논문출처: Wide Residual Networks
Abstract
Deep residual networks는 수천 개의 레이어로 확장 할 수 있으며 여전히 성능이 향상되는 것으로 입증되었다. 그러나 각 네트워크의 훈련 정확도는 거의 두 배가되어 각 네트워크의 훈련 정확도가 두 배된다. 이러한 문제에 대응하여 본 논문에서는 ResNet 블록의 구조에 대한 자세한 실험적 연구를 수행하고이를 바탕으로 ResNet 네트워크 깊이를 줄이고 ResNet 네트워크 폭을 증가시키는 새로운 구조를 제안한다. 이 네트워크 구조를 WRN (Wide Area Residual Network)이라고하며 이러한 네트워크 구조가 일반적으로 사용되는 얇고 매우 깊은 네트워크 구조보다 훨씬 우수하다는 것을 보여준다. 예를 들어, 우리는 단순한 16-layer-deep wide residual network 조차도 CIFAR, SVHN 및 COCO의 최신을 달성 한 천 계층 딥 네트워크를 포함하여 이전의 모든 deep wide residual network 보다 정확도와 효율성이 더 우수하다는 것을 증명했다. ImageNet에 대한 성과와 상당한 개선이 이루어졌습니다. 우리의 코드와 모델은 https://github.com/szagoruyko/wide-residual-networks에서 확인할 수 있다.
Introduction
지난 몇 년간 Convolutional neural networks의 계층 수가 AlexNet [16], VGG [26], Inception [30]에서 많은 이미지 인식 작업의 개선에 해당하는 잔여 네트워크 [11]로 점차 증가했다 . 최근 몇 년 동안 일부 연구에서 딥 네트워크의 우월성을 발견했다 [3,22]. 그러나 심층 신경망의 훈련에는 exploding/vanishing gradients and degradation 등 몇 가지 어려움이 있다. 잘 설계된 초기화 전략 [1,12], better optimizers [29], 연결 건너 뛰기 [19,23], 지식 전달 [4,24]과 layer-wise training [25] 같은 심층 신경망과 을 훈련하기위한 다양한 기술이 제안되었다.
최신 residual networks [11]는 ImageNet 및 COCO 2015 대회에서 큰 성공을 거두었으며 ImageNet 및 CIFAR의 개체 분류, PASCAL VOC 및 MS COCO의 개체 감지를 포함한 여러 벤치 마크 테스트에서 최신 수준을 달성했다. 그리고 분할. 초기 아키텍처와 비교하여 더 나은 일반화 능력을 보여 주므로 이러한 기능을 전이 학습에서 더 효과적으로 사용할 수 있다. 또한 follow-up 작업은 나머지 링크가 딥 네트워크의 수렴을 가속화한다는 것을 보여준다 [31]. 최근 follow-up 작업은 나머지 네트워크에서 활성화 순서를 탐색하고 나머지 블록에서 identity 매핑을 제안하고 [13] 매우 심층 네트워크의 훈련을 개선했다. 고속도로 망 [28]을 사용하면 나머지 네트워크보다 먼저 제안 된 아키텍처 인 매우 심층적 인 네트워크 [28]를 성공적으로 훈련시킬 수 있습니다. 잔여 네트워크와 도로 네트워크의 근본적인 차이점은 후자의 경우 잔여 링크가 차단되고 이러한 게이트의 가중치가 학습된다는 것이다.
따라서 지금까지 residual networks에 대한 연구는 주로 ResNet 블록 내의 활성화 시퀀스와 residual networks의 깊이에 중점을 두었다. 이 작업에서 우리는 위의 관점을 뛰어 넘는 실험적 연구를 수행하려고합니다. 이를 통해 우리의 목표는 더 풍부한 ResNet 블록 네트워크 아키텍처 세트를 탐색하고 활성화 순서 이외의 여러 측면이 성능에 미치는 영향을 철저히 조사하는 것입니다. 아래에서 설명하는 바와 같이, 이러한 아키텍처 탐색은 residual networks에 대한 새롭고 흥미로운 발견을 이끌어 냈으며, 이는 매우 중요한 실질적인 중요성을 가지고 있습니다.
Width vs depth in residual networks. 머신 러닝에서 얕은 네트워크와 딥 네트워크의 문제는 오랫동안 논의되어 왔으며 [2, 18] 회로 복잡성 이론 문헌에 따르면 얕은 회로는 딥 회로보다 기하 급수적으로 더 많은 구성 요소를 필요로한다는 점을 지적했습니다. residual networks의 작성자는 깊이를 늘리고 매개 변수를 줄이기 위해 가능한 한 얇게 만들려고 노력했으며 심지어 ResNet 블록을 더 얇게 만들기 위해 «bottleneck» 블록을 도입했습니다.
