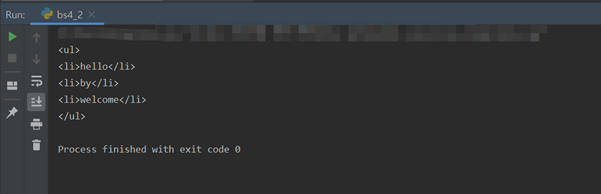
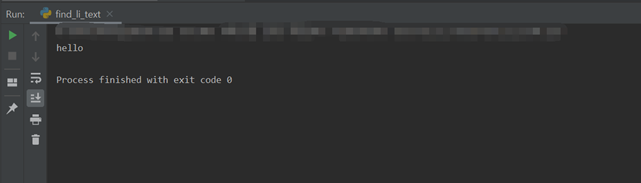
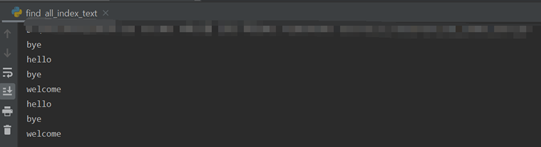
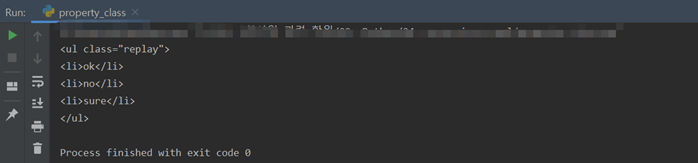
=>웹 브라우저가 HTML이나 XML 문서를 인식하는 방식 : 문서의 구조를 트리 형태로 펼쳐 놓은 것
=>document 객체와 관련된 객체의 집합: body 태그 내에 존재하는 태그
body 태그: document.body
2.document 객체의 프로퍼티 나 메소드
document.body: body 태그
document.innerHTML: body 태그 내의 내용 - HTML을 기재하면 body 태그에 출력
document.write 나 writeln(HTML 내용): innerHTML 속성에 기재한 것과 동일한 효과
document.referrer: 이 URL에 어떻게 접근했는지를 저장하고 있는 속성, 마케팅에서 중요한 속성
=>웹 사이트의 메인 페이지에 어떻게 접속했는지 어떤 페이지에 어떻게 접속했는지를 아는 것은 웹 로그 분석에서 가장 중요한 이슈 중의 하나
이러한 데이터를 수집해서 대시보드에 출력할 수 있도록 해주는 솔루션 중의 하나가 구글 애널리틱스입니다.
3.document 객체를 이용한 문서 객체(태그) 가져오기
document.getElementById(id): id를 가진 객체 1개를 리턴 - 가장 권장
document.getElementsByName(name): name을 가진 객체를 배열로 리턴
document.getElementsByTagName(tag): tag을 가진 객체를 배열로 리턴
document.getElementsByClassName(class): class를 가진 객체를 배열로 리턴
document.폼이름.요소이름 으로 폼의 요소에 접근 - 최근에는 권장하지 않음
document.getElementById(select 의 id).options[index]를 이용해서 select의 각 옵션에 접근할 수 있고 document.getElementById(select 의 id).options[document.getElementById(select 의 id).selectedIndex]
=>최근의 html을 구현할 때 테이블에 출력할 수 있는 개수를 선택하도록 하는 경우가 많습니다.
select에서 선택한 데이터를 찾아올 수 있어야 합니다.
4.DOM 객체의 속성 사용
1)속성 변경
DOM객체.속성이름 = 값;
=>img 태그의 이미지 파일 경로 변경
img객체.src = "이미지 파일 경로";
2)스타일시트 값 변경
DOM객체.style.속성이름 = 값;
3)태그 내용 변경
DOM객체.innerHTML = 값;
4)폼의 입력 객체들의 값을 변경하거나 가져올 때는 value 속성 이용
DOM객체.value
5)body 태그의 내용을 자바스크립트에서 수정할 때는 태그의 내용이 먼저 나오고 스크립트가 나와야 합니다.
스타일시트는 body에 내용을 전부 읽고 화면에 출력할 때 적용되기 때문에 style은 body 태그의 내용이 나오기 전이나 후 상관이 없습니다.
