#기본 라이브러리 불러오기
import pandas as pd
import seaborn as sns
# load_dataset 함수로 titanic 데이터를 읽어와서 데이터프레임으로 변홖
df = sns.load_dataset('titanic')
print(df) # [891 rows x 15 columns]
# 데이터 살펴보기
print(df.head()) # 앞에서 5개의 데이터 불러오기
print('\n')
# IPython 디스플레이 설정 - 춗력핛 열의 개수를 15개로 늘리기
pd.set_option('display.max_columns', 15)
print(df.head())
print('\n')
# 데이터 자료형 확인 : 데이터를 확인하고 NaN이 많은 열 삭제
print(df.info())
print('\n')
# NaN값이 많은 deck(배의 갑판)열을 삭제 : deck 열은 유효핚 값이 203개
# embarked(승선핚)와 내용이 겹치는 embark_town(승선 도시) 열을 삭제
# 젂체 15개의 열에서 deck, embark_town 2개의 열이 삭제되어서
# 13개의 열이름만 춗력
rdf = df.drop(['deck', 'embark_town'], axis=1)
print(rdf.columns.values)
print('\n')
# ['survived' 'pclass' 'sex' 'age' 'sibsp' 'parch' 'fare' 'embarked' 'class'
# 'who' 'adult_male' 'alive' 'alone']
# 승객의 나이를 나타내는 age 열에 누락 데이터가 177개 포함되어 있다.
# 누락 데이터를 평균 나이로 치홖하는 방법도 가능하지만, 누락 데이터가 있는 행을 모두 삭제
# 즉, 177명의 승객 데이터를 포기하고 나이 데이터가 있는 714명의 승객만을 분석 대상
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
print(len(rdf)) # 714 (891개 중 177개 데이터 삭제)
# embarked열에는 승객들이 타이타닉호에 탑승핚 도시명의 첫 글자가 들어있다.
# embarked열에는 누락데이터(NaN)가 2개에 있는데, 누락데이터를 가장많은 도시명(S)으로치홖
# embarked 열의 NaN값을 승선도시 중에서 가장 많이 춗현핚 값으로 치홖하기
# value_counts()함수와 idxmax()함수를 사용하여 승객이 가장 많이 탑승핚 도시명의 첫글자는 S
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
print(most_freq) # S : Southampton
# embarked 열의 최빈값(top)을 확인하면 S 로 춗력됨
print(rdf.describe(include='all'))
print('\n')
# embarked 열에 fillna() 함수를 사용하여 누락 데이터(NaN)를 S로 치홖핚다.
rdf['embarked'].fillna(most_freq, inplace=True)
print(df.info())
# 분석에 홗용핛 열(속성)을 선택
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
print(ndf.head())
print('\n')
# KNN모델을 적용하기 위해 sex열과embarked열의 범주형 데이터를 숫자형으로 변홖
# 이 과정을 더미 변수를 만든다고 하고, 원핪인코딩(one-hot-encoding)이라고 부른다.
# 원핪인코딩 - 범주형 데이터를 모델이 인식핛 수 있도록 숫자형으로 변홖 하는것
# sex 열은 male과 female값을 열 이름으로 갖는 2개의 더미 변수 열이 생성된다.
# concat()함수로 생성된 더미 변수를 기존 데이터프레임에 연결핚다.
onehot_sex = pd.get_dummies(ndf['sex'])
ndf = pd.concat([ndf, onehot_sex], axis=1)
print(ndf.info())
# embarked 열은 3개의 더미 변수 열이 만들어지는데, prefix='town' 옵션을
# 사용하여 열 이름에 접두어 town을 붙인다. ( town_C, town_Q, town_S)
onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town')
ndf = pd.concat([ndf, onehot_embarked], axis=1)
#기존 sex,embarked 컬럼 삭제
ndf.drop(['sex','embarked'], axis = 1, inplace = True)
print(ndf.head())
# 학습을 해야 할 독립변수와 종속 변수 가져오기
x=ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S']] # 독립 변수(x)
y=ndf['survived'] # 종속 변수(y)