그러나 identity mapping이있는 residual block은 매우 깊은 네트워크의 훈련을 허용하고 residual networks의 약점이기도합니다. gradient 네트워크에서 흐를 때, 어떤 것도 나머지 블록 가중치를 전달하도록 강요 할 수 없으며 훈련 중에 학습하는 것을 피할 수 있으므로 유용한 표현을 학습하는 블록이 몇 개뿐이거나 아주 적은 정보를 공유하는 많은 블록이있을 수 있습니다. 최종 목표에 대한 기여도는 적습니다. 이 질문에서 [28]는 "재사용 감소"로 언급됩니다. [14]의 저자는 훈련 중 남은 블록에 대한 아이디어를 무작위로 비활성화하여이 문제를 해결하려고했습니다. 이 방법은 각 잔여 블록이 단위 스칼라 가중치를 가지며이 가중치에 드롭 아웃이 적용되는 특별한 손실 상황 [27]으로 볼 수 있습니다. 이 방법의 효과는 위의 가설을 입증합니다.
위의 관찰을 바탕으로 우리의 작업은 [13]에 기초하여 깊은 잔차 네트워크가 얼마나 넓어야 하는가에 대한 질문에 답하고 훈련 문제를 해결하려고 노력합니다. 이 경우 ResNet 블록의 확장 (올바르게 처리 된 경우)이 깊이를 증가시키는 것에 비해 나머지 네트워크의 성능을 개선하는 더 효과적인 방법을 제공함을 보여줍니다. 특히 [13]보다 크게 개선 된 더 넓은 딥 레지 듀얼 네트워크를 제안하고, 레이어 수는 50 배, 속도는 2 배 이상 증가한다. 우리는 이것을 widening of ResNet blocks라고 부릅니다. 예를 들어, 우리의 넓은 16-layer deep network 는 훈련 속도가 몇 배 더 빠르지 만 1000-layer thin deep network와 동일한 정확도와 상당한 수의 매개 변수를 가지고 있습니다. 따라서 이러한 유형의 실험은 deep residual networks의 주 에너지가 residual blocks에 있고 깊이의 영향이 보완적임을 보여주는 것으로 보입니다. 원래 매개 변수의 두 배 (또는 그 이상)를 사용하여 더 넓은 잔여 네트워크를 훈련 할 수 있다는 것을 알았습니다. 즉, 성능을 더욱 향상시키기 위해 thin networks의 깊이를 늘려야합니다.이 경우에는 수천 개의 레이어를 추가합니다.
Use of dropout in ResNet blocks.
Dropout은 [27]에서 처음 도입되었고 나중에 [16,26] 등 과 같은 많은 성공적인 아키텍처에서 채택되었으며, 협업 적 적응 및 기능의 과적 합을 방지하기 위해 많은 매개 변수를 사용하여 주로 최상위 계층에 적용됩니다. 그런 다음 주로 batch normalization [15]로 대체되었는데, 이는 특정 분포를 갖도록 신경망 활성화를 정규화하여 내부 공변량 이동을 줄이는 기술입니다. 저자의 실험은 배치 정규화를 사용하는 네트워크가 손실이있는 네트워크보다 정확도가 더 높다는 것을 보여줍니다. 이 예에서는 residual blocks의 확장으로 인한 매개 변수 수가 증가하여 정규화 훈련에 대한 드롭 아웃의 영향과 과적 합 방지를 연구했습니다. 이전에는 [13]에서 나머지 네트워크의 손실을 연구하고 블록의 식별 부분에 드롭 아웃을 삽입했는데 저자는 이 상황의 부정적인 영향을 보여 주었다. 대신, 우리는 드롭 아웃이 컨볼 루션 레이어 사이에 삽입되어야한다고 믿습니다. 넓은 residual 네트워크에 대한 실험 결과는 이것이 일관된 이득과 심지어 새롭고 최신 결과로 이어진다는 것을 보여줍니다 (예를 들어 손실이있는 16 계층 딥 와이드 잔류 네트워크는 SVHN에서 1.64 %의 오류를 가짐).
요약하면 이 작업의 기여는 다음과 같습니다.
잔여 네트워크 구조에 대한 자세한 실험적 연구를 제시하고 ResNet 블록 구조의 몇 가지 중요한 측면을 철저히 조사합니다.
ResNet 블록에 대한 새로운 확장 아키텍처를 제안하여 나머지 네트워크의 성능을 크게 향상시킬 수 있습니다.
우리는 훈련 중 과적 합을 방지하기 위해 적절하게 정규화하기 위해 deep residual networks의 드롭 아웃 현상을 활용하는 새로운 방법을 제안합니다.
마지막으로 제안 된 ResNet 아키텍처가 여러 데이터 세트에서 최신 결과를 달성하여 잔여 네트워크의 정확성과 속도를 크게 향상 시켰음을 보여줍니다.
2 Wide residual networks
identity mapping이있는 Residual block은 다음 공식으로 표현할 수 있습니다.


Residual network는 sequentially stacked residual blocks으로 구성되여 있다.