**DOM 객체의 이벤트 처리
1.event
=>사용자나 시스템이 다른 것에 영향을 미치는 사건
=>input 객체 안에서 사용자가 키보드를 누르는 것 등
2.javascript 의 이벤트
=>마우스 이벤트
=>키보드 이벤트
=>DOM 객체 관련 이벤트
=>기타 이벤트
3.이벤트 처리 방식
1)인라인 방식
<태그 on이벤트이름="이벤트 처리 내용"></태그>
2)스크립트 안에서 작성 - 고전적 이벤트 처리
DOM객체.on이벤트이름 = function(매개변수){
이벤트 처리 내용;
}
3)스크립트 안에서 작성 - 표준 이벤트 모델
DOM객체.addEventListener("이벤트이름", function(매개변수){
이벤트 처리 내용;
});
<body>
<span id="disp">텍스트</span>
<!-- 인라인 이벤트 모델: 태그 안에서 이벤트 처리
태그에 스크립트 코드가 알아보기가 어렵고(유지보수가 어려움) 길게 작성하기가 어려움 -->
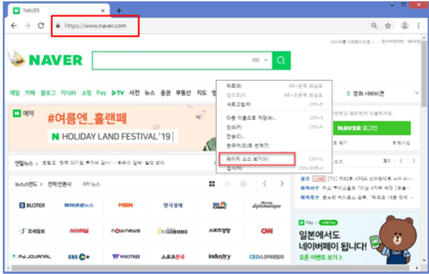
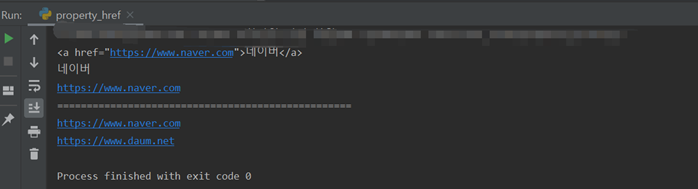
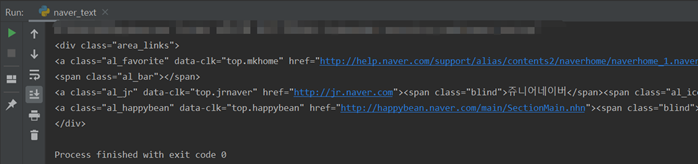
href속성의 속성 값인 네이버의 주소https://www.naver.com/을 뽑기 위해서는 atag[‘href’] 이렇게 대괄호 안에 ‘를 붙인 속성을 넣어주면 ‘속성값’을 뽑아낼 수 있음.
a태그에서 대괄호 안에 'href‘를 붙인 속성을 넣어주면 속성값을 뽑아 냄
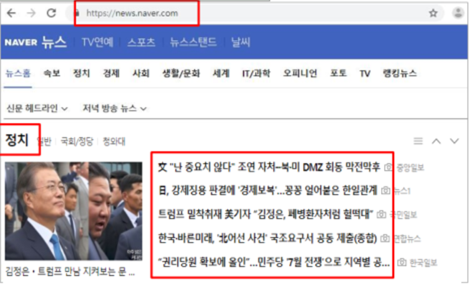
4. 네이버에서 특정 글자 추출하기
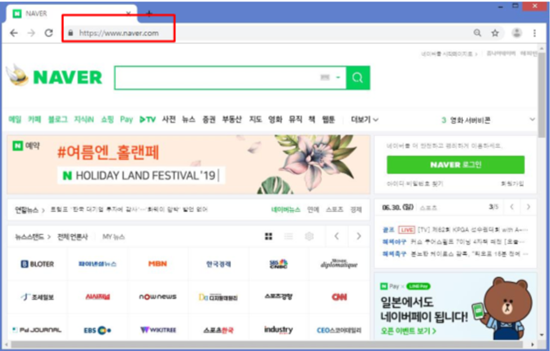
네이버 첫 페이지에서 맨 오른쪽 위에 있는 ‘네이버를 시작페이지로‘라는 단어 두 개만 뽑아보기
=> urllib로 네이버 첫 페이지 데이터 받아오기
웹에서 데이터를 받아오려면 request라는 요청을 보내서 받아와야 함.