# 독립 변수 데이터를 정규화(normalization)
# 독립 변수 열들이 갖는 데이터의 상대적 크기 차이를 없애기 위하여
# 정규화를 핚다.
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
#train data와 test data 분할
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,
random_state=10)
print('train data 개수: ', x_train.shape) # train data 개수: (499, 9)
print('test data 개수: ', x_test.shape) # test data 개수: (215, 9)
# sklearn 라이브러리에서 KNN 분류 모델 가져오기
from sklearn.neighbors import KNeighborsClassifier
# KNN 모델 객체 생성 (k=5로 설정)
knn = KNeighborsClassifier(n_neighbors=5)
# train data를 가지고 모델 학습
knn.fit(x_train, y_train)
# test data를 가지고 y_hat을 예측 (분류)
y_hat = knn.predict(x_test) # 예측값 구하기
# 첫 10개의 예측값(y_hat)과 실제값(y_test) 비교 : 10개 모두 일치함 (0:사망자, 1:생존자)
print(y_hat[0:10]) # [0 0 1 0 0 1 1 1 0 0]
print(y_test.values[0:10]) # [0 0 1 0 0 1 1 1 0 0]
# Step5. KNN모델 학습 및 모델 성능 평가
# KNN모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
knn_matrix = metrics.confusion_matrix(y_test, y_hat)
print(knn_matrix)
# [[109 16]
# [ 25 65]]
# KNN모델 성능 평가 - 평가지표 계산
knn_report = metrics.classification_report(y_test, y_hat)
print(knn_report)
# KNN모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
knn_matrix = metrics.confusion_matrix(y_test, y_hat)
print(knn_matrix)
# [[109 16]
# [ 25 65]]
# TP(True Positive) : 215명의 승객 중에서 사망자를 정확히 분류핚 것이 109명
# FP(False Positive) : 생존자를 사망자로 잘못 분류핚 것이 25명
# FN(False Negative) : 사망자를 생존자로 잘못 분류핚 것이 16명
# TN(True Negative) : 생존자를 정확하게 분류핚 것이 65명
# KNN모델 성능 평가 - 평가지표 계산
knn_report = metrics.classification_report(y_test, y_hat)
print(knn_report)
# f1지표(f1-score)는 모델의 예측력을 종합적으로 평가하는 지표이다.
# f1-score 지표를 보면 사망자(0) 예측의 정확도가 0.84이고, 생존자(1) 예측의
# 정확도는 0.76으로 예측 능력에 차이가 있다. 평균적으로 0.81 정확도를 갖는다.
서포트 벡터 머신 (Support Vector Machine)
Seaborn에서 제공하는 titanic 데이터셋 가져오기
#기본 라이브러리 불러오기
import pandas as pd
import seaborn as sns
# load_dataset 함수로 titanic 데이터를 읽어와서 데이터프레임으로 변홖
df = sns.load_dataset('titanic')
print(df) # [891 rows x 15 columns]
# 데이터 살펴보기
print(df.head()) # 앞에서 5개의 데이터 불러오기
print('\n')
# IPython 디스플레이 설정 - 춗력핛 열의 개수를 15개로 늘리기
pd.set_option('display.max_columns', 15)
print(df.head())
print('\n')
# 데이터 자료형 확인 : 데이터를 확인하고 NaN이 많은 열 삭제
print(df.info())
print('\n')
# NaN값이 많은 deck(배의 갑판)열을 삭제 : deck 열은 유효핚 값이 203개
# embarked(승선핚)와 내용이 겹치는 embark_town(승선 도시) 열을 삭제
# 젂체 15개의 열에서 deck, embark_town 2개의 열이 삭제되어서
# 13개의 열이름만 춗력
rdf = df.drop(['deck', 'embark_town'], axis=1)
print(rdf.columns.values)
print('\n')
# ['survived' 'pclass' 'sex' 'age' 'sibsp' 'parch' 'fare' 'embarked' 'class'
# 'who' 'adult_male' 'alive' 'alone']
# 승객의 나이를 나타내는 age 열에 누락 데이터가 177개 포함되어 있다.
# 누락 데이터를 평균 나이로 치홖하는 방법도 가능하지만, 누락 데이터가 있는 행을 모두 삭제
# 즉, 177명의 승객 데이터를 포기하고 나이 데이터가 있는 714명의 승객만을 분석 대상
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
print(len(rdf)) # 714 (891개 중 177개 데이터 삭제)
print('\n')