In [13] residual networks 두가지 타입의 block으로 구성되여 있다.
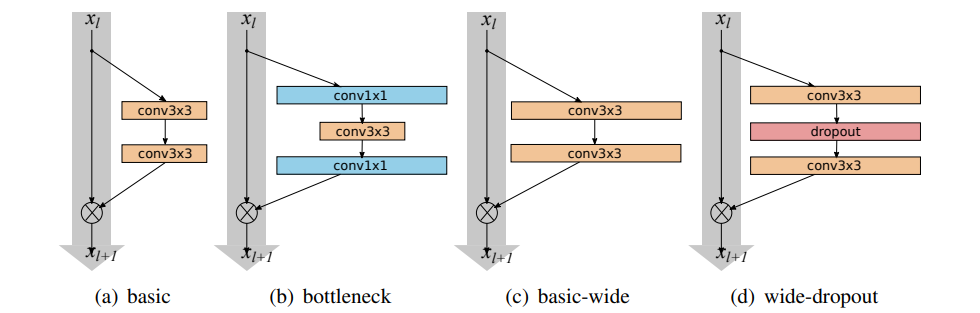
• 기본- with two consecutive 3 × 3 convolutions with batch normalization and ReLU preceding convolution: conv3×3-conv3×3 Fig.1(a)
• bottleneck - with one 3 × 3 convolution surrounded by dimensionality reducing and expanding 1×1 convolution layers: conv1×1-conv3×3-conv1×1 Fig.1(b)

[13]의 원래 아키텍처 [11]와 비교하여 나머지 블록의 배치 정규화, 활성화 및 컨볼 루션 순서는 conv BN ReLU에서 BN-ReLU-conv로 변경됩니다. 후자는 더 빠른 훈련 속도와 더 나은 결과를 가지고 있기 때문에 우리는 원래 버전을 고려하지 않습니다. 또한, 소위 «bottleneck»블록은 원래 블록의 계산 비용을 줄여 레이어 수를 늘리는 데 사용되었습니다. 확장의 효과와 네트워크를 더 얇게 만드는 데 사용되는 «bottleneck»을 연구하고자하므로 고려하지 않고 «basic» residual 구조에 초점을 맞 춥니다.
기본적으로 나머지 블록의 표현 능력을 높이는 세 가지 간단한 방법이 있습니다.
• to add more convolutional layers per block
• to widen the convolutional layers by adding more feature planes
• to increase filter sizes in convolutional layers
작은 필터는 [26,31]을 포함한 많은 프로젝트에서 매우 효과적인 것으로 입증되었으므로 3x3보다 큰 필터는 사용하지 않습니다. 또한 심화 계수 l과 확대 계수 k의 두 가지 요인을 소개합니다. 여기서 l은 블록의 컨볼 루션 수이고 k는 컨벌루션 계층의 특징 수로 곱해 지므로베이스 라인«기본»블록은 l = 2, k에 해당합니다. = 1. 그림 1 (a)와 1 ©은 각각«basic»및«basic wide»블록의 개략적 인 예를 보여줍니다.
residual networks 의 일반적인 구조는 표 1에 나와 있습니다. 초기 convolutional layer conv1, 그 다음 residual blocks conv2, conv3 및 conv4 (각 크기는 N), 평균 풀 및 최종 분류 레이어로 구성됩니다 . 모든 실험에서 conv1의 크기는 고정되고 도입 된 확장 계수 k는 conv2-4의 세 그룹에서 나머지 블록의 너비를 조정합니다 (예 : 원래의 "기본"아키텍처는 k = 1과 동일 함). 잔여 블록의 표현력이 미치는 영향을 연구하고자합니다.이를 위해«Basic»아키텍처를 몇 가지 수정하고 테스트했습니다. 이러한 수정 사항은 다음 하위 섹션에서 자세히 설명합니다.
2.1 Type of convolutions in residual block
B (M)은 resisdual 블록 구조를 나타내며, 여기서 M은 block에있는 convolutional layers의 kernel sizes 목록입니다. 예를 들어, B (3,1)은 3x3 및 1x1 convolutional layers가있는 resisdual 블록을 나타냅니다 (우리는 항상 공간 커널이 정사각형이라고 가정합니다). 앞에서 설명한«bottleneck»블록을 고려하지 않았기 때문에 기능 평면의 수는 블록 전체에서 일정하게 유지됩니다. 우리가 대답하고 싶은 질문은 "기본"잔류 아키텍처의 3x3 컨벌루션 레이어가 얼마나 중요한지, 그리고 더 저렴한 1x1 레이어 또는 1x1 및 3x3 컨볼 루션 레이어에 대해 계산할 수 있는지 여부입니다. 조합으로 대체됩니다 (예 : B (1,3) 또는 B (1,3)). 이것은 블록의 힘을 증가 시키거나 감소시킬 수 있습니다. 따라서 다음 조합으로 실험했습니다 (마지막 조합, 즉 B (3,1,1)은 네트워크 [20] 아키텍처의 유효 네트워크와 유사합니다).
