수집 -> 탐색 -> 가공
탐색 -> 데이터 정보 출력
-> 시각화
선 그래프
시계열 쪽 추이 등 보여주는 것
인구변화 등 추이
import pandas as pd
#pop = pd.read_excel('./Desktop/data/시도_별_이동자수.xlsx')
#pop = pd.read_excel('./Desktop//data/시도_별_이동자수.xlsx',fillna = 0 )
pop = pd.read_excel('./Desktop//data/시도_별_이동자수.xlsx',fillna = 0,header = 0 )
print(pop.head())
#na(None,numpy.NaN...) 값을 앞의 데이터로 채우기
#파이썬의 분석 라이브러리의 수정하는 메소드들은
#대부분 수정해서 복사본을 리턴합니다.
#원본에 반열할 때는 다시 대입하거나
#inplace옵션이 있으면 이 옵션에 True를 대입
pop = pop.fillna(method='ffill')
print(pop.head())
#전출지별은 서울 특별시 이고 전입지는 서울특별시가
#아닌 데이터만 추출하기 위한 조건 만들기
mask = (pop['전출지별'] =='서울특별시') & (pop['전입지별'] !='서울특별시')
print(pop[mask])
#df_seoul = pop[mask]
#전출지별 열을 제거
df_seoul = pop[mask].drop(['전출지별'], axis = 1)
print(df_seoul)
print(pop)
#전입자별 컬럼이름을 전입지로 수정
#inplace옵션을 이용해서 원본에 반영
#axis = 1 행단위를 열단위로
df_seoul.rename({'전입지별':'전입지'},axis = 1, inplace = True)
print(df_seoul.head())
#인덱스를 기존 컬럼으로 변경하고 컬럼은 제거
df_seoul.set_index('전입지', inplace=True)
print(df_seoul.head())
#전라남도로 전출간 인원에 대한 선 그래프 그릭
sr_one = df_seoul.loc['전라남도']
#1970, 1971 제거
sr_one.drop(['1970','1971'], inplace = True)
import matplotlib.pyplot as plt
plt.plot(sr_one.index, sr_one.values)
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
import platform
#매킨토시의 경우
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
#윈도우의 경우
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#스타일설정
plt.style.use('ggplot')
#이미지 사이즈 설정 - 단위는 인치
plt.figure(figsize = (14,5 )) #데이터 많으면 여기 조정 해야 한다.
#눈금 조정
plt.xticks(size = 10, rotation = 'vertical')
#그래프 그리기
plt.plot(sr_one.index, sr_one.values, marker = 'o' , markersize = 10)
#그래프 제목 만들기
plt.title('서울에서 전라남도로의 이동',size = 30)
#축제목 만들기
plt.xlabel('기간',size = 20)
plt.ylabel('인구 수',size = 30)
#범 례
plt.legend(labels=['서울 -> 전라남도'],loc ='best',fontsize = 15)
#그래프 위에 글자 작성
plt.annotate('인구이동 감소',xy = (40, 50000), rotation = -11, va = 'baseline',ha = 'center',fontsize = '15')
plt.show()
**시각화
=>데이터의 형태를 파악하거나 보고서를 만들 목적으로 그래프나 지도 등을 출력하는 작업
=>matplotlib(기본 시각화),pandas, seaborn(시각적인 효과가 조금 더 뛰어남 ) ,folium(지도 , 단계구분도) 등을 주로 이용
1.꺽은선 그래프 -plot
=>날짜나 시간에 따른 변화량 또는 2개의 컬럼을 가지고 데이터의 분포를 알아볼 때 많이 이용
2. 하나의 화면에 2개의 그래프 그리기
객체 = plt.figure(figsize = (가로크기 , 세로크기))
변수 1 = 객체.add_subplot(행의 개수 , 열의 개수, 자신의 번호 )
변수 2 = 객체.add_subplot(행의 개수, 열의 개수 , 자신의 번호) ..
변수1.plot(옵션 ...)
변수2.plot(옵션 ...)