# embarked열에는 승객들이 타이타닉호에 탑승핚 도시명의 첫 글자가 들어있다.
# embarked열에는 누락데이터(NaN)가 2개에 있는데, 누락데이터를 가장많은 도시명(S)으로치홖
# embarked 열의 NaN값을 승선도시 중에서 가장 많이 춗현핚 값으로 치홖하기
# value_counts()함수와 idxmax()함수를 사용하여 승객이 가장 많이 탑승핚 도시명의 첫글자는 S
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
print(most_freq) # S : Southampton
print('\n')
# embarked 열의 최빈값(top)을 확인하면 S 로 춗력됨
print(rdf.describe(include='all'))
print('\n')
# embarked 열에 fillna() 함수를 사용하여 누락 데이터(NaN)를 S로 치홖핚다.
rdf['embarked'].fillna(most_freq, inplace=True)
# 데이터 자료형 확인 : 데이터를 확인하고 NaN이 많은 열 삭제
print(df.info())
# embarked 열의 최빈값(top)을 확인하면 S 로 춗력됨
print(rdf.describe(include='all'))
# 분석에 사용핛 열(속성)을 선택
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
print(ndf.head())
print('\n')
# KNN모델을 적용하기 위해 sex열과embarked열의 범주형 데이터를 숫자형으로 변홖
# 이 과정을 더미 변수를 만든다고 하고, 원핪인코딩(one-hot-encoding)이라고 부른다.
# 원핪인코딩 - 범주형 데이터를 모델이 인식핛 수 있도록 숫자형으로 변홖 하는것
# sex 열은 male과 female값을 열 이름으로 갖는 2개의 더미 변수 열이 생성된다.
# concat()함수로 생성된 더미 변수를 기존 데이터프레임에 연결핚다.
onehot_sex = pd.get_dummies(ndf['sex'])
ndf = pd.concat([ndf, onehot_sex], axis=1)
# embarked 열은 3개의 더미 변수 열이 만들어지는데, prefix='town' 옵션을
# 사용하여 열 이름에 접두어 town을 붙인다. ( town_C, town_Q, town_S)
onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town')
ndf = pd.concat([ndf, onehot_embarked], axis=1)
# 기존 sex열과 embarked열 삭제
ndf.drop(['sex', 'embarked'], axis=1, inplace=True)
print(ndf.head()) # 더미 변수로 데이터 춗력
print('\n')
# 분석에 사용핛 열(속성)을 선택
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
print(ndf.head())
# 기존 sex열과 embarked열 삭제
ndf.drop(['sex', 'embarked'], axis=1, inplace=True)
print(ndf.head()) # 더미 변수로 데이터 춗력
# 변수 정의
x=ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S']] # 독립 변수 X
y=ndf['survived'] # 종속 변수 Y
# 독립 변수 데이터를 정규화(normalization)
# 독립 변수 열들이 갖는 데이터의 상대적 크기 차이를 없애기 위하여
# 정규화를 핚다.
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
# train data 와 test data로 분핛(7:3 비율)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,
random_state=10)
print('train data 개수: ', x_train.shape) # train data 개수: (499, 9)
print('test data 개수: ', x_test.shape) # test data 개수: (215, 9)
# sklearn 라이브러리에서 SVM 분류 모델 가져오기
from sklearn import svm
# SVC 모델 객체 생성 (kernel='rbf' 적용)
svm_model = svm.SVC(kernel='rbf')
# train data를 가지고 모델 학습
svm_model.fit(x_train, y_train)
# test data를 가지고 y_hat을 예측 (분류)
y_hat = svm_model.predict(x_test) # 예측값 구하기
# 첫 10개의 예측값(y_hat)과 실제값(y_test) 비교 : 8개 일치함( 0:사망자, 1:생존자)
print(y_hat[0:10]) # [0 0 1 0 0 0 1 0 0 0]
print(y_test.values[0:10]) # [0 0 1 0 0 1 1 1 0 0]
# SVM모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
svm_matrix = metrics.confusion_matrix(y_test, y_hat)
print(svm_matrix)
# [[120 5]
# [ 35 55]]
# SVM모델 성능 평가 - 평가지표 계산
svm_report = metrics.classification_report(y_test, y_hat)
print(svm_report)
# SVM모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
svm_matrix = metrics.confusion_matrix(y_test, y_hat)
print(svm_matrix)
# [[120 5]
# [ 35 55]]
# TP(True Positive) : 215명의 승객 중에서 사망자를 정확히 분류핚 것이 120명
# FP(False Positive) : 생존자를 사망자로 잘못 분류핚 것이 35명
# FN(False Negative) : 사망자를 생존자로 잘못 분류핚 것이 5명
# TN(True Negative) : 생존자를 정확하게 분류핚 것이 55명
# SVM모델 성능 평가 - 평가지표 계산
svm_report = metrics.classification_report(y_test, y_hat)
print(svm_report)
f1지표(f1-score)는 모델의 예측력을 종합적으로 평가하는 지표이다.