파이썬에서 웹의 특정 주소로 요청을 보내는 기능은 urllib.request의 urlopen() 이라는 함수를 사용함.
# naver_text.py
import bs4 import urllib.request
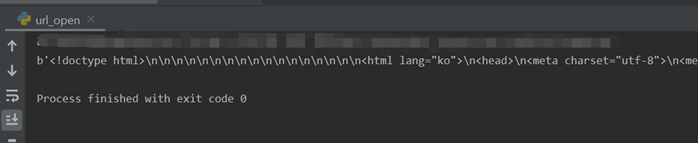
url = "https://www.naver.com" html = urllib.request.urlopen(url) #html이라는 변수 안에 텍스트 형식으로 네이버 첫 #페이지를 호출한 데이터가 문자열 형태로 들어감 print(html.read())
결과:
네이버 첫 페이지를 받아오면, b’<!doctype html> 시작해서 </html>로 끝나는 데이터가 받아와 짐.
=>뷰티풀솝에 데이터 넣기
urlopen() 이라는 함수를 이용해 받아온 데이터를 파싱하기 위해서는 뷰티풀솝에 데이터를 넣어서 파이썬에서 가공할 수 있는 형태로 만들어 주어야 함.
import bs4 import urllib.request
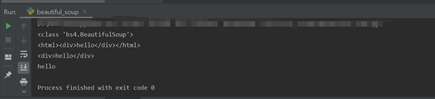
url = "https://www.naver.com" html = urllib.request.urlopen(url) #html이라는 변수 안에 텍스트 형식으로 네이버 첫 #페이지를 호출한 데이터가 문자열 형태로 들어감 #print(html.read()) bs_obj = bs4.BeautifulSoup(html,"html.parser") print(bs_obj)
결과:
bs_obj = bs4.BeautifulSoup(html, "html.parser")
.BeautifulSoup(<받은텍스트>, <텍스트를 파싱할 파서>)에는 총 2가지가 들어감.
받은 텍스트 : 웹에서 받은 텍스트
텍스트를 파싱할 파서 : 웹 문서는 대부분 HTML로 되어 있어서 “html.parser”를 사용
- parser(파서)는 데이터를 뽑아내는(파싱) 프로그램임.
- 파이썬이 HTML 형식으로 인식하라는 뜻임.
- “html.parser”를 가장 많이 사용하며, “lxml”과 “xml” 등도 있음.
=>뷰티풀솝으로 필요한 부분 뽑아내기
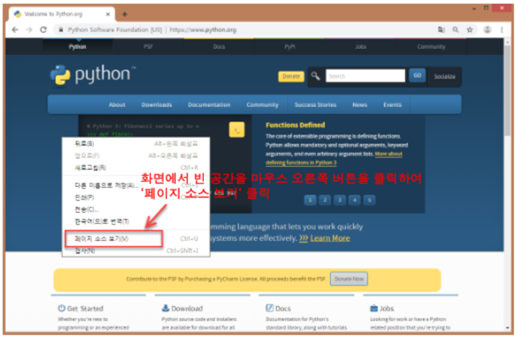
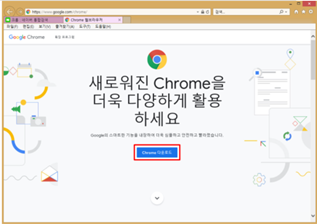
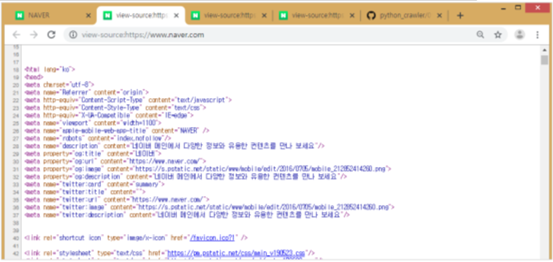
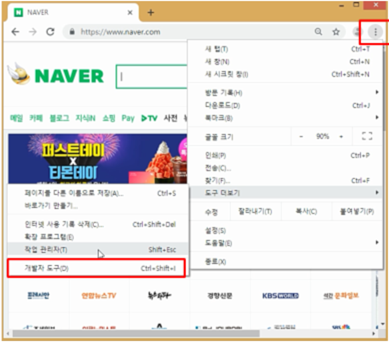