#기존 데이터에서 전라남도에서 서울로 이동한 인구수 찾기
mask = (pop['전출지별'] == '전라남도') & (pop['전입지별'] != '전라남도')
df_jeo = pop[mask]
#print(pf_jeo.head())
#전출지별 컬럼 제거하기
df_jeo = df_jeo.drop(['전출지별'],axis = 1)
#컬럼이름 변경하기
df_jeo.rename({'전입지별':'전입지'},axis = 1, inplace = True)
#인덱스 설정하기
df_jeo.set_index('전입지',inplace = True)
#서울로 이동한 데이터만 가져오기
sr_two = df_jeo.loc['서울특별시']
print(sr_two.head())
#여러개의 그래프를 그리기 위해서 그리기 객체를 돌려받음
fig = plt.figure(figsize = (10,10))
#2행 1열에서 1번
ax1 = fig.add_subplot(2,1,1)
#2행 1열에서 2번
ax2 = fig.add_subplot(2,1,2)
ax1.plot(sr_one, marker='o' , markersize = 10, color='orange',linewidth = 2, label ='서울->전라남도')
ax2.plot(sr_two, marker='o' , markersize = 10, color='green',linewidth = 2, label ='전라남도->서울')
#y축 눈금범위 설정
ax1.set_ylim(10000,150000)
ax2.set_ylim(10000,150000)
ax1.set_xticklabels(sr_one.index,rotation = 75)
ax2.set_xticklabels(sr_two.index,rotation = 75)
plt.show()
=>하나의 그래프에 그리기
ax1.plot(sr_one, marker='o' , markersize = 10, color='orange',linewidth = 2, label ='서울->전라남도')
ax1.plot(sr_two, marker='o' , markersize = 10, color='green',linewidth = 2, label ='전라남도->서울')
3.하나의 영역에 여러개의 그래프 그리기
=>동일한 영역에서 그리는 함수를 여러번 호출
4. 막대 그래프
=>빈도 수를 비교할 때 주로 이용
=>bar(수직), barh(수평) 메소드로 그림
=>하나의 영역에 2개의 막대그래프를 그릴 때는 첫번째 막대 그래프의 width를 조정
width가 1이면 다음 데이터와 붙어서 출력됩니다.
2개면 0.5이하로 설정해서 그리고 3개면 0.33이하로 설정하면 됩니다.
##서울에서 전라남도 , 경상남도 ,충청남도
##전출간 인원을 막대 그래프로 비교
#비교는 막대 그래프 추이는 선
#커널을 제시작
import pandas as pd
df = pd.read_excel('./Desktop//data/시도_별_이동자수.xlsx',header = 0,fillna = 0 )
print(df.head())
#헤더 위치
#NaN값을 이전 값으로 채우기
df = df.fillna(method='ffill')
print(df.head())

#필요한 데이터만 행단위로 뽑고 싶다.
#서울 데이터만 출력
#전출지별이 서울특별시이고 전입별이 서울특별시가 아닌 것
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
#mask의 결과가 true인 것 만 추출
df_seoul = df[mask]
print(df_seoul.head())
#불필요한 열 제거
df_seoul.drop(['전출지별'],axis = 1, inplace = True)
print(df_seoul.head())

#불필요한 행 제거 -인덱스 설정을 안한 경우는 일련번호로 제거
#df_seoul.drop([0,1,2,3,4,5],axis = 1, inplace = True)
#print(df_seoul.head())
#기존 컬럼을 인덱스로 설정
df_seoul.set_index(['전입지별'],inplace =True)
print(df_seoul.head())
#행단위로 골라내기 - 인덱스를 이용
sr= df_seoul.loc[['경기도','충청남도','경상남도','전라남도']]
print(sr)
#행과 열을 치환
sr = sr.T #행과 열 치환
print(sr)

T ->행과 열 치환
cross tab
set_index
#데이터 모임에 동일한 함수를 적용한 후 결과 만들기
#sr.index에 int라는 함수를 각 요소마다 대입해서 실행 한 후
# 그 결과를 가지고 다시 데이터의 모임을 생성
sr.index = sr.index.map(int)
import matplotlib.pyplot as plt
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
import platform
#매킨토시의 경우
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
#윈도우의 경우
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#그래프 그리기
plt.figure(figsize = (15,6))
plt.bar(pd.RangeIndex(0,len(sr.index),1),sr['경기도'],width = 1)
plt.title('서울에서의 인구이동')
#그냥 그리면 한글이 깨진다.