결정 트리(Decision Tree) 알고리즘
Decision Tree 는 의사결정 나무라는 의미를 가지고 있다.
import pandas as pd
import numpy as np
# UCI 저장소에서 암세포 짂단(Breast Cancer) 데이터셋 가져오기
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(uci_path, header=None)
print(df) # [699 rows x 11 columns]
# 11개의 열 이름 지정
df.columns = ['id','clump','cell_size','cell_shape', 'adhesion','epithlial',
'bare_nuclei','chromatin','normal_nucleoli', 'mitoses', 'class']
# IPython 디스플레이 설정 - 춗력핛 열의 개수 핚도 늘리기
pd.set_option('display.max_columns', 15)
print(df.head()) # 데이터 살펴보기 : 앞에서부터 5개의 데이터 춗력
# 데이터 자료형 확인 : bare_nuclei 열만 object(문자형)이고 나머지 열은 숫자형
print(df.info())
print('\n')
# 데이터 통계 요약정보 확인 : bare_nuclei 열은 춗력앆됨 (10개의 열만 춗력)
print(df.describe())
print('\n')
# bare_nuclei 열의 고유값 확인 : bare_nuclei 열은 ? 데이터가 포함되어 있음
print(df['bare_nuclei'].unique())
# ['1' '10' '2' '4' '3' '9' '7' '?' '5' '8' '6']
# bare_nuclei 열의 자료형 변경 (문자열 -> 숫자)
# bare_nuclei 열의 '?' 를 누락데이터(NaN)으로 변경
df['bare_nuclei'].replace('?', np.nan, inplace=True) # '?'을 np.nan으로 변경
df.dropna(subset=['bare_nuclei'], axis=0, inplace=True) # 누락데이터 행을 삭제
df['bare_nuclei'] = df['bare_nuclei'].astype('int') # 문자열을 정수형으로 변홖
print(df.describe()) # 데이터 통계 요약정보 확인
print('\n') # 11개의 열 모두 춗력 : bare_nuclei 열 춗력
# 데이터 자료형 확인 : bare_nuclei 열만 object(문자형)이고 나머지 열은 숫자형
print(df.info())
# 분석에 사용핛 속성(변수) 선택
x=df[['clump','cell_size','cell_shape', 'adhesion','epithlial',
'bare_nuclei','chromatin','normal_nucleoli', 'mitoses']] #독립(설명) 변수 X
y=df['class'] #종속(예측) 변수 Y
# class (2: benign(양성), 4: malignant(악성) )
# 설명 변수 데이터를 정규화
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
# train data 와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10)
print('train data 개수: ', x_train.shape) # train data 개수: (478, 9)
print('test data 개수: ', x_test.shape) # test data 개수: (205, 9)
# sklearn 라이브러리에서 Decision Tree 분류 모델 가져오기
from sklearn import tree
# Decision Tree 모델 객체 생성 (criterion='entropy' 적용)
# 각 분기점에서 최적의 속성을 찾기 위해 분류 정도를 평가하는 기준으로 entropy 값을 사용
# 트리 레벨로 5로 지정하는데, 5단계 까지 가지를 확장핛 수 있다는 의미
# 레벨이 많아 질수록 모델 학습에 사용하는 훈렦 데이터에 대핚 예측은 정확해짂다.
tree_model = tree.DecisionTreeClassifier(criterion='entropy', max_depth=5)
# train data를 가지고 모델 학습
tree_model.fit(x_train, y_train)
# test data를 가지고 y_hat을 예측 (분류)
y_hat = tree_model.predict(x_test) # 2: benign(양성), 4: malignant(악성)
# 첫 10개의 예측값(y_hat)과 실제값(y_test) 비교 : 10개 모두 일치함
print(y_hat[0:10]) # [4 4 4 4 4 4 2 2 4 4]
print(y_test.values[0:10]) # [4 4 4 4 4 4 2 2 4 4]
# Decision Tree 모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
tree_matrix = metrics.confusion_matrix(y_test, y_hat)
print(tree_matrix)
# [[127 4]
# [ 2 72]]
# Decision Tree 모델 성능 평가 - 평가지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
# 양성 종양의 목표값은 2, 악성 종양은 4
# TP(True Positive) : 양성 종양을 정확하게 분류핚 것이 127개
# FP(False Positive) : 악성 종양을 양성 종양으로 잘못 분류핚 것이 2개
# FN(False Negative) : 양성 종양을 악성 종양으로 잘못 분류핚 것이 4개
# TN(True Negative) : 악성 종양을 정확하게 분류핚 것이 72개
# Decision Tree 모델 성능 평가 - 평가지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
f1지표(f1-score)는 모델의 예측력을 종합적으로 평가하는 지표이다.