1. B(3,3) - original «basic» block
2. B(3,1,3) - with one extra 1×1 layer
3. B(1,3,1) - with the same dimensionality of all convolutions, «straightened» bottleneck
4. B(1,3) - the network has alternating 1×1 - 3×3 convolutions everywhere
5. B(3,1) - similar idea to the previous block 6. B(3,1,1) - Network-in-Network style block
2.2 Number of convolutional layers per residual block
또한 block deepening factor l을 사용하여 성능에 미치는 영향을 테스트합니다. 매개 변수 수가 동일한 네트워크간에 비교를 수행해야하므로이 경우 l과 d (d는 총 블록 수를 나타냄)가 다른 네트워크를 구축하는 동시에 네트워크 복잡성이 거의 동일하게 유지되도록해야합니다. 이는 예를 들어 l이 증가하면 d가 감소해야 함을 의미합니다.
2.3 Width of residual blocks
위의 수정 외에도 블록 확장 계수 k에 대한 실험도 수행했습니다. 매개 변수 수가 l (deepening factor) ) 및 d (ResNet 블록 수)에 따라 선형 적으로 증가하면 GPU가 큰 텐서에서 병렬 컴퓨팅에 더 효율적이기 때문에 매개 변수 수와 계산 복잡성은 k에서 2 차가됩니다. , 그래서 우리는 최고의 d / k 비율에 관심이 있습니다.
wider residual networks에 대한 한 가지 주장은 [13]에 비해 가장 성공적인 초기 Inception [30] 및 VGG [26]를 포함하여 잔여 네트워크의 거의 모든 이전 아키텍처가 훨씬 더 넓다는 것입니다. 예를 들어 residual networks WRN-22-8 및 WRN-16-10 (이 기호에 대한 설명은 다음 단락 참조)은 너비, 깊이 및 매개 변수 수에서 VGG 아키텍처와 매우 유사합니다.
또한 k = 1 인 original residual networks를 «thin» 네트워크로, k> 1 인 네트워크를 «wide»네트워크라고합니다. 이 기사의 나머지 부분에서는 다음 표기법을 사용합니다. WRN-nk는 총 컨볼 루션 레이어 수 n과 확장 계수 k가있는 resisdual 네트워크를 나타냅니다 (예를 들어, 40 개 레이어와 k = 2 배인 네트워크가 원래 레이어로 표시됩니다. WRN-40-2로). 또한 해당하는 경우 WRN-40-2-B (3,3)와 같은 블록 유형을 첨부합니다.


2.4 Dropout in residual blocks
매개 변수가 증가함에 따라 regularization 방법을 연구하려고합니다. Residual networks는 일괄 표준화되어 정규화 효과를 제공하지만 많은 데이터 확장이 필요하므로 피해야하며 항상 가능한 것은 아닙니다. 그림 1 (d)에서 볼 수 있듯이 ReLU 이후, convolution 사이의 각 resisdual 블록에 드롭 아웃 계층을 추가하여 다음 resisdual 블록에서 배치 정규화를 perturb시키고 과적 합을 방지합니다. very deep residual networks에서 이는 감소 된 기능 재사용 문제를 처리하고 다른 resisdual 블록에서 학습을 강제하는 데 도움이 될 것입니다.
3 Experimental results
실험에서 유명한 CIFAR-10, CIFAR-100, SVHN 및 ImageNet 이미지 분류 데이터 세트를 선택했습니다. CIFAR-10 및 CIFAR-100 데이터 세트 [17]는 10 개 및 100 개 레벨에서 추출한 32x32 컬러 이미지로 구성되며 이러한 이미지는 50,000 개의 기차 이미지와 10,000 개의 테스트 이미지로 나뉩니다. 데이터 향상을 위해 우리는 horizontal flips를 수행하고 각면에 4 픽셀로 채워진 이미지에서 무작위로 자르고 누락 된 픽셀을 원본 이미지의 반사로 채 웁니다. 우리는 [9]에서 제안 된 무거운 데이터 증가를 사용하지 않았습니다. SVHN은 훨씬 더 어려운 실제 문제에서 가져온 약 600,000 개의 디지털 이미지를 포함하는 Google 스 Street View House Numbers 이미지의 데이터 세트입니다. SVHN 실험에서는 이미지를 255로 나누어 [0,1] 범위의 이미지를 입력으로 제공한다는 점을 제외하고는 이미지 전처리를 수행하지 않습니다. ImageNet을 제외한 모든 실험은 [13] 아키텍처의 사전 활성화 된 잔여 블록을 기반으로하며이를 기준으로 사용합니다. ImageNet의 경우 계층이 100 개 미만인 네트워크에서 사전 활성화를 사용해도 큰 차이가 없음을 발견 했으므로이 예제에서는 원래 ResNet 아키텍처를 사용하기로 결정했습니다. 달리 명시되지 않는 한, CIFAR의 경우 [8]의 이미지 전처리 및 ZCA 화이트닝을 따릅니다. 그러나 일부 CIFAR 실험의 경우 간단한 평균 / 표준 표준화를 사용하므로이 전처리를 사용하는 [13] 및 기타 ResNet 관련 작업과 직접 비교할 수 있습니다.