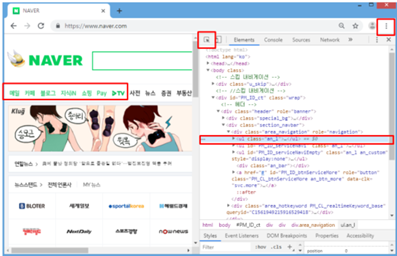
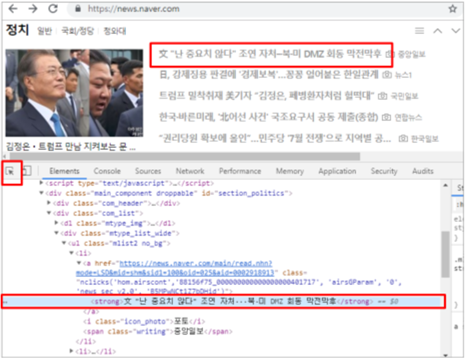
원하는 데이터 HTML상에 어디에 있는지 찾기 위해서는 구글 크롬의 ‘개발자 도구’를 이용함.
크롬을 켜고 우측 상단에 ···버튼을 눌러서 [도구 더보기 → 개발자 도구]
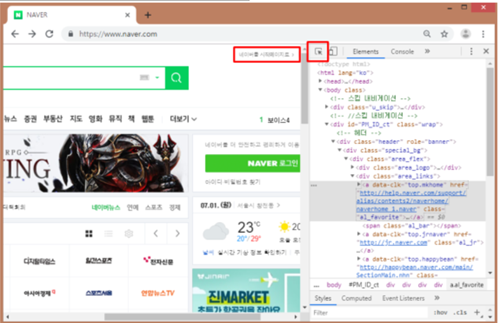
개발자 도구에서 왼쪽 위의 화살표 아이콘을 누르면 색이 파란색으로 바뀌고, 마우스를 움직여 원하는 위치를 클릭하면 소스코드에서 해당부분을 알려줌.
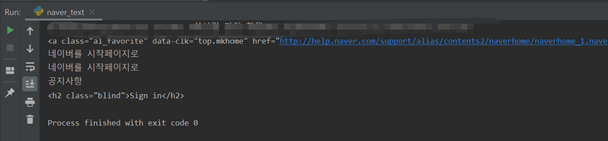
‘네이버를 시작페이지로’ 버튼을 마우스로 찾은 후에 클릭하면, HTML 소스코드에서 어떤 부분인지 표시를 해줌.
‘네이버를 시작페이지로’는 <a>라는 태그 안에 텍스트가 들어 있는 형태임.
• <a>네이버를 시작페이지로<span></span></a>
HTML 코드를 보면, <div>라는 태그 안에 <a></a>가 들어 있는 구조임.
div 태그 안에 class=“area_links” 부분은 클래스를 가지고 파이썬의 뷰티풀솝 라이브러리를 이용해 데이터를 뽑아낼 수 있기 때문에 매우 중요함.
<div class=“area_links”></div> 이 영역만 추출해보도록 하겠음.
import bs4 import urllib.request
url = "https://www.naver.com" html = urllib.request.urlopen(url) #html이라는 변수 안에 텍스트 형식으로 네이버 첫 #페이지를 호출한 데이터가 문자열 형태로 들어감 #print(html.read()) bs_obj = bs4.BeautifulSoup(html,"html.parser")# bs_obj에는 전체 소스가 들어 있음 #print(bs_obj) top_right = bs_obj.find("div",{"class":"area_links"}) #div 태그 중에서 class가 “area_links”로 되어있는 div를 찾으라는 명령 print(top_right)
• bs_obj.find(“div“) 명령어는 전체에서 가장 처음 나타나는 <div>태그를 뽑으라는 명령
• “div”옆에 ,(콤마)를 찍고 {“class”:”area_links”}를 추가하면, div 태그 중에서 class가 “area_links”로 되어있는 div를 찾으라는 명령
이제 필요한 ‘네이버를 시작페이지로‘ 글자만 뽑아보겠음.