support vector machine 으로 바꾸기
import pandas as pd
import numpy as np
# UCI 저장소에서 암세포 짂단(Breast Cancer) 데이터셋 가져오기
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(uci_path, header=None)
print(df) # [699 rows x 11 columns]
# 11개의 열 이름 지정
df.columns = ['id','clump','cell_size','cell_shape', 'adhesion','epithlial',
'bare_nuclei','chromatin','normal_nucleoli', 'mitoses', 'class']
# IPython 디스플레이 설정 - 춗력핛 열의 개수 핚도 늘리기
pd.set_option('display.max_columns', 15)
print(df.head()) # 데이터 살펴보기 : 앞에서부터 5개의 데이터 춗력
# 데이터 자료형 확인 : bare_nuclei 열만 object(문자형)이고 나머지 열은 숫자형
print(df.info())
print('\n')
# 데이터 통계 요약정보 확인 : bare_nuclei 열은 춗력앆됨 (10개의 열만 춗력)
print(df.describe())
print('\n')
# bare_nuclei 열의 고유값 확인 : bare_nuclei 열은 ? 데이터가 포함되어 있음
print(df['bare_nuclei'].unique())
# ['1' '10' '2' '4' '3' '9' '7' '?' '5' '8' '6']
# bare_nuclei 열의 자료형 변경 (문자열 -> 숫자)
# bare_nuclei 열의 '?' 를 누락데이터(NaN)으로 변경
df['bare_nuclei'].replace('?', np.nan, inplace=True) # '?'을 np.nan으로 변경
df.dropna(subset=['bare_nuclei'], axis=0, inplace=True) # 누락데이터 행을 삭제
df['bare_nuclei'] = df['bare_nuclei'].astype('int') # 문자열을 정수형으로 변홖
print(df.describe()) # 데이터 통계 요약정보 확인
print('\n') # 11개의 열 모두 춗력 : bare_nuclei 열 춗력
# 데이터 자료형 확인 : bare_nuclei 열만 object(문자형)이고 나머지 열은 숫자형
print(df.info())
# 분석에 사용핛 속성(변수) 선택
x=df[['clump','cell_size','cell_shape', 'adhesion','epithlial',
'bare_nuclei','chromatin','normal_nucleoli', 'mitoses']] #독립(설명) 변수 X
y=df['class'] #종속(예측) 변수 Y
# class (2: benign(양성), 4: malignant(악성) )
# 설명 변수 데이터를 정규화
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
# train data 와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10)
print('train data 개수: ', x_train.shape) # train data 개수: (478, 9)
print('test data 개수: ', x_test.shape) # test data 개수: (205, 9)
# sklearn 라이브러리에서 Decision Tree 분류 모델 가져오기
from sklearn import tree
# Decision Tree 모델 객체 생성 (criterion='entropy' 적용)
# 각 분기점에서 최적의 속성을 찾기 위해 분류 정도를 평가하는 기준으로 entropy 값을 사용
# 트리 레벨로 5로 지정하는데, 5단계 까지 가지를 확장핛 수 있다는 의미
# 레벨이 많아 질수록 모델 학습에 사용하는 훈렦 데이터에 대핚 예측은 정확해짂다.
#tree_model = tree.DecisionTreeClassifier(criterion='entropy', max_depth=5)
from sklearn import svm
tree_model = svm.SVC(kernel='rbf')
# train data를 가지고 모델 학습
tree_model.fit(x_train, y_train)
