
<re.Match object; span=(6, 11), match='class'>
>>> print(p.search('one subclass is'))
None
class 단어의 앞뒤에 whitespace가 하나라도 있는 경우에는 매치가 안됨
==>그루핑
ABC 문자열이 계속해서 반복되는지 조사하는 정규식을 작성하고 싶을 때 사용됨
예: (ABC)+
>>> p = re.compile('(ABC)+')
>>> m = p.search('ABCABCABC OK?')
>>> print(m)
<re.Match object; span=(0, 9), match='ABCABCABC'>
>>> print(m.group())
ABCABCABC
‘\w+\s+\d+[-]\d+[-]\d+’은 ‘이름 + “ “ + 전화번호’ 형태의 문자열을 찾는 정규식
\w+\s+\d+[-]\d+[-]\d+
\w 문자 숫자
\s white space
>>> p = re.compile(r"\w+\s+\d+[-]\d+[-]\d+")
>>> m = p.search("park 010-1234-1234")
그룹핑하고 ‘이름’ 부분만 뽑아내기
>>> p = re.compile(r"(\w+)\s+\d+[-]\d+[-]\d+")
>>> m = p.search("park 010-1234-1234")
>>> print(m.group(1))
park
이름에 해당하는 ‘\w+’ 부분을 그룹 ‘(\w+)’으로 만들면, match 객체의 group(인덱스) 메소드를 사용하여 그루핑된 부분의 문자열만 뽑아낼 수 있음
==>‘전화번호’ 부분만 뽑아내기
>>> p = re.compile(r"(\w+)\s+(\d+[-]\d+[-]\d+)")
>>> m = p.search("park 010-1234-1234")
>>> print(m.group(2))
010-1234-1234
==>‘국번’ 부분만 뽑아내기
>>> p = re.compile(r"(\w+)\s+((\d+)[-]\d+[-]\d+)")
>>> m = p.search("park 010-1234-1234")
>>> print(m.group(3))
010
그룹이 중첩되어 있는 경우는 바깥쪽부터 시작하여 안쪽으로 들어갈수록 인덱스가 증가함
==>그루핑된 문자열 재참조하기
>>> p = re.compile(r'(\b\w+)\s+\1')
>>> p.search('Paris in the the spring').group()
'the the'
정규식 ‘(\b\w+)\s+\1’은 ‘(그룹) + “ “ + 그룹과 동일한 단어‘와 매치됨을 의미
2개의 동일한 단어를 연속적으로 사용해야만 매치됨
\1은 정규식의 그룹 중 첫 번째 그룹을 가리키고, \2는 두 번째 그룹을 참조함
\1 한번더 쓰라 첫번때 그룹 재창조 하고 싶을때 \1
두번째 그룹 \2
=>그루핑된 문자열에 이름 붙이기
정규식 안에 그룹이 많고 그룹이 추가 및 삭제되면, 그 그룹을 인덱스로 참조한 프로그램도 모두 변경해 주어야 하는 위험이 있음
이러한 이유로 그룹 이름을 지정할 수 있게 했음
(?P<name>\w+)\s+((\d+)[-]\d+[-]\d+)
그룹에 이름을 지어 주려면, (\w+) (?P<name>\w+) 변경하면 됨
>>> p = re.compile(r'(?P<name>\b\w+)\s+((\d+)[-]\d+[-]\d+)')
>>> m = p.search("park 010-1234-1234")
>>> print(m.group("name"))
park
print(m.group("name"))와 print(m.group(1)) 결과는 같다.
name이라는 그룹 이름으로 참조할 수 있음
>>> p = re.compile(r'(?P<word>\b\w+)\s+(?P=word)')
>>> p.search('Paris in the the spring').group()
'the the'
그룹 이름도 정규식 안에서 재참조할 때는 (?P=그룹이름) 확장 구분을 사용함
=>전방 탐색
[.] ->새파일.txt .표현
#긍정형 전방 탐색
>>> p = re.compile(".+:")
>>> m = p.search("http://google.com")
>>> print(m.group())
http:
?=: : 으로 제외하는데 :이것으로 끝내는 것 찾기
“.+:”과 일치하는 문자열로 http:를 돌려줌
http:라는 검색 결과에서 :을 제외하고 싶을 때, 전방 탐색임

==>긍정형 전방 탐색
>>> p = re.compile(".+(?=:)")
>>> m = p.search("http://google.com")
>>> print(m.group())
http
http:라는 검색 결과에서 :을 제외하고 돌려줌
==>부정형 전방 탐색
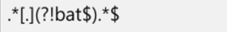
확장자가 bat가 아닌 경우에만 통과된다는 의미임

