[논문] : SCATTER: Selective Context Attentional Scene Text Recognizer
Ron Litman∗ , Oron Anschel∗ , Shahar Tsiper, Roee Litman, Shai Mazor and R. Manmatha
Amazon Web Services
{litmanr, oronans, tsiper, rlit, smazor, manmatha}@amazon.com
2020 05 25
Abstract
Selective Context ATtentional Text Recognizer (SCATTER)
SCATTER는 학습 과정에서 intermediate supervision 기능이있는 스택 형 블록 아키텍처를 사용하여 심층 BiLSTM 인코더의 성공적인 학습을 위한 길을 열어 상황에 맞는 코딩을 개선합니다. 디코딩은 2 단계주의 메커니즘을 사용하여 수행됩니다.
첫 번째 attention step는 CNN backbone의 시각적 특징과 BiLSTM 계층에서 계산 한 컨텍스트 특징에 가중치를 부여하는 것입니다.
두 번째 attention step은 이러한 기능을 시퀀스로 간주하고 시퀀스 간의 관계에 추가합니다.
1. Introduction
recognizing scene text can be divided into two main tasks - text detection and text recognition.
Text detection is the task of identifying the regions in a natural image, that contain arbitrary shapes of text. =>지역 실별
Text recognition deals with the task of decoding a cropped image that contains one or more words into a digital string of its contents. =>cropped image 문자 숫자 등 decoding
text images:
irregular text 임의의 shaped text Fig.1
regular text text with nearly horizontally aligned characters (examples are provided in the supplementary material)

전통적인 text recognition methods [37, 38, 42] detect and recognize text character by character, =>고유한 한계가 있다. sequential modeling and contextual dependencies between characters 활용하지 못한다.
[37] Kai Wang, Boris Babenko, and Serge Belongie. Endto-end scene text recognition. In 2011 International Conference on Computer Vision, pages 1457–1464. IEEE, 2011.
[38] Kai Wang and Serge Belongie. Word spotting in the wild. In European Conference on Computer Vision, pages 591–604. Springer, 2010.
[42] Cong Yao, Xiang Bai, Baoguang Shi, and Wenyu Liu. Strokelets: A learned multi-scale representation for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4042–4049, 2014
최신 방법은 STR을 시퀀스 예측 문제로 취급합니다. 우수한 정확도를 달성하는 동안 character-level annotations (per-character bounding box)의 기술을 완화할 필요가 있다
sequence-based methods rely on Connectionist Temporal Classification (CTC) [31, 7], or attention-based mechanisms [33, 16].
four-step STR framework는 individual components 는 다른 알고리즘 교환가능하게 허용한다. This modular framework, along with its best performing component configuration, is depicted in Fig. 1 (a). In this work, we build upon this framework and extend it.
정상적인 scene text를 정확하게 인식하면서 해결되지 않은 문제, 다음과 같은 최근 불규칙한 STR 벤치 마크 ICD15 (SVTP)는 텍스트를 임의의 모양으로 인식하는 문제로 연구 초점을 전환했습니다. Sheng et al. [30]은 다음 개체에 대해 Transformer [35] 모델을 채택했습니다. STR은 변환기 기능을 사용하여 장기적인 컨텍스트 종속성을 캡처합니다. The authors in [16] passed the visual features from the CNN backbone through a 2D attention module down to their decoder. Mask TextSpotter [17]는 탐지 및 인식 작업을 수행합니다. 공유 백본 아키텍처. 인식 단계에서 두 가지 유형의 예측 분기가 사용되며,보다 특정 분기의 출력을 기반으로 최종 예측이 선택됩니다.
The first branch uses semantic segmentation of characters, and requires additional character-level annotations.
The second branch employs a 2D spatial attentiondecoder.
Most of the aforementioned STR methods perform a sequential modeling step using a recursive neural network (RNN) or other sequential modeling layers (e.g., multihead attention [30]), usually in the encoder and/or the decoder. This step is performed to convert the visual feature map into a contextual feature map, which better captures long-term dependencies. In this work, we propose using a stacked block architecture for repeated feature processing, a concept similar to that used in other computer-vision tasks such as in [40] and later in [27, 26]. The authors above showed that repeated processing used in conjunction with intermediate supervision could be used to increasingly refine predictions. In this paper.
visual feature map -> contextual feature map
stacked block architecture
Our method, as depicted in Fig. 1, utilize a stacked block architecture for repetitive processing with intermediate supervision in training, and a novel selective-decoder.
selective-decoder 는 두가지 다른 layers of the network를 수렴한다.
visual features from a CNN backbone
contextual features computed by a BiLSTM layer
이 사이에 two-step 1D attetion mechanism을 사용한다.