다음에서는 다양한 ResNet 블록 구조에 대한 결과를 설명하고 제안 된 넓은 resisdual 네트워크의 성능을 분석합니다. "블록 내 컨볼 루션 유형"및 "블록 당 컨볼 루션 수"와 관련된 모든 실험에 대해 훈련 속도를 높이기 위해 k = 2를 사용하고 [13]에 비해 감소 된 깊이를 사용합니다.
Type of convolutions in a block
먼저 다른 블록 유형 B의 훈련 된 네트워크를 사용하여 결과를 보고합니다 (보고 된 결과는 CIFAR-10에 있음). 블록 B (1,3,1), B (3,1), B (1,3) 및 B (3,1,1)에 대해 WRN-40-2를 사용합니다. 회선. 매개 변수 수의 비교 가능성을 유지하기 위해 WRN-28-2-B (3,3) 및 WRN-22-2-B (3,1,3)의 더 적은 계층으로 다른 네트워크를 훈련했습니다. 평균 5 회 테스트의 정확도와 각 교육 단계의 시간을 포함하여 표 2에 테스트 결과를 제공합니다. 블록 B (3,3)의 정확도는 B (3,1,3)의 정확도와 매우 유사하며 매개 변수와 레이어 수가 적습니다. B (3,1,3)은 다른 방법보다 약간 빠릅니다.
위의 결과를 바탕으로 비슷한 수의 매개 변수를 가진 블록에 대해 얻은 결과는 거의 동일합니다. 이 사실로 인해 다른 방법과 일관성을 유지하기 위해 3x3 컨볼 루션 만있는 WRN에 대한주의를 제한합니다.
Number of convolutions per block
다음으로 deepening factor l (각 블록의 컨볼 루션 레이어 수를 나타냄) 변경과 관련된 실험을 계속 진행합니다. 표 3에 표시 결과를 제공했습니다.이 예에서는 3x3 컨볼 루션으로 WRN-40-2를 사용하고 다른 심화 계수 l∈ [1,2,3,4]로 여러 훈련을 수행합니다. , 동일한 수의 매개 변수 (2.2 × 10 ^6) 및 동일한 수의 convolutional layers.
B (3,3)의 성능이 가장 좋은 반면 B (3,3,3) 및 B (3,3,3,3)의 성능이 가장 낮다는 것을 알 수 있습니다. 이는 마지막 두 경우에 남아있는 연결 수가 감소하여 최적화의 어려움이 증가했기 때문일 수 있습니다. 또한 B (3)의 상황은 더 나쁩니다. 결론은 B (3,3)이 각 블록의 컨볼 루션 수 측면에서 최적이라는 것입니다. 따라서 나머지 실험에서는 B (3,3) 유형 블록이있는 넓은 잔차 네트워크 만 고려합니다.
Width of residual blocks
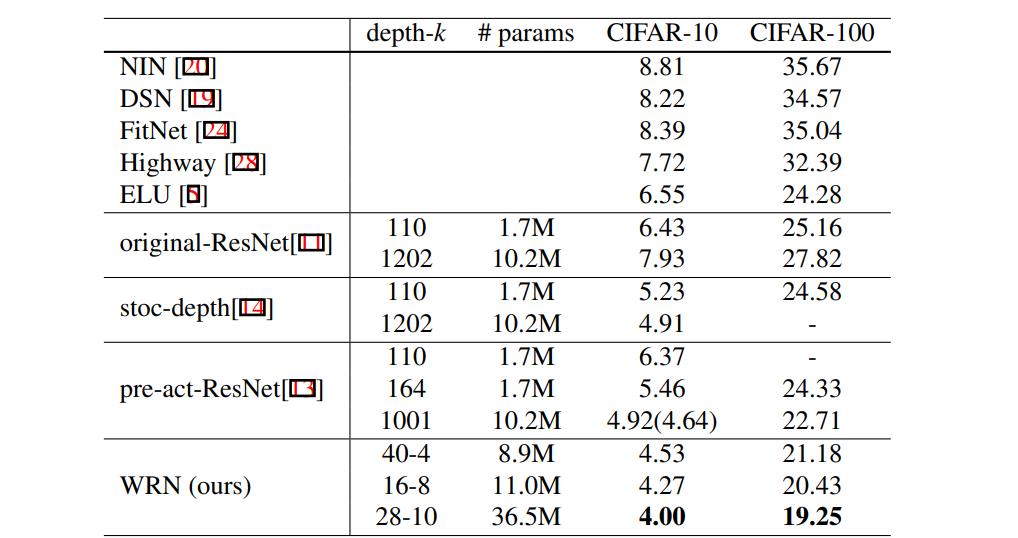
확대 매개 변수 k를 늘리려 고 할 때 총 레이어 수를 줄여야합니다. 최적의 비율을 찾기 위해 k를 2에서 12로, 깊이를 16에서 40으로 실험했습니다. 결과를 표 4에 나타냈다. 폭이 1 ~ 12 배 증가하면 40, 22, 16 계층의 모든 네트워크에서 일관된 이득을 볼 수 있음을 알 수 있습니다. 반면에 동일한 고정 확장 계수 k = 8 또는 k = 10을 유지하고 깊이를 16에서 28로 변경하면 지속적으로 개선되지만 깊이를 40으로 더 늘리면 정확도가 감소합니다 ( 예를 들어 WRN-40-8의 정확도는 WRN-22-8로 감소합니다.