확장자가 bat 또는 exe가 아닌 경우에는 통과된다는 의미임
p = re.compile(".*[.](?!bat$).*$")
#.* -> * 0번부터
#bat 가 아닌 것을
m = p.search("aa.exe")
print(m)
p = re.compile(".*[.](?!bat$|exe$).*$")
#.* -> * 0번부터
#bat 가 아닌 것을
#[.] 실제 점을 찍고 싶을 때
m = p.search("aa.txt")
print(m)
=>문자열 바꾸기
sub 메소드를 사용하면 정규식과 매치되는 부분을 다른 문자로 쉽게 바꿀 수 있음
>>> p = re.compile('(blue|white|red)')
>>> p.sub('colour','blue socks and red shoes')
'colour socks and colour shoes'
위에 색상을 colore를 바꾸기
sub 메소드의 첫 번째 매개변수는 ‘바꿀 문자열‘이 되고, 두 번째 매개변수는 ‘대상 문자열‘이 됨
바꾸기 횟수를 제어하려면, 세 번째 매개변수로 count 값을 넘기면 됨
===>한번 만 바꾸기
>>> p.sub('colour','blue socks and red shoes',count=1)
'colour socks and red shoes'
===>count를 해서 바꾸기
print(p.sub('colour','blue socks and red shoes',count = 2))
colour socks and colour shoes
print(p.sub('colour','blue socks and red shoes',count = 3))
colour socks and colour shoes
==>sub 메소드와 유사한 subn 메소드
>>> p = re.compile('(blue|white|red)')
>>> p.subn('colour','blue socks and red shoes')
('colour socks and colour shoes', 2)
==>sub 메소드를 사용할 때 참조 구문 사용하기
>>> p = re.compile(r"(?P<name>\w+)\s+(?P<phone>(\d+)[-]\d+[-]\d+)")
>>> print(p.sub("\g<phone> \g<name>","park 010-1234-1234"))
010-1234-1234 park
‘\g<그룹 이름>’을 사용하면 정규식의 그룹 이름을 참조할 수 있게 됨
>>> p = re.compile(r"(?P<name>\w+)\s+(?P<phone>(\d+)[-]\d+[-]\d+)")
>>> print(p.sub("\g<2> \g<1>","park 010-1234-1234"))
010-1234-1234 park
==>sub 메소드의 매개변수로 함수 넣기
>>> def hexrepl(match):
value = int(match.group())
return hex(value)
>>> p = re.compile(r'\d+')
>>> p.sub(hexrepl,'Call 65490 for printing, 49152 for user code.')
'Call 0xffd2 for printing, 0xc000 for user code.'
=>Greedy vs Non-Greedy
#print(re.match('<.*>', s).span())
#<. 문한 >
#*->? ?표를 0아니면 1번 나오게 하라
>>> s = '<html><head><title>Title</title>'
>>> len(s)
32
>>> print(re.match('<.*>',s).span())
(0, 32)
>>> print(re.match('<.*>',s).group())
<html><head><title>Title</title>
‘<.*>’ 정규식의 매치 결과로 * 메타 문자는 탐욕스러워서(Greedy) 최대한의 문자열을 모두 소비해 버림
>>> print(re.match('<.*?>',s).group())
<html>
non-greedy 문자인 ?는 *?, +?, ??, {m,n}?와 같이 사용할 수 있음
연습문제
1.
>>> a = "a:b:c:d"
>>> b = a.split(":")
>>> print("#".join(b))
a#b#c#d
2.
>>> a = {'A':90,'B':80}
>>> a['C']
Traceback (most recent call last):
File "<pyshell#77>", line 1, in <module>
a['C']
KeyError: 'C'
===========================>
>>> a = {'A':90,'B':80}
>>> a.get('C',70)
70
3.
>>> a = [1,2,3]
>>> a = a + [4,5]
>>> a
[1, 2, 3, 4, 5]
>>> a = [1,2,3]
>>> a.extend([4,5])
>>> a
[1, 2, 3, 4, 5]
id로 구분한다.
>>> a = [1,2,3]
>>> id(a)
1353827821696
>>> a = a + [4,5]
>>> id(a)
1353827491904
>>> a = [1,2,3]
>>> id(a)
1353827822336
>>> a.extend([4,5])
>>> id(a)
1353827822336
4.
A= [20,55,67,82,45,33,90,87,100,25]
sum = 0
for i in A:
if i >= 50:
sum += i
print(sum)#481
5.
def fibo1(n):
if n == 0 : return 0
elif n == 1: return 1
else:
return fibo1(n-1) +fibo1(n-2)
for i in range(10):
print(fibo1(i))

6.
user_input = input("숫자를 입력하여 주십시요.")
# 65,45,2,3,45,8
user_input = user_input.split(",")
sum = 0
for i in user_input:
sum += int(i)
print(sum)