Figure 2 shows the accuracy levels computed at the intermediate auxiliary decoders, for different stacking arrangements, thus demonstrating the increase in performance as additional blocks are added in succession. block 수에 따라 정확도가 다르다. Interestingly, training with additional blocks in sequence leads to an improvement in the accuracy of the intermediate decoders as well (compared to training with a shallower stacking arrangement).
두가지 공헌이 있다.
1. We propose a repetitive processing architecture for text recognition, trained with intermediate selective decoders as supervision. Using this architecture we train a deep BiLSTM encoder, leading to SOTA results on irregular text. => irregular text.에서 SOTA
2. A selective attention decoder, that simultaneously decodes both visual and contextual features by employing a two-step attention mechanism. The first attention step figures out which visual and contextual features to attend to. The second step treats the features as a sequence and attends the intra-sequence relations. =>두가지 STEP attention mechanism
2. Related Work
3. Methodology

3. Methodology
4가지 주요한 componets로 구성되여있다.
1. Transformation: the input text image is normalized using a Spatial Transformer Network (STN) [13]. =>stn을 사용하여 정규화
2. Feature Extraction: maps the input image to a feature map representation while using a text attention module [7]. => text attention module 사용하여 feature map으로
텍스트주의 모델을 사용하여 입력 이미지를 특징 표현에 매핑
3. Visual Feature Refinement: provides direct supervision for each column in the visual features. This part refines the representation in each of the feature columns, by classifying them into individual symbols.=>시각적 기능의 각 열을 직접 모니터링합니다. 특성 열을 별도의 기호로 분류하여 각 특성 열의 표현을 구체화합니다.
4. Selective-Contextual Refinement Block: Each block consists of a two-layer BiLSTM encoder that outputs contextual features. The contextual features are concatenated to the visual features computed by the CNN backbone. This concatenated feature map is then fed into the selective-decoder, which employs a two-step 1D attention mechanism, as illustrated in Fig. 4.각 블록에는 2 계층 BILSTM 인코더 출력 컨텍스트 기능이 포함되어 있습니다. 상황 별 기능과 시각적 기능을 선택적 디코더의 입력으로 결합 (two-step 1D attention mechanism)

3.1. Transformation
정규화
3.2. Feature Extraction
We use a 29-layer ResNet as the CNN’s backbone, as used in [5]. The output of the feature encoder is 512 channels by N columns.
ResNet으로 이미지 feature map 추출 F = [f1, f2, ..., fN ]. attentional feature map으로 visual feature sequence of length N V = [v1, v2, ..., vN ]
text attention module:기능 필터링, 시맨틱 정보를 사용하여 기능 열을 향상시키고 중복 및 혼동을 억제하며 텍스트 부분에 더 많은주의를 기울입니다.
3.3. Visual Feature Refinement
visual feature sequence V is used for intermediate decoding
This intermediate supervision is aimed at refining the character embedding (representations) in each of the columns of V , and is done using CTC based decoding.
We feed V through a fully connected layer that outputs a sequence H of length N.
The output sequence is fed into a CTC [8] decoder to generate the final output.
loss for this branch, denoted by Lctc , , is the negative log-likelihood of the ground-truth conditional probability, as in [31].
3.4. Selective-Contextual Refinement Block
The features extracted by the CNN 는 각 FIELD에서 제한 되여있으면 , contextual informatoin에 부족하여 고통받고 있다. 이 단점을 완화하기 위하여 we employ a twolayer BiLSTM [9] network over the feature map V , outputting H = [h1, h2, ..., hn]. We concatenate the BiLSTM output with the visual feature map, yielding D = (V, H), a new feature space.
The feature space D is used both for selective decoding, and as an input to the next Selective-Contextual Refinement block.Specifically, the concatenated output of the jth block can be written as Dj = (V, Hj ). The next j + 1 block uses Hj as input to the two-layer BiLSTM, yielding Hj+1, and the j + 1 feature space is updated such that Dj+1 = (V, Hj+1). The visual feature map V does not undergo any further updates in the Selective-Contextual Refinement blocks, however we note that the CNN backbone is updated with back-propagated gradients from all of the selective-decoders. These blocks can be stacked together as many times as needed, according to the task or accuracy levels required, and the final prediction is provided by the decoder from the last block.
3.4.1 Selective-Decoder
two-step attention mechanism 사용
우선 , 우리는 1D self attention 을 사용하여 features D 조작 한다. 완전히 연결된 레이어를 사용하여 지형지 물의주의지도를 계산합니다. 그 다음 , attentional features D '를 얻기 위해 attention map와 D 사이의 곱을 계산합니다. D ' 의 decoding은 attention -decoder 을 분리해서 하기때문에 , t-time-step마다 decode ouputs Yt 가 있다. similar to [5, 2].
3.5. Training Losse
empirically set to 0.1, 1.0 respectively for all j.
3.6. Inference
추론 단계에서는 중간 디코더가 필요하지 않으며 마지막 디코더 만 최종 결과를 출력하는 데 사용됩니다.
4. Experiment
4.1. Dataset
The model is evaluated on four regular scene-text datasets: ICDAR2003, ICDAR2013, IIIT5K, SVT, and
three irregular text datasets: ICDAR2015, SVTP and CUTE
The training dataset is a union of three datasets
MJSynth (MJ) [12]
SynthText (ST) [10]
SynthAdd (SA)) [16]
Regular text
Irregular text