다른 결과는 표 5에 나와 있습니다. 표 5에서는 thin resisdual 네트워크와 wide resisdual 네트워크를 비교합니다. wide WRN-40-4는 CIFAR-10과 CIFAR-100 모두에서 더 나은 정확도를 가지고 있기 때문에 thin ResNet-1001보다 낫다는 것을 알 수 있습니다. 그러나 이러한 네트워크에 8.9x10^6 및 10.2x10^6이라는 비슷한 수의 매개 변수가 있다는 것이 흥미 롭습니다. 이는이 수준에서 깊이가 너비에 비해 정규화 효과를 증가시키지 않음을 보여줍니다. 벤치 마크 포인트에서 더 살펴 보았 듯이 WRN-40-4의 훈련 속도는 원본의 8 배이므로 원본 씬 잔여 네트워크의 종횡비가 최적과는 거리가 멀다는 것이 분명합니다.
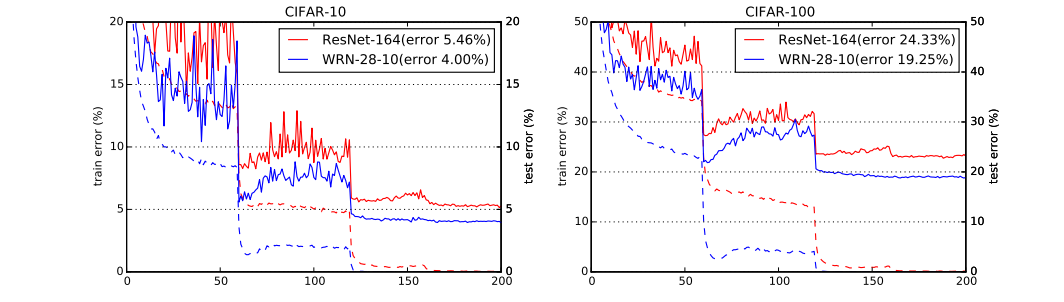
또한 CIFAR-10에서 wide WRN-28-10의 성능은 thin ResNet-1001보다 0.92 % 더 우수하고 (훈련 중 동일한 미니 배치 크기로) CIFAR-100에서는 wide WRN-28-10이 thin ResNet-1001보다 우수합니다. ResNet-1001은 3.46 % 더 높고 레이어 수가 36 배 적습니다 (표 5 참조). ResNet-1001의 결과는 4.64 %이고 배치 크기는 64 인 반면 모든 실험에서 사용한 배치 크기는 128입니다 (즉, 표 5에보고 된 다른 모든 결과의 배치 크기는 128 임). . 이러한 네트워크의 훈련 곡선은 그림 2에 나와 있습니다.

깊이가 regularization 효과를 생성하고 너비로 인해 네트워크가 과적 합된다는 이전 의견이 있었지만 ResNet-1001보다 몇 배 더 많은 매개 변수를 사용하여 네트워크를 성공적으로 훈련 시켰습니다. 예를 들어, wide WRN-28-10 (표 5) 및 wide WRN-40-10 (표 9)의 매개 변수는 ResNet-1001보다 각각 3.6 배 및 5 배이며, 둘 다 ResNet-1001보다 훨씬 우수한 성능을 보입니다.
일반적으로 CIFAR 평균 / 표준 전처리는 WRN-40-10 및 56x106 매개 변수를 사용하여 CIFAR-100에서 18.3 %를 달성함으로써 더 넓고 깊은 네트워크를 더 정확하게 훈련 할 수 있습니다. (표 9), ResNet-1001보다 4.4 % 높으며이 데이터 세트에 대한 새로운 최신 결과가 확립되었습니다.
결론적으로 :
• widening consistently improves performance across residual networks of different depth;
• increasing both depth and width helps until the number of parameters becomes too high and stronger regularization is needed;
• there doesn’t seem to be a regularization effect from very high depth in residual networks as wide networks with the same number of parameters as thin ones can learn same or better representations. Furthermore, wide networks can successfully learn with a 2 or more times larger number of parameters than thin ones, which would require doubling the depth of thin networks, making them infeasibly expensive to train.