plt.show()

#데이터 모임에 동일한 함수를 적용한 후 결과 만들기
#sr.index에 int라는 함수를 각 요소마다 대입해서 실행 한 후
# 그 결과를 가지고 다시 데이터의 모임을 생성
sr.index = sr.index.map(int)
import matplotlib.pyplot as plt
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
import platform
#매킨토시의 경우
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
#윈도우의 경우
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#그래프 그리기
plt.figure(figsize = (15,6))
#plt.bar(pd.RangeIndex(0,len(sr.index),1),sr['경기도'],width = 1)
plt.bar(pd.RangeIndex(0,len(sr.index),1),sr['경기도'],color = 'orange',width = 0.25,label ='경기도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.25,sr['전라남도'],color = 'green',width = 0.25,label ='전라남도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.5,sr['충청남도'],color = 'red',width = 0.25,label ='충청남도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.75,sr['경상남도'],color = 'blue',width = 0.25,label ='경상남도')
#범례 표시
# 색갈에 대해서 구분하기 힘들 다.
plt.legend()
plt.title('서울에서의 인구이동')
#그냥 그리면 한글이 깨진다.
plt.show()
#경기도 빼면 어느 정도 구분이 된다.

#데이터 모임에 동일한 함수를 적용한 후 결과 만들기
#sr.index에 int라는 함수를 각 요소마다 대입해서 실행 한 후
# 그 결과를 가지고 다시 데이터의 모임을 생성
sr.index = sr.index.map(int)
import matplotlib.pyplot as plt
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
import platform
#매킨토시의 경우
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
#윈도우의 경우
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#그래프 그리기
plt.figure(figsize = (15,6))
#plt.bar(pd.RangeIndex(0,len(sr.index),1),sr['경기도'],width = 1)
#plt.bar(pd.RangeIndex(0,len(sr.index),1),sr['경기도'],color = 'orange',width = 0.25,label ='경기도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.25,sr['전라남도'],color = 'green',width = 0.25,label ='전라남도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.5,sr['충청남도'],color = 'red',width = 0.25,label ='충청남도')
plt.bar(pd.RangeIndex(0,len(sr.index),1)+0.75,sr['경상남도'],color = 'blue',width = 0.25,label ='경상남도')
#범례 표시
# 색갈에 대해서 구분하기 힘들 다.
plt.legend()
plt.title('서울에서의 인구이동')
#그냥 그리면 한글이 깨진다.
plt.show()
#경기도 빼면 어느 정도 구분이 된다.
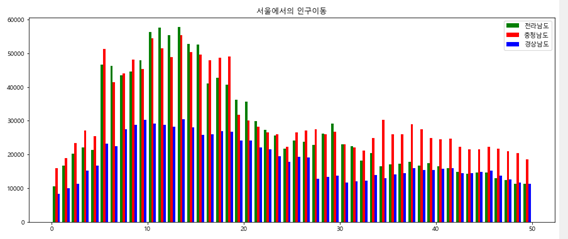
막대그래프는 비슷한 것 끼리 비교해야 한다. 아니면 비교가 어렵다.
하나는 마이너스 곱하고 다른 하나는 정상으로
단위가 2개 있으면 하나에 두개 그리기 추이하고 가격
5. 히스트그램
=>각 구간의 데이터 개수를 파악하고자 할 때 사용하는 그래프
=>hist메소드를 이용
#lovefruits.csv파일의 내용 읽어오기
df = pd.read_csv('./Desktop/data/lovefruits.csv')
print(df)

#lovefruits.csv파일의 내용 읽어오기
df = pd.read_csv('./Desktop/data/lovefruits.csv',encoding = 'cp949')
print(df)
#막대 그래프를 이용해서 데이터 개수 출력하기
data= df['선호과일'].value_counts(sort = False)
print(data)
plt.bar(range(0,len(data),1),data)
plt.xticks(range(0,len(data),1),data.index)
plt.title('과일 선호도 조사')
plt.show()
#히스트그램을 이용해서 데이터 개수 출력하기 -개수 파악ㄱ 작업 필요 없음
plt.hist(df['선호과일'])
plt.show()
#히스트그램은 bins옵ㄴ션을 이용해서 구간의 개수를 설정해서 그릴 수 있음
#연속형 데이터의 히스트그림은 구간 설정을 해야 합니다.
#점수 등은 문제가 생긴다.
df = pd.read_csv('./Desktop/data/student.csv',encoding = 'cp949')
print(df)
#plt.hist(df['수학']) #데이터가 많을 수 있다.
plt.hist(df['수학'],bins= 3) #3개 구간으로 나누어진다.
plt.show()
#연속적인가 범주이냐 등에서 달라진다.
#선호도는 범주형 이기 때문에 bins를 설정할 필요없다.
#점수는 완전한 연속형이 아니지만 연속형이여서 bins를 설정해야 한다.