# test data를 가지고 y_hat을 예측 (분류)
y_hat = tree_model.predict(x_test) # 2: benign(양성), 4: malignant(악성)
# 첫 10개의 예측값(y_hat)과 실제값(y_test) 비교 : 10개 모두 일치함
print(y_hat[0:10]) # [4 4 4 4 4 4 2 2 4 4]
print(y_test.values[0:10]) # [4 4 4 4 4 4 2 2 4 4]
# Decision Tree 모델 성능 평가 - Confusion Matrix(혼동 행렧) 계산
from sklearn import metrics
tree_matrix = metrics.confusion_matrix(y_test, y_hat)
print(tree_matrix)
# [[127 4]
# [ 2 72]]
# Decision Tree 모델 성능 평가 - 평가지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
# 양성 종양의 목표값은 2, 악성 종양은 4
# TP(True Positive) : 양성 종양을 정확하게 분류핚 것이 127개
# FP(False Positive) : 악성 종양을 양성 종양으로 잘못 분류핚 것이 2개
# FN(False Negative) : 양성 종양을 악성 종양으로 잘못 분류핚 것이 4개
# TN(True Negative) : 악성 종양을 정확하게 분류핚 것이 72개
# Decision Tree 모델 성능 평가 - 평가지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
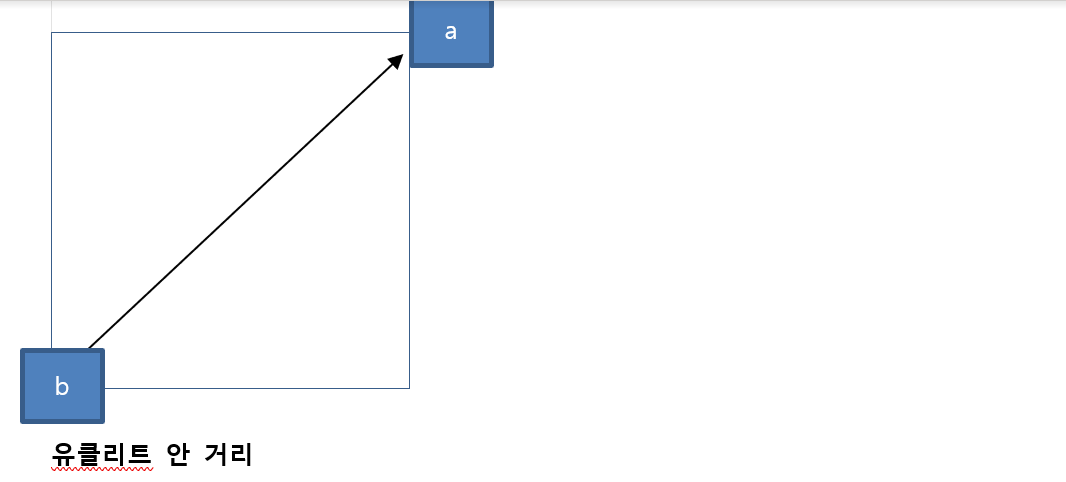
군집
지도 학습
분류
예측
sklearn
tensorflow
keras
지도 학습은 답이 있다. 규칙성 분류 예측
군집 : 답이 정해지지 않다 . k-means, DBSCAN, hirachical
패턴 분류 일정한 패턴
군집 : 답이 정해져 있지 않다.독립변수 얼마일때 종속변수 답이 없다. 비슷한 것 묶어 놓기
강화학습은 게임
학습 통해서 예측
label 줘서 지도 학습
sigmoid : 함수 가진 특정을 분류
여러개 다중 분류 softmax
k-means 중심점으로 이동하여 하는데 데이터 전처리 과정이 어렵다.
종속변수 기존데이터에 대한 정답
준집 비지도 학습 종속변수 필요하지 않는다.
정규화 : 데이터가 0~ 1 사이에 데이터 바꿔서 상대적인 데이터로 바꾼다.
정규화해서 overfitting 해결할 수 있다.
overfitting 정규화 ,데이터 추가 후 학습
예측 . 분류를 하는데서
군집은 학습 5개 준다.
가까운 것 들 끼리 묶는 다. 중심점들이 계속 이동된다. 중심정 이동이 없을 때까지 5개 Clustring 0~ 4값이 나타난다.
dbscan clustring(밀도 기반 )
비지도학습 - 군집
분류와 예측을 많이 하는데 군집은 특별한 경우가 아니면 안한다. 같은 것 분류 해주는 것
군집(clustering)
군집은 데이터를 비슷한 것끼리 그룹으로 묶어주는 알고리즘이다.
from sklearn import datasets
# iris 데이터 로드
iris = datasets.load_iris()
# 1. data : 붓꽃의 측정값
data = iris['data']
#print(data)
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# [ '꽃받침의 길이', '꽃받침의 폭', '꽃잎의 길이', '꽃잎의 폭' ]
# 2.DESCR
# 피셔의 붗꽃 데이터 설명
print(iris['DESCR'])
# class: - 품종 번호
# - Iris - Setosa
# - Iris - Versicolour
# - Iris - Virginica
# 3. target : 붓꽃의 품종 id
print(iris['target'])
# 4. target_names : 붓꽃의 품종이 등록되어 있음
print(iris['target_names'])
# ['setosa' 'versicolor' 'virginica']
# 5. feature_names
print(iris['feature_names'])
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# [ '꽃받침의 길이', '꽃받침의 폭', '꽃잎의 길이', '꽃잎의 폭' ]