Dropout in residual blocks
모든 데이터 세트의 컨볼 루션 사이에 residual block을 삽입하도록 네트워크를 훈련시킵니다. cross-validation을 사용하여 dropout probability values를 결정합니다. CIFAR은 0.3, SVHN은 0.4입니다. 또한 드롭 아웃이없는 기준 네트워크에 비해 훈련 기간 수를 늘릴 필요가 없습니다.
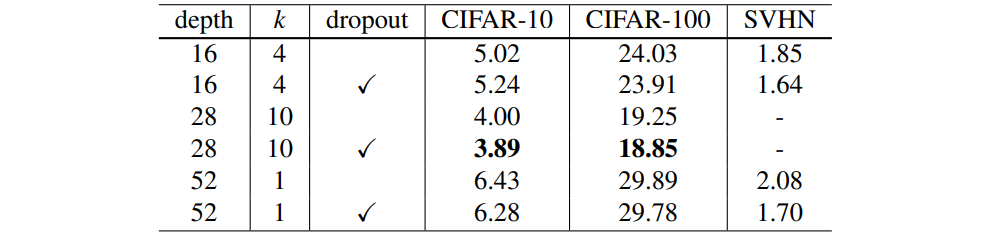
WRN-28-10과 비교하여 손실은 CIFAR-10 및 CIFAR-100의 테스트 오류를 각각 0.11 % 및 0.4 % 감소 (5 회 이상 실행 및 평균 / 표준 전처리의 중앙값)하고 다른 RESNET과 비교합니다. 비교에서도 개선 사항이 있습니다 (표 6). 우리가 아는 한, 이것은 큰 데이터 볼륨 확장 방법보다 훨씬 더 나은 20 % 오류에 가까운 CIFAR-100의 첫 번째 결과입니다. CIFAR-10에서 WRN-16-4의 정확도는 약간만 감소합니다. 이것은 상대적으로 적은 매개 변수 때문이라고 추측합니다.
첫 번째 학습률이 감소한 후 손실 및 검증 오류가 갑자기 증가하고 높은 값으로 진동하면 다음 학습률이 감소 할 때까지 잔여 네트워크 학습이 간섭 효과를 생성한다는 것을 알았습니다. 무게 감쇄로 인해 발생하는 것으로 나타 났지만이를 줄이면 정확도가 크게 저하됩니다. 흥미롭게도 대부분의 경우이 효과를 부분적으로 제거하면 그림 2와 3을 참조하십시오.
dropout가 SVHN에 미치는 영향은 더 분명합니다. 이는 데이터 확장 및 배치 정규화 과적 합을 수행하지 않았기 때문에 드롭 아웃이 정규화 효과를 증가 시켰기 때문일 수 있습니다. 이에 대한 증거는 그림 3의 훈련 곡선에서 찾을 수 있습니다. 여기서 흘리지 않는 손실이 매우 낮은 값으로 떨어집니다. 결과를 표 6에 나타냈다. thin and wide 네트워크에서 드롭 아웃을 사용하는 데있어 상당한 개선이 관찰되었습니다. 임의의 깊이에서 Thin 50-layer deep network는 Thin 152-layer deep network보다 훨씬 좋습니다 [14]. 또한 WRN-16-8 (표 9)에 대한 SVHN dropout 교육도 실시하여 SVHN에 대한 1.54 %에 도달했으며 이는 우리가 알고있는 최고의 공개 결과입니다. dropout 율은 1.81 %입니다.

일반적으로 일부 사람들은 일괄 정규화 결합을지지하지만 드롭 아웃은 이것이 효과적인 씬 네트워크 및 광범위한 네트워크 정규화 기술임을 보여줍니다. 확대 결과를 더욱 향상시키는 데 사용할 수 있으며 보충제로 사용할 수도 있습니다.
ImageNet and COCO experiments
ImageNet의 경우 먼저 병목 현상이없는 ResNet-18 및 ResNet-34로 실험하고 폭을 1.0에서 3.0으로 점진적으로 늘리려 고합니다. 결과를 표 7에 나타냈다. 너비를 늘리면 두 네트워크의 정확도가 점차적으로 증가하고 비슷한 수의 매개 변수를 가진 네트워크는 깊이가 다르더라도 유사한 결과를 얻을 수 있습니다. 이러한 네트워크에는 매개 변수가 많지만 병목 네트워크가 그들보다 낫습니다. 병목 구조가 ImageNet 분류 작업에 더 적합하거나이 복잡한 작업에 더 깊은 네트워크가 필요하기 때문일 수 있습니다. 이를 확인하기 위해 ResNet-50을 채택하고 내부 3x3 레이어의 너비를 늘려 더 넓게 만들려고했습니다. widening factor가 2.0이면 WRN-50-2-bottleneck의 성능이 ResNet-152보다 우수하고 계층 수가 3 배 감소하며 속도가 훨씬 빠릅니다. WRN-50-2- bottleneck은 매개 변수가 약간 더 많음에도 불구하고 성능이 가장 우수한 사전 활성화 된 ResNet-200보다 거의 2 배 더 빠릅니다 (표 8). 일반적으로 CIFAR와 달리 ImageNet 네트워크는 동일한 정확도를 달성하기 위해 동일한 깊이에서 더 큰 너비가 필요하다는 것을 발견했습니다. 그러나 계산상의 이유로 50 개 이상의 레이어가있는 잔여 네트워크를 사용할 필요가 없다는 것은 분명합니다.