import bs4 import urllib.request
url = "https://www.naver.com" html = urllib.request.urlopen(url) #html이라는 변수 안에 텍스트 형식으로 네이버 첫 #페이지를 호출한 데이터가 문자열 형태로 들어감 #print(html.read()) bs_obj = bs4.BeautifulSoup(html,"html.parser")# bs_obj에는 전체 소스가 들어 있음 #print(bs_obj) top_right = bs_obj.find("div",{"class":"area_links"}) #div 태그 중에서class가 “area_links”로 되어있는 div를 찾으라는 명령 #print(top_right) first_a = top_right.find("a")#첫 번째 나오는 a태그를 찾음 print(first_a)# a태그 안에 있는 text만 뽑아냄
결과:
=>공지사항 등 기타 뽑아내기
import bs4 import urllib.request
url = "https://www.naver.com" html = urllib.request.urlopen(url) #html이라는 변수 안에 텍스트 형식으로 네이버 첫 #페이지를 호출한 데이터가 문자열 형태로 들어감 #print(html.read()) bs_obj = bs4.BeautifulSoup(html,"html.parser")# bs_obj에는 전체 소스가 들어 있음 #print(bs_obj) top_right = bs_obj.find("div",{"class":"area_links"}) #div 태그 중에서class가 “area_links”로 되어있는 div를 찾으라는 명령 #print(top_right) first_a = top_right.find("a")#첫 번째 나오는 a태그를 찾음 print(first_a)# a태그 안에 있는 text만 뽑아냄 print(first_a.text)
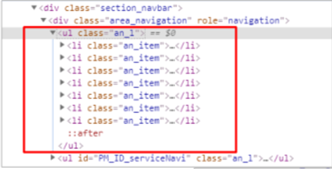
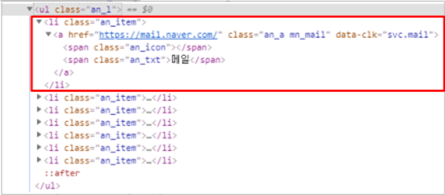
bs_obj = bs4.BeautifulSoup(html,"html.parser") ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) for li in ul: print(li)
결과:
=> .findAll( )로 li만 뽑아내기
.findAll( )은 조건에 해당하는 모든 것들을 [ ]리스트 안으로 추출해주는 함수임.
반복문 for를 이용해도 되지만, 중간에 빈칸이 뽑히는 경우가 있어서 .findAll( )을 써서 한 번 더 뽑아 주는 게 좋음.
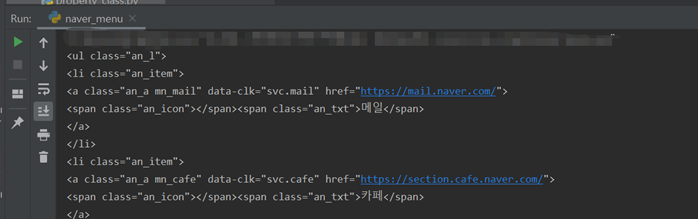
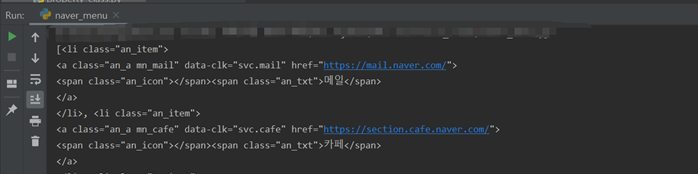
bs_obj = bs4.BeautifulSoup(html,"html.parser") ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) #for li in ul: #print(li) lis = ul.findAll("li")# ul 안에 있는 모든 li를 찾으라는 명령 print(lis)
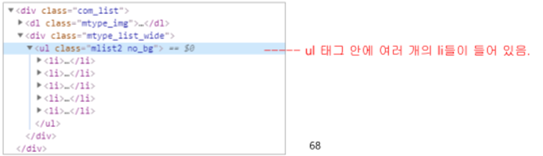
----- [ ]리스트 안에 <li></li>가 여러 개 들어 있으며, 콤마(,)로 구분된 형태