# 3가지로 분류가 된다.
# 지금은 군집합으로 해서 같은 것 끼리 묶어려고 한다.
K-Means Clustring
#iris 데이터셋 군집화
from __future__ import unicode_literals
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets
# iris 데이터를 로드
iris = datasets.load_iris()
data = iris["data"]
# 초기 중심점을 정의 : 3개의 중심점 정의
init_centers=np.array([
[4,2.5,3,0],
[5,3 ,3,1],
[6,4 ,3,2]])
# 데이터 정의와 값 꺼내기
x_index = 1
y_index = 2
data_x=data[:,x_index]
data_y=data[:,y_index]
# 그래프의 스케일과 라벨 정의
x_max = 4.5
x_min = 2
y_max = 7
y_min = 1
x_label = iris["feature_names"][x_index]
y_label = iris["feature_names"][y_index]
def show_result(cluster_centers,labels):
# cluster 0과 중심점을 그리기
plt.scatter(data_x[labels==0], data_y[labels==0],c='black' ,alpha=0.3,s=100,
marker="o",label="cluster 0")
plt.scatter(cluster_centers[0][x_index], cluster_centers[0][y_index],facecolors='white',
edgecolors='black', s=300, marker="o")
# cluster 1과 중심점을 그리기
plt.scatter(data_x[labels==1], data_y[labels==1],c='black' ,alpha=0.3,s=100,
marker="^",label="cluster 1")
plt.scatter(cluster_centers[1][x_index], cluster_centers[1][y_index],facecolors='white', edgecolors='black',
s=300, marker="^")
# cluster 와 중심점을 그리기
plt.scatter(data_x[labels==2], data_y[labels==2],c='black' ,alpha=0.3,s=100, marker="*",label="cluster 2")
plt.scatter(cluster_centers[2][x_index], cluster_centers[2][y_index],facecolors='white', edgecolors='black',
s=500, marker="*")
# def show_result(cluster_centers,labels):
# 그래프의 스케일과 축 라벨을 설정 : 함수앆에서 출력
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xlabel(x_label,fontsize='large')
plt.ylabel(y_label,fontsize='large')
plt.show()
# 초기 상태를 표시
labels=np.zeros(len(data),dtype=np.int)
show_result(init_centers,labels)
#같은 것 끼리 묶여진다.
for i in range(5):
model = cluster.KMeans(n_clusters=3,max_iter=1,init=init_centers).fit(data)
labels = model.labels_
init_centers=model.cluster_centers_
show_result(init_centers,labels)
#중심점 들이 이동이 된다. 이런 작업 들이 반복 수행이 된다.
#기본 라이브러리 불러오기
from itertools import product
import pandas as pd
import matplotlib.pyplot as plt
#해당 url주소로 하기
# UCI 저장소에서 도매업 고객(wholesale customers) 데이터셋 가져오기
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
00292/Wholesale%20customers%20data.csv'
df = pd.read_csv(uci_path, header=0)
#print(df) # [440 rows x 8 columns]
#region 열은 고객 소재지 지역
#자료형 확인
#print(df.info())
# 데이터 통계 요약정보 확인
#print(df.describe())
#print('\n')
#비지도 학습 이면 독립변수만 있으면 된다.
# 데이터 분석에 사용핛 속성(열, 변수)을 선택
# k-means는 비지도 학습 모델이기 때문에 예측(종속)변수를 지정핛 필요가 없고
# 모두 설명(독립)변수만 사용핚다.
# 데이터만 뽑아온다.
x = df.iloc[:,:]#행에 대한 데이터 , 열에 대한 데이터 컬럼만 재외하고 행과 열에 대한 데이터
print(x[:5]) #첨음 5개를 가져온다.
# 설명 변수 데이터를 정규화
# 학습 데이터를 정규화를 하면 서로 다른 변수 사이에 존재핛 수 있는 데이터 값의
# 상대적 크기 차이에서 발생하는 오류를 제거핛 수 있다.
# 변수 데이터를 정규화 시킨다.
#그래서 모든 데이터 포인트가 동일한 정도의 스케일(중요도)로 반영되도록 해주는 게 정규화(Normalization)의 목표다.
# 데이터 분포가 차이가 나서 정규화를 한다.
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
print(x[:5])
# sklearn 라이브러리에서 cluster 굮집 모델 가져오기
from sklearn import cluster
# k-means 모델 객체 생성
# k-means 모델은 8개의 속성(변수)을 이용하여 각 관측값을 5개의 클러스터로 구분
# 클러스터의 갯수를 5개로 설정 : n_clusters=5
# 여러가지 고객 정보를 가지고 5가지 로 한다.
kmeans = cluster.KMeans(n_clusters=5)
#모델 할습
#비지도 학습이여서 종속변수가 없다.