4.2. Implementation Details
we use the code of Baek et al.1 [1]
PyTorch the PyTorch2 framework on a Tesla V100 GPU with 16GB memory.
we do not perform any type of pre-training
optimizer : AdaDelta
decay rate 0.95 , gradient clipping with a magnitude 5
batch size of 128 (with a sampling ratio of 40%, 40%, 20% between MJ, ST and SA respectively)
We use data augmentation during training, and augment 40% of the input images, by randomly resizing them and adding extra distortion.
각 Each model is trained for 6 epochs on the unified training set.
validation dataset
image resize : 32 × 100
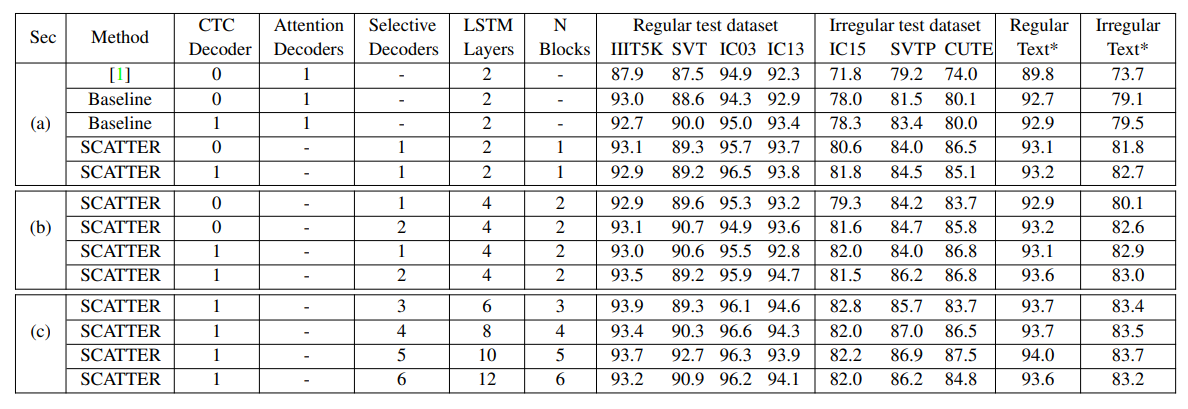
4.3. Comparison to State-of-the-art
4.4. Computational Costs

5. Ablation Experiments
Throughout this section, we use a weighted-average (by the number of samples) of the results on the regular and irregular test datasets.
5.1. Intermediate Supervision & Selective Decoding
5.2. Stable Training of a Deep BiLSTM Encoder
5.3. Oracle Decoder Voting


6. Conclusions and Future Work
Supplementary Materials
A. Regular Vs Irregular Text

B. Network Pruning - Compute Constraint
C. Examples of Intermediate Predictions
D. Stable Training of a Deep BiLSTM Encoder



blog.csdn.net/m0_38007695/article/details/107391104
SCATTER: Selective Context Attentional Scene Text Recognizer --- 论文阅读笔记_BIRD_CHARLES-CSDN博客
Paper : https://arxiv.org/abs/2003.11288 SCATTER 在训练过程中采用了带有中间监督的堆叠式块体系结构,从而为成功训练深度 BiLSTM 编码器铺平了道路,从而改善了上下文相关性的编码。 解码使用两步注意
blog.csdn.net