8-GPU 시스템이 필요하기 때문에 더 큰 병목 네트워크를 훈련 시키려고하지 않았습니다.


또한 WRN-34-2를 사용하여 MultiPathNet [32] 및 LocNet [7]의 조합을 사용하여 COCO 2016 Object Detection Challenge에 참여했습니다. 레이어가 34 개에 불과하지만이 모델은 가장 진보 된 단일 모델 성능을 달성하며 ResNet-152 및 Inception-v4 기반 모델보다 훨씬 좋습니다.
마지막으로 표 9에는 일반적으로 사용되는 다양한 데이터 세트에 대한 최상의 WRN 결과가 요약되어 있습니다.

Computational efficiency
Thin 잔여 네트워크와 적은 수의 코어가있는 깊은 잔여 네트워크는 시퀀스 구조로 인해 GPU 컴퓨팅의 특성에 반합니다. 너비를 늘리면보다 최적화 된 방식으로 계산의 균형을 효과적으로 조정하는 데 도움이되므로 벤치 마크 테스트에서 알 수 있듯이 넓은 네트워크의 효율성은 씬 네트워크의 몇 배입니다. cudn v5 및 Titan X를 사용하여 여러 네트워크의 forward+backward 업데이트 시간 (미니 배치 크기 32)을 측정하며 그 결과는 그림 4에 나와 있습니다. 우리는 최고의 CIFAR wide WRN-28-10이 thin ResNet-1001보다 1.6 배 빠르다는 것을 보여줍니다. 또한 Wide WRN-40-4의 정확도는 ResNet-1001과 거의 동일하며 속도는 ResNet-1001의 8 배입니다.

Implementation details
모든 실험에서 Nesterov momentum 및 cross-entropy loss과 함께 SGD를 사용했습니다. 초기 학습률은 0.1, 가중치 감쇠는 0.0005, dampening 0, momentum 0.9, 미니 배치 크기는 128로 설정됩니다. CIFAR에서 학습률은 60, 120, 160 epoch에서 0.2 감소했으며 총 200 epoch 동안 훈련했습니다. SVHN에서 초기 학습률은 0.01로 설정되어 있으며 총 160주기의 훈련을 위해 80 및 120주기에서 0.1만큼 감소시킵니다. 우리의 구현은 Torch [6]를 기반으로합니다. 모든 네트워크의 메모리 공간을 줄이기 위해 [21]을 사용합니다. ImageNet 실험 fb.resnet.torch를 사용하여 [10]을 구현합니다. 우리의 코드와 모델은 https://github.com/szagoruyko/wide-residual-networks에서 확인할 수 있습니다.
4 Conclusions
We presented a study on the width of residual networks as well as on the use of dropout in residual architectures. 이 연구를 기반으로 우리는 일반적으로 사용되는 여러 벤치 마크 데이터 세트 (CIFAR-10, CIFAR-100, SVHN 및 COCO 포함)의 최신 결과를 제공하고 ImageNet을 크게 개선 한 광범위한 잔여 네트워크 아키텍처를 제안합니다. . CIFAR에 16 개 계층 만있는 광역 네트워크의 성능이 1000 계층 딥 네트워크의 성능보다 훨씬 우수하다는 것을 증명했으며, ImageNet에서는 50 계층 네트워크의 성능도 152 계층 네트워크의 성능보다 뛰어나 나머지 네트워크의 주요 기능이 나머지에 있음을 나타냅니다. 앞에서 설명한대로 극단적 인 깊이가 아닌 차단합니다. 또한 넓은 잔여 네트워크의 훈련 속도는 몇 배 더 빠릅니다. 우리는 이러한 흥미로운 발견이 심층 신경망 연구의 발전에 도움이 될 것이라고 생각합니다.
5 Acknowledgements
우리는 스타트 업 VisionLabs와 Eugenio culuciello가 클러스터에 액세스 할 수 있도록 해주신 것에 감사 드리며, 이들 없이는 ImageNet 실험이 불가능할 것입니다. 또한 유용한 토론에 대해 Adam Lele과 Sam Gross에게 감사드립니다. Work supported by EC project FP7-ICT611145 ROBOSPECT.