bs_obj = bs4.BeautifulSoup(html,"html.parser") ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) #for li in ul: #print(li) lis = ul.findAll("li")# ul 안에 있는 모든 li를 찾으라는 명령 # ul를 바로 for문을 사용하여 출력하면 중간에 빈칸이 뽑히는 경우가 있음 #print(lis) for li in lis: print(li)# lis 안에 있는 li들을 하나씩 꺼내서 출력
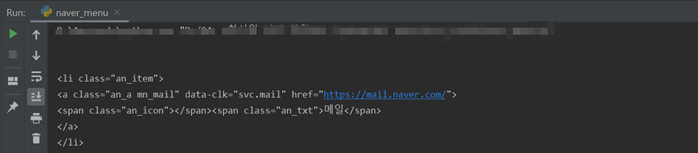
bs_obj = bs4.BeautifulSoup(html,"html.parser") ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) #for li in ul: #print(li) lis = ul.findAll("li")# ul 안에 있는 모든 li를 찾으라는 명령 # ul를 바로 for문을 사용하여 출력하면 중간에 빈칸이 뽑히는 경우가 있음 #print(lis) for li in lis: #print(li)# lis 안에 있는 li들을 하나씩 꺼내서 출력 a_tag = li.find("a") # li안에 있는 a태그를 뽑아서 a_tag라는 변수에 넣으라는 명령(점점 세밀하게 필요한 내용에 접근 ) print(a_tag)
결과:
=> span인 것 중에 an_txt인 class 뽑아내기
<a>태그 안에 <span>이 두 개가 있으므로, 태그인 span과 클래스인 an_txt 두 조건으로 추출해야 함.
bs_obj = bs4.BeautifulSoup(html,"html.parser") ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) #for li in ul: #print(li) lis = ul.findAll("li")# ul 안에 있는 모든 li를 찾으라는 명령 # ul를 바로 for문을 사용하여 출력하면 중간에 빈칸이 뽑히는 경우가 있음 #print(lis) for li in lis: #print(li)# lis 안에 있는 li들을 하나씩 꺼내서 출력 a_tag = li.find("a") # li안에 있는 a태그를 뽑아서 a_tag라는 변수에 넣으라는 명령(점점 세밀하게 필요한 내용에 접근 ) #print(a_tag) span = a_tag.find("span",{"class":"an_txt"}) # span 태그 중에서 an_txt 클래스를 가진것만 뽑으라는 명령 print(span)
결과:
=>Text 뽑아내기
<span> 태그가 제외된, ‘메일’만 들어 있는 순수한 텍스트만 뽑아내기
import bs4 import urllib.request
url = "https://www.naver.com" html = urllib.request.urlopen(url)# html이라는 변수 안에는 웹에서 받은 텍스트가 들어감
bs_obj = bs4.BeautifulSoup(html,"html.parser") #bs4.BeautifulSoup() 에 웹에서 받은 텍스트를 #넣으면, 파이썬에서 가공할 수 있는 html 형태의 #텍스트가 bs_obj에 들어감 ul = bs_obj.find("ul",{"class":"an_l"})# ul 태그 중에서 class가 an_l인 ul을 찾음 #print(ul) #for li in ul: #print(li) lis = ul.findAll("li")# ul 안에 있는 모든 li를 찾으라는 명령 # ul를 바로 for문을 사용하여 출력하면 중간에 빈칸이 뽑히는 경우가 있음 #print(lis) for li in lis: #print(li)# lis 안에 있는 li들을 하나씩 꺼내서 출력 a_tag = li.find("a") # li안에 있는 a태그를 뽑아서 a_tag라는 변수에 넣으라는 명령(점점 세밀하게 필요한 내용에 접근 ) #print(a_tag) span = a_tag.find("span",{"class":"an_txt"}) # span 태그 중에서 an_txt 클래스를 가진것만 뽑으라는 명령 #print(span) print(span.text)# span 태그에서 text만 뽑아내는 부분