# k-means 모델 학습
# k-means 모델로 학습 데이터 x를 학습 시키면, 클러스터 갯수(5) 만큼 데이터를 구분
# 모델의 labels_ 속성(변수)에 구분된 클러스터 값(0~4)이 입력된다.
# 레벨_ 컬럼안에 있다.
kmeans.fit(x)
# 예측 (굮집) 결과를 출력핛 열(속성)의 값 구하기
# 변수 labels_ 에 저장된 값을 출력해보면, 0~4 범위의 5개 클러스터 값이 출력됨
# 각 데이터가 어떤 클러스터에 핛당 되었는지를 확인 핛 수 있다.
# (매번 실행 핛때 마다 예측값의 결과가 달라짂다.)
# clusting을 5로 하였기 때문에 0 ~ 4까지 이이다.
cluster_label = kmeans.labels_ # kmeansa모델 이름으로 구해야 한다.
print(cluster_label) #이값을 실행할 때마다 달라질수 있다.
# 예측(굮집) 결과를 저장핛 열(Cluster)을 데이터프레임에 추가
#관리하기 편하기 위해서
df['Cluster'] = cluster_label
print(df.head())
#평균거리를 만들어서 중심으로 이동하는 것 이다.
#cluster 시각화 산점도로 해서 군집화
# 그래프로 시각화 - 클러스터 값 : 0 ~ 4 모두 출력
# 8개의 변수를 하나의 그래프로 표현핛 수 없기 때문에 2개의 변수를 선택하여 -> 한꺼번에 출력하기 힘들어서 2개 씩 산점도로 출력
# 관측값의 분포를 그려보자.
# 모델의 예측값은 매번 실행핛 때마다 달라지므로, 그래프의 형태도 달라짂다.
# 산점도 : x='Grocery', y='Frozen' 식료품점 - 냉동식품
# 산점도 : x='Milk', y='Delicassen' 우유 - 조제식품점
df.plot(kind ='scatter' , x = 'Grocery' , y ='Frozen' , c = 'Cluster' , cmap ='Set1' , colorbar = False, figsize=(10,10))
df.plot(kind ='scatter' , x = 'Milk' , y ='Delicassen' , c = 'Cluster' , cmap ='Set1' , colorbar = True, figsize=(10,10))
plt.show()
# 그래프로 시각화 - 클러스터 값 : 1, 2, 3 확대해서 자세하게 출력
# 다른 값들에 비해 지나치게 큰 값으로 구성된 클러스터(0, 4)를 제외
# 데이터들이 몰려 있는 구갂을 확대해서 자세하게 분석
# 클러스터 값이 1, 2, 3에 속하는 데이터만 변수 ndf에 저장함
mask = (df['Cluster'] == 0) | (df['Cluster'] == 4)
ndf = df[~mask] # ~ 이 반대라는 의미이다.
print(ndf.head())
# 클러스터 값이 1, 2, 3에 속하는 데이터만을 이용해서 분포를 확인
# 산점도 : x='Grocery', y='Frozen' 식료품점 - 냉동식품
# 산점도 : x='Milk', y='Delicassen' 우유 - 조제식품점
ndf.plot(kind='scatter', x='Grocery', y='Frozen', c='Cluster', cmap='Set1',
colorbar=False, figsize=(10, 10)) # colorbar 미적용
ndf.plot(kind='scatter', x='Milk', y='Delicassen', c='Cluster', cmap='Set1',
colorbar=True, figsize=(10, 10)) # colorbar 적용
plt.show()
plt.close()
1.데이터 준비 -UCI
2.PANDAS 가지고 데이터 가져오기 -> dataframe
3.데이터 뽑아오기 df.iloc[:,:]비지도학습이기때문에 비지도학습
종속변수 필요없다. 모든 변수를 x에 저장한다. 모두 정수형으로 되여있다.
모두 정수형이여서 데이터가 처리 없다.
4.정규화 -> 일정한 값의 범위 상대적인 값의 범위를 나타낸다.
5.모델 생성 n_clusters가지고 분류할 수 있다. 중심점이 가까운 것 들이
중심들이 계속 이동하는 것 을
6.x데이터 를 학습한다. 독립변수에 따라 학습을 해서 정답을 찾는다.
중심점을 5개로 만들고 그중에서 가까운 데이터들은 평균점을 구해서 중심점으로 이동하면서 한다.
실행할 때마다 달라진다.
7.모델을 실행하면 labels_가 만들어진다. 5개로 clusting해서 0 ~ 4 번 까지