7.
user_input = int(input("숫자를 입력하여 주십시요."))
for i in range(1,10):
print(i * user_input,end =" ")
8.
f = open("abc.txt",'r')
lines = f.readlines()
f.close()
lines.reverse()
f = open("abc.txt",'w')
for line in lines:
line = line.strip()
f.write(line)
f.write('\n')
f.close()

9.
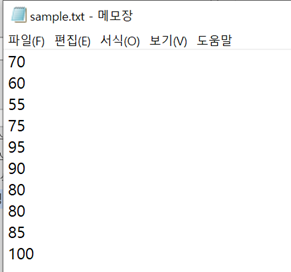
f = open("sample.txt",'r')
lines = f.readlines()
f.close()
f = open("result.txt",'w')
sum = 0
for i in lines:
sum += int(i)
f.write(str(sum/len(lines)))
f.close()

10.
>>> class Calculator():
def __init__(self,numberlist):
self.numberlist = numberlist
def sum(self):
result = 0
for num in self.numberlist:
result += num
return result
def avg(self):
total = self.sum()
return total/len(self.numberlist)
>>> cal1 = Calculator([1,2,3,4,5])
>>> cal1.sum()
15
>>> cal1.avg()
3.0
>>> cal2 = Calculator([6,7,8,9,10])
>>> cal2.sum()
40
>>> cal2.avg()
8.0
11.
>>> import sys
>>> sys.path.append("c:\doit")
>>> import mymod
12.
>>> result = 0
>>> try:
[1,2,3][3]
"a"+1
4 / 0
except TypeError:
result += 1
except ZeroDivisionError:
result += 1
except IndexError:
result += 1
finally:
result += 4
>>> print(result)
5
13.
>>> a = "4546793"
>>> import re
>>> pat = re.compile("(\d{3})(\d{2})(\d{1})(\d{1})")
>>> print(pat.sub("\g<1>-*\g<2>-\g<3>-\g<4>",a))
454-*67-9-3
14.
문자열 압축하기
>>> def compress_string(s):
_c = ""
cnt = 0
result =""
for c in s:
if c!= _c:
_c = c
if cnt :result += str(cnt)
result += c
cnt = 1
else:
cnt +=1
if cnt : result += str(cnt)
return result
>>> print(compress_string("aaabbcccccca"))
a3b2c6a1
15.
>>> def chkDupNum(s):
result = []
for num in s:
if num not in result:
result.append(s)
else:
return false
return len(result) == 10
>>> print(chkDupNum("0123456789"))
True
>>> print(chkDupNum("01234"))
False
>>> print(chkDupNum("01234567890"))
False
>>> print(chkDupNum("6789012345"))
True
>>> print(chkDupNum("012322456789"))
False
16.

>>> dic = {".-":"A","-...":"B","-.-.":"C","-..":"D",".":"E","..-.":"F","--.":"G"
,"....":"H","I":"..",".---":"J","-.-":"K",".-..":"L","--":"M","-.":"N"
,"---":"O",".--.":"P","--.-":"Q",".-.":"R","...":"S","-":"T"
,"..-":"U","...-":"V",".--":"W","-..-":"X","-.--":"Y","--..":"Z"}
>>> def morse(src):
result = []
for word in src.split(" "):
for char in word.split(" "):
result.append(dic[char])
result.append(" ")
return "".join(result)
>>> print(morse(".... ... .-.. . . .--. ... . .- .-.. -.--"))
H S L E E P S E A L Y
17.
>>> import re
>>> p = re.compile("a[.]{3,}b")
>>> print(p.search("acccb"))
None
>>> print(p.search("a....b"))
<re.Match object; span=(0, 6), match='a....b'>
>>> print(p.search("aaab"))
None
>>> print(p.search("a.cccb"))
None
18.
>>> import re
>>> p = re.compile("[a-z]+")
>>> m = p.search("5 python")
>>> m.start()+m.end()
10
>>> m.start()
2
>>> m.end()
8
19.
>>> data = """
park 010-9999-9988
kim 010-9909-7789
lee 010-8789-7768
"""
>>> import re
>>> p = re.compile("(\d{3}[-]+\d{4}[-])\d{4}")
>>> print(p.sub(r"\g<1>-####",data))
park 010-9999--####
kim 010-9909--####
lee 010-8789--####
20.
>>> import re
>>> pat = re.compile(".*[@].*[.](?=com$|net$).*$")
>>> print(pat.match("pankey@gmail.com"))
<re.Match object; span=(0, 16), match='pankey@gmail.com'>
>>> print(pat.match("kim@daum.com"))
<re.Match object; span=(0, 12), match='kim@daum.com'>
>>> print(pat.match("lee@myhome.com"))
<re.Match object; span=(0, 14), match='lee@myhome.com'>