6. 산포도
=>2개 컬럼의 관계를 파악하기 위해서 생성
=>상관여부나 그룹핑할 개수 등을 파악하고자 할 때 먼저 그려보면 효과적입니다.
=>scatter라는 메소드를 이용
=>colorvar를 이용해서 산포도에 그려지는 데이터의 색상에 크기를 적용할 수 있습니다.
한방형으로 줄어들거나 크지면 상관관계가 높다.
상관관계와 두개 이상 그룹핑하면 상관관계와 관계없다.
몇개의 그룹을 만드는지 어떻게 그룹핑하면 좋을지는 산포도를 그래면 된다.
생활비 , 교통비 등 등급 으로 만들고 싶을 때 각각의 2-3개 묶어서 상관관계 높은지 파악할 수 있다.
관계를 파악하고 작업을 해야 한다.
#2개 컬럼의 관게를 파악하기 위한 산포도
df = pd.read_csv('./Desktop/data/auto-mpg.csv')
#열 이름 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight','accleration','model year','origin','name']
print(df.head())
#s는 원의 크기 옵션
plt.scatter(x = df['weight'], y = df['mpg'],s= df['cylinders']*10,alpha = 0.5)
plt.title('중량과 연비의 관계')
plt.xlable('중량',size = 20)
plt.xlable('연비',size = 20)
plt.show()
#반비례 상관관계
7.파이 그래프
=>전체에서의 기여도를 파악할 때 주로 이용
=>하나의 열을 가지고 작성
=>메소드이름은 pie
=>explode옵션에 실수 리스트를 대입하면 중앙에서 대입한 숫자 만큼 떨어져서 그려짐 , 0.0~ 1.0사이
=>autopct에 숫자 서식을 설정해서 백분율을 표시할 수 있음 ㅣ '%1.1f%%' -소수 첫째자리 까지의 백분율
#파이 그래프
df = pd.read_csv('./Desktop/data/korea.csv', encoding = 'cp949')
print(df.head())
explode = []
for i in range(0,20):
explode.append(0)
explode[2] = 0.3
# 튀여 나오게 하는 것은 잴 큰것 찾아서 혹은 잴 작은 애
plt.figure(figsize = (15,8))
plt.pie(df['점수'],labels=df['이름'],explode = explode, autopct = '%1.1f%%')
plt.title('학생별 기여도')
plt.legend()
plt.show()
#max는 잴 큰것
#파이 그래프
df = pd.read_csv('./Desktop/data/korea.csv', encoding = 'cp949')
print(df.head())
explode = []
for i in range(0,20):
explode.append(0)
#explode[2] = 0.3
#explode[df['점수'].idxmax(axis = 1)]= 0.3
explode[df['점수'].idxmin(axis = 1)]= 0.3
# 튀여 나오게 하는 것은 잴 큰것 찾아서 혹은 잴 작은 애
plt.figure(figsize = (15,8))
plt.pie(df['점수'],labels=df['이름'],explode = explode, autopct = '%1.1f%%')
plt.title('학생별 기여도')
plt.legend()
plt.show()
#max는 잴 큰것
print(df['점수'].idxmax(axis = 1)) #젤 큰 값의 인덱스
8.box-plot 그래프
=>데이터의 분포를 확인할 때 사용하는 그래프
=>상자의 중앙선이 중간값 상자의 좌우가 25%, 75%에 해당하는 값
양끝선이 아래쪽 0.75%정도 위끝선은 99.75% 정도에 해당하는 값
작은 원으로 표현되는 극단치(outlier)로 판단
=>중앙선과 양끝단의 선, 상자의 선을 보고 데이터의 분포를 예측
한쪽으로 치우치면 정규분초가 아닌 형태로 판정
#상자그래프 그리기
df = pd.read_csv('./Desktop/data/student.csv',encoding = 'cp949')
plt.figure()
plt.boxplot((df['국어'],df['영어'],df['수학']),labels=('국어','영어','수학'))
plt.show()
9.면적 그래프
=>선 그래프의 하단에 색상을 칠한 그래프
=>목적은 막대그래프와 유사
=>fill_between이라는 메소드를 이용
**seaborn패키지
=>matplotlib 을 기반으로 해서 여러가지 테마아 통계형 차트가 추가된 패키지
=>numpy나 pandas의 자료구조는 그대로 사용
문서: http://seaborn.pydata.org/tutorial/aesthetics.html
set: http://seaborn.pydata.org/generated/seaborn.set.html
set_style: http://seaborn.pydata.org/generated/seaborn.set_style.html
set_color_codes: http://seaborn.pydata.org/generated/seaborn.set_color_codes.html
http://seaborn.pydata.org/examples/index.html
pandas는 샘플 데이터 가지지 않는다. 하지만 seaborn부터는 샘플 데이터 몇개 가지고 있다.
