XSigmoid 보다 ReLU가 더 좋아

3단


층을 올렸지만 오히려 결과가 안좋아졌다.
원인은 아래와 같다.


미분 전체가 어려워서 하나씩 미분한다.

곱해지면 값이 점점 작아진다.
미분하면

기울기가 사라진다.

sigmoid보다 다른것 쓰는게 좋다.

1보다 작은 값을 곱해지니깐 chain rule에 의해서 작아진다
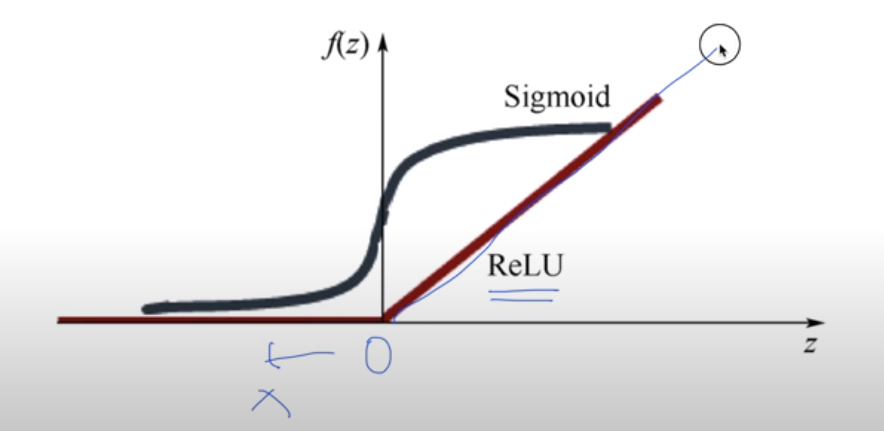
sigmoid 대신 Relu를 넣는다.

sigmoid 대신 relu 로 하는데 마지막 단 제외한다.

Weight 초기화 잘해보자
초기값을 어떻게 할 것인가 ?
초기값을 안해서

0으로 주면 학습이 전혀 안된다.


최저가 되도록 weight를 해야한다.
pre-training
2개 층씩 본다.
값이 들어가면 초기화 값으로 사용한다.
이미 가지고 있는 weight들이 잘 학습되여있다.

Xavier initialization : 입력과 출력에 맞게 한다.


여러가지 해보고 그 중에서 잘 되는것을 하면 된다.

Dropout 과 앙상블

한번도 해보지 않는 것에 대해서는 정확도가 낮다.

에러가 떨어지고 학습이 된것 처럼 보인다.
아주 깊게 만들 수록 overfiting할 가능성이 높다.

l2 regularizatin
0.1하면 굉장히 중요하게 생각한다.
dropout

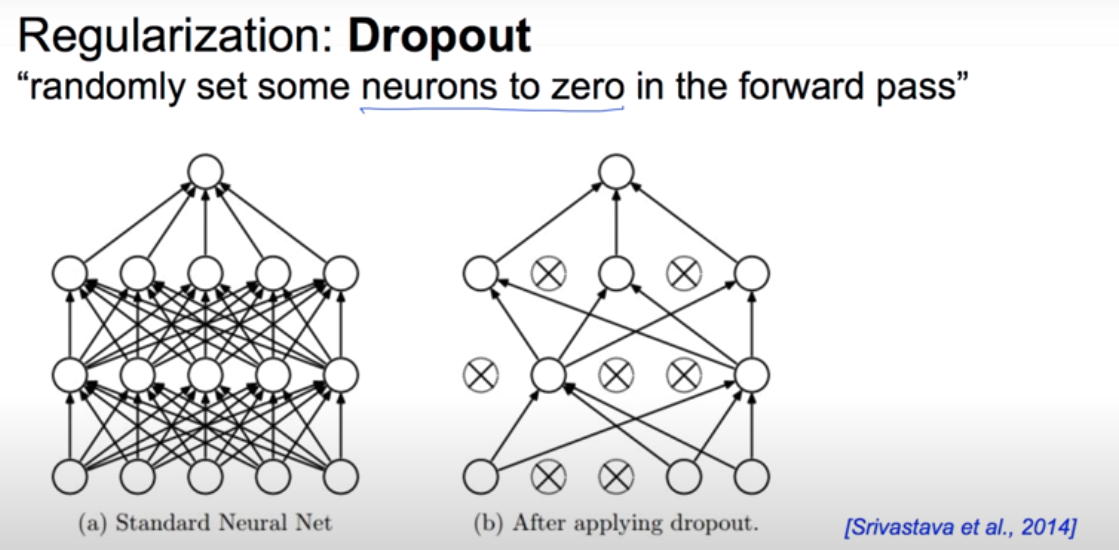
random 하게 줄인다.
random하게 햇 쉬게 해준다.
몇 프로 랜덤하게 고른다. 보통 0.5 사용한다.
학습하는 동안만 하고 뺴고 학습하는데
실제로는 다 가져온다.
모델 사용할 때는 전체 다 가져온다.

기계가 많을 때 학습 시킬 때 많을 때
결과가 조금 다르게 나오지만 마지막에 합친다.
레고처럼 넷트웍 모듈을 마음껏 쌓아 보자
네트워크 있으면 쌓으면 된다.
다양하게 만들 수 있다.
resnet


아래것은 convolutional network이다.


'Machine Learning > 머신러닝과 딥러닝 BASIC' 카테고리의 다른 글
| Recurrent Neural Network (0) | 2021.07.08 |
|---|---|
| Convolutional Neural Networks (0) | 2021.07.06 |
| Neural Network 1: XOR 문제와 학습방법, Backpropagation (0) | 2021.07.04 |
| Neural Network 1: XOR 문제와 학습방법, Backpropagation (0) | 2021.07.04 |
| 딥러닝의 기본 개념과, 문제, 그리고 해결 (0) | 2021.07.04 |