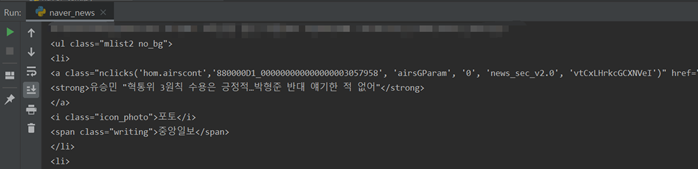
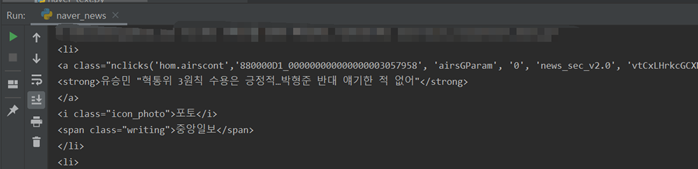
bs_obj = bs4.BeautifulSoup(html, "html.parser") #print(bs_obj) mlist2_no_bg = bs_obj.find("ul", {"class": "mlist2 no_bg"}) #bs_obj에서 class가 ‘mlist2 no_bg’ 인 ul 태그를 찾음 #print(mlist2_no_bg) lis = mlist2_no_bg.findAll("li") #lis 변수를 선언하고, ‘mlist2 no_bg’ 에서 li 태그들을 #리스트[ ] 형태로 담으라는 명령 for li in lis:# for 문을 이용해 lis에 있는 li들을 하나씩 꺼내서 출력 print(li)
bs_obj = bs4.BeautifulSoup(html, "html.parser") #print(bs_obj) mlist2_no_bg = bs_obj.find("ul", {"class": "mlist2 no_bg"}) #bs_obj에서 class가 ‘mlist2 no_bg’ 인 ul 태그를 찾음 #print(mlist2_no_bg) lis = mlist2_no_bg.findAll("li") #lis 변수를 선언하고, ‘mlist2 no_bg’ 에서 li 태그들을 #리스트[ ] 형태로 담으라는 명령 for li in lis:# for 문을 이용해 lis에 있는 li들을 하나씩 꺼내서 출력 #print(li) strong = li.find("strong") print(strong)
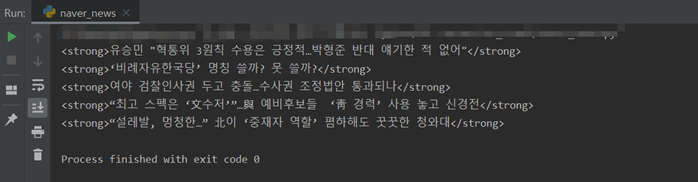
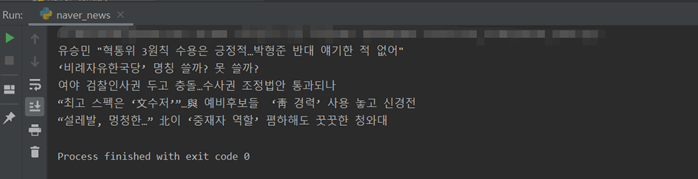
bs_obj = bs4.BeautifulSoup(html, "html.parser") #print(bs_obj) mlist2_no_bg = bs_obj.find("ul", {"class": "mlist2 no_bg"}) #bs_obj에서 class가 ‘mlist2 no_bg’ 인 ul 태그를 찾음 #print(mlist2_no_bg) lis = mlist2_no_bg.findAll("li") #lis 변수를 선언하고, ‘mlist2 no_bg’ 에서 li 태그들을 #리스트[ ] 형태로 담으라는 명령 for li in lis:# for 문을 이용해 lis에 있는 li들을 하나씩 꺼내서 출력 #print(li) strong = li.find("strong") #print(strong) print(strong.text)
결과:
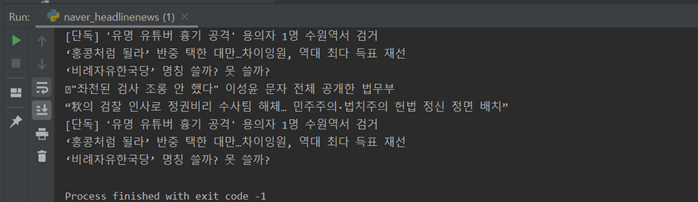
=>네이버 헤드라인 뉴스
#naver_headlinenews.py import urllib.request import bs4 import time import os while True: url = "https://news.naver.com/" html = urllib.request.urlopen(url) bs_obj = bs4.BeautifulSoup(html, "html.parser")