1.regplot이나 lmplot이라는 함수를 이용해서 데이터의 분포와 1차 다항식 그래프를 같이 출력 가능
1차 다항식은 2개의 컬럼의 회귀식입니다.
#커널을 재시작 import된 모든 라이브러리 제거
#변수도 모두 제거
import matplotlib.pyplot as plt
#시각적인 효과가 조금더 뛰어난 그래프 패키지
import seaborn as sns
#tips라는 데이터 가져오기 -레스토랑에서의 tip에 관련된 데이터
tips = sns.load_dataset('tips')
print(tips.head())
fig = plt.figure(figsize = (8,6))
#1행 2열 1번째
ax1 = fig.add_subplot(1,2,1) #위아래
ax2 = fig.add_subplot(1,2,2) #좌우
sns.set_style('darkgrid')#색상 쓰지 않아도 style을 정한다.
#data에 dataframedmf x,y에 컬럼이름을 설정
sns.regplot(x = 'total_bill' , y = 'tip' ,data = tips, fit_reg = True, ax = ax1) #회귀 최소한 2개 있어ㅑ 한다. x축 y축
sns.regplot(x = 'total_bill' , y = 'tip' ,data = tips, fit_reg = False, ax = ax2) #회귀 선이 안나온다.
plt.show()
#3개 컬럼의 관계보기 -lmplot
#x,y,hue옵션 이용
#hue 에는 카테고리(범주) 데이터를 설정
fig = plt.figure(figsize = (8,6))
sns.set_style('darkgrid')#색상 쓰지 않아도 style을 정한다.
#sns.lmplot(x = 'total_bill' , y = 'tip' ,hue = 'sex', data = tips, fit_reg = True)
sns.lmplot(x = 'total_bill' , y = 'tip' ,hue = 'smoker', data = tips, fit_reg = True)
plt.show()
밀도추정 데이터가 다를수 있지만 계속 모아다 나면 예측이 가능하다.
밀도는 확률
hist그램은 연속적이지 못한다. bins에 따라 많이 달라진다. 메모리 문제가 생길 수 도 있다. ->kerder density Estinmation
Kernel Density Estimation (커널 밀도 추정)
2.단변량 데이터의 분포를 출력
=>히스트그램을 이용하는 경우가 많음 - 쉽다는 장점은 있지만 불연속하게 그려집니다.
=>히스트그램 대신에 커널밀도함수(kde)를 적용해서 연속적으로 그려서 파악하는 경우가 있음
=>seaborn의 displot이라는 함수를 이용하면 커널 밀도 함수를 적용한 그래프와 히스트그램을 같이 출력할 수 있음
#tip컬럼에 분포를 확인
fig = plt.figure(figsize=(8,6))
sns.set_style("darkgrid")
sns.distplot(tips['tip'])
plt.show()

tip을 안주는 사람은 구분하지 못한다.
안준 분이 5명 10불 준 분은 2명
1불은 나올수 없는 것이다. 비연속
1불을 줄수 도 있는 것이고
데이터 예측은 연속적이여야 한다. 없다고 하면 안된다.
#tip컬럼에 분포를 확인
fig = plt.figure(figsize=(8,6))
sns.set_style("darkgrid")
#sns.distplot(tips['tip'])
sns.distplot(tips['tip'],hist=False)
plt.show()

이산 :디지털
범주형 -> 불연속성 -> 연속으로 만드는 것이 정밀도
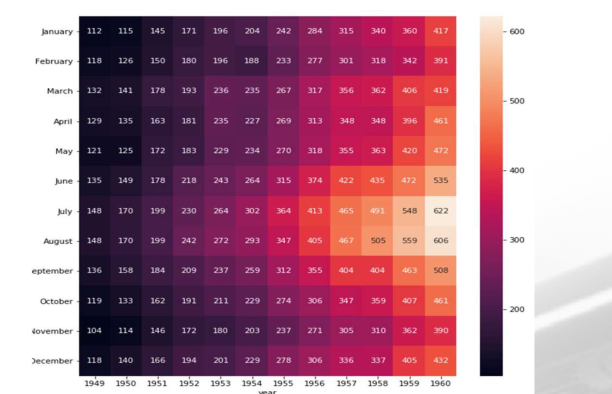
3.heatmap
=>크로스 테이블을 시각화할 때 주로 이용
=>2개 항목을 적용해서 분류한 후 데이터를 출력하는 시각화
=>Dataframe에서 pivot이라는 함수를 이용해서 2개로 분류하고 계산할 항목과 함수를 지정(함수는 생략하면 합계)
=>heatmap함수에 데이터를 대입하면 시각화 된다.