ul = bs_obj.find("ul", {"class": "hdline_article_list"}) div = ul.findAll("div", {"class": "hdline_article_tit"})
#print(lis) for i in range(0, len(div)): a_tag = div[i].find("a") print(a_tag.text.strip())
bs_obj = bs4.BeautifulSoup(html, "html.parser") ul = bs_obj.find("ul", {"id": "PM_ID_serviceNavi"}) lis = ul.findAll("li") #print(lis) for i in range(0, len(lis)): a_tag = lis[i].find("a") span_tag = a_tag.find("span", {"class": "an_txt"}) print(span_tag.text)
결과:
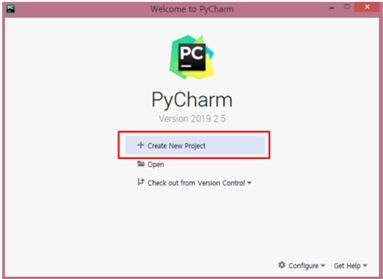
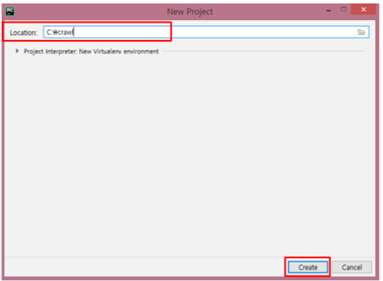
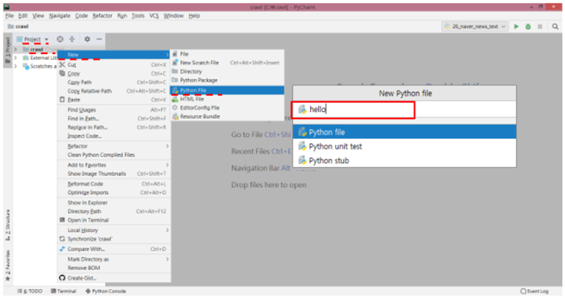
프로젝트 명 : 뉴스 빅데이터 분석 시스템 구축
1.데이터베이스 구축
데이터베이스 생성 : naverDB
테이블 생성 : news
=>테이블 생성
#db_create.py import sqlite3
con = sqlite3.connect("../sqlite-tools-win32-x86-3300100/naverDB") cur = con.cursor()
cur.execute("DROP TABLE news")#테이블 있으면 삭제하고 해야 한다. #위에것 최초생성시 주석 처리한다. cur.execute("CREATE TABLE news (div char(10), title char(100), writer char(10))")
con.commit() con.close()
=>테이블 생성 및 인덱스 생성
#db_create2.py import sqlite3
con = sqlite3.connect("../sqlite-tools-win32-x86-3300100/naverDB") cur = con.cursor()
#cur.execute("DROP TABLE news1") cur.execute("CREATE TABLE news1 (wrdt data,div char(20),title char(100),writer char(20))") cur.execute("create index wrdt on news1 (wrdt)")
con.commit() con.close()
2.네이버 뉴스(정치) 데이터 수집
DB 테이블 저장 : news
파일 저장 : news.txt
#naver_news_db2.py import urllib.request import bs4 import time import sqlite3
## 변수 선언 부분 ## con, cur = None, None data1, data2, data3 = "", "", "" sql = ""
# 메인 코드 부분 ## while True: url = "http://news.naver.com/" html = urllib.request.urlopen(url)
#ul title="" for i in range(len(div_list)): #li a_list = div_list[i].findAll("a",{"class":"DY5T1d"}) for i in range(len(a_list)): writer = div_list[i].findAll("a",{"class":"wEwyrc AVN2gc uQIVzc Sksgp"})[i]