fmt = 'd'
=>
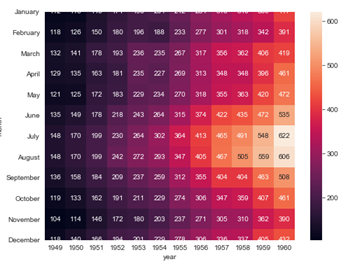
#heatmap(2가지로 분류해서 하나의 통계값 출력) 만들기
flights = sns.load_dataset('flights')
print(flights.head())
#pivot테이블 만들기
pivot = flights.pivot('month','year','passengers')
print(pivot)
fig = plt.figure(figsize=(8,6))
#글자는 annotation
#annot 는 데이터를 화면에 출력할 것인지 여부
#fmt는 숫자 출력 포맷으로 d를 설정하면 정수로 출력
sns.heatmap(pivot, annot = True,fmt = 'd')
plt.show()
4.violinplot
=>boxplot은 데이터 값들의 상한과 하한 , 4분위 수 등을 파악
=>violinplot은 시각형 대신에 커널밀도 함수를 적용해서 데이터 개수도 어느 정도 파악이 가능
5.데이터 개수 출력
=>strippot, swarmplot()등이 제공
6.막대 그래프 -barplot
7.히스트그램-countplot
8.데이터프래임의 모든 컬럼의 상관관계를 출력 -pairplot
9.상관관계를 출력하고 히스트그램까지 출력 -jointplot
#tips데이터의 모든 컬럼의 산저모를 출력
pythoh, r, 에서 시각화
=>탐색
=>보고서
**folium
=>지도나 단계구분도를 위한 시각화 패키지
=>자바스크립트 기반으로 interactive(동적으로 변화)하게 시각화
=>기본패키지가 아니라서 설치를 해야 함
=>jupyter-notebook이 크롬에서 실행중이라면 바로 출력 가능
다른 ide를 사용하는 save('파일 경로.html'로 저장한 후 브라우저에서 확인
ie에서는 자바스크립트 문제로 출력되지 않음
=>단계구분도를 만들 때는 각 지역의 경계에 대한 json데이터가 존재해야 합니다.
한국 데이터는 southkorea-maps에서 확인 가능
1지도 생성
folium.Map(location=[위도, 경도], zoom_start = 확대축소비율)
2.마커 생성
folium.Marker(location=[위도, 경도],popup =출력될 문자열, icon = 이미지).add_to(지도객체)
3.출력
-주피터 노프복: 지도 객체
-다른 ide:지도 객체.save('파일경로')
크롬으로 변경


import folium
#지도 생성
m = folium.Map(location = [37.572656, 126.973304], zoom_start = 15)
#zoom_start 숫자가 크면 클수록 축소가 된다.
folium.Marker(location=[37.572656, 126.973304],popup='KB Card',icon = folium.Icon(icon='cloud')).add_to(m)
folium.Marker(location=[37.569027, 126.988000],popup='김떡순 원조',icon = folium.Icon(icon='cloud')).add_to(m)
#여기서는 한글이 때지지만 save하면 한글에 아무 문제도 없다.
#지도 출력
m
#지도 저장
#m.save('map.html')
# spyder에서 하면 m.save해서 봐야 한다.
semi-project 조 편성
인원은 3 ~ 4 : 5개조
딥러닝 프로젝트를 1개씩 배정
취업 분야
- AI분야
- 개발분야
개발 분야로 취업을 생각했으면 프로젝트 하면서 웹 서버 개발 프로젝트를 진행
개발 분야로 취업을 생각한 경우 프로젝트는 웹 서버를 만들어서 데이터를 가지고 홤녀에 출력하고 Open API를 제공해서 모바일(android)에서 출력
kaggle
개발 일지 만들기
어려운 부분하고
어떻게 극복했는지
소스 다하고 소스 올리기 형상관리 여부 확인
카카오톡 아니고 slack 사용하기