[논문]Deep Residual Learning for Image Recognition
Microsoft Research
Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun
residual learning framework
residual function
stacking more layer : vanishing/exploding gradients
deeper network : accuracy gets saturated => overfitting 이 아니다.
shortcut connections
identity mappings
Abstract

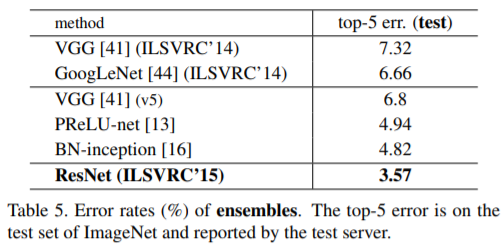
neural networks는 깊으면 깊을수록 학습하기 힘들다. 우리는 이전 연구에서 사용된 네트워크들보다 훨씬 학습하기 용이한 residual learning framework 을 제안한다. 여기서 우리는 unreferenced functions을 학습하는 대신, layer의 input을 참조하는 residual function을 명시적으로 재구성한다. 우리가 제공하는 residual networks 는 optimize하기도 쉬우며, 상당히 깊은 네트워크의 경우에도 합리적인 정확도를 얻어낼 수 있음을 실험 결과로 보여준다. ImageNet dataset에서는 VGG nets [41](still having lower complexity ) 보다 8배 깊은 152 layers ResNet을 평가하였다. 이들 residual nets 과 앙상블을 한 결과 ImageNet test set에서 3.57%의 top-5 error를 보였다. the ILSVRC 2015 classification task에서 1등을 하였다. 우리는 CIFAR-10 with 100 and 1000 layers 에서도 분석하였다.
depth of representations는 다양한 visual recognition tasks 에서 매우 중요한 역할을 한다. residual network로부터 얻어낸 deep representation으로부터 COCO object detection dataset에서 28%의 개선 효과를 얻었다. Deep residual network의기초는 ILSVRC & COCO 2015 competitions 에 제출하였다. ImageNet detection/localization, COCO detection/segmentation부문에서 1위를 차지했다.
1. Introduction





Deep convolutional neural networks [22, 21]의 는 image classification [21, 50, 40]에서 여러가지 돌파구로 이어졌다 . Deep networks 는 low/mid/highlevel features [50]와 classifiers를 end-to-end multi-layer fashion으로 자연스럽게 통합하며, 각 features 들의 풍부한 ‘level’은 해당 feature를 추출하기 위해 stacked layer의 depth에 따라 달라진다. 최근의 증거 [41, 44] 따르면 network depth은 결정적 중요하며 , challenging ImageNet dataset [36]의 주요 결과[41, 44, 13, 16] 들은 모두 depth가 16 [41]~30[16] 정도인 “very deep” [41]을 활용했다. 다른 non-trivial visual recognition [8, 12, 7, 32, 27] 에서도 ‘very deep’ model이 큰 도움이 됐다. 깊이의 중요성에 따라 다음과 같은 의문이 생긴다.
더 나은 네트워크를 배우는 것이 stacking more layers 쉬운가? 이 질문에 대한 걸림돌은 처음부터 수렴을 방해하는 vanishing/exploding gradients [1, 9] 의 악명 높은 문제점이 있다. 그러나 이 문제는 주로 normalized initialization [23, 9, 37, 13]와 intermediate normalization layers [16]에 의해 해결되었으며, 이 계층의 수십개의 layers가 있는 network의 back-propagation [22]를 통해 stochastic gradient descent (SGD)에 대한 수렴을 하게 한다.
deeper networks가 수렴하기 시작할 때, 또 다른 성능 저하 문제가 드러난다. 이는 network depth 가 늘어남에 따라
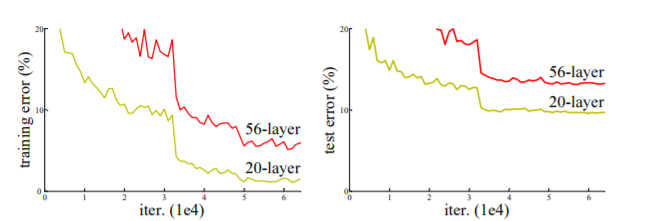
정확도가 포화상태(놀랍지 않을 수 있습니다)에 도달하게 되면 성능이 급격하게 떨어지는 현상을 말한다. 놀랍게도 , 하락문제는 overfitting 때문에 생긴것이 아니라 , depth가 적절히 설계된 모델에 더 많은 layer를 추가하면 training error가 커진다는 이전 연구[11, 42] 결과에 기반한다. 아래 Fig.1에서는 간단한 실험을 통해 성능 저하 문제를 보여준다.
예기치 않게, 그러한 저하는 overfitting 에 의해 야기되지 않으며, 적절히 깊은 모델에 더 많은 레이어를 추가하면 [11, 42]에서 보고되고 우리의 실험에서 철저히 검증된 바와 같이 더 높은 ttraining error 로 이어진다. 그림 1은 대표적인 예이다.( Depth 가 깊어질 수록 높은 training error가 높았으며 이에 따른 test error도 높았다. ) 이와 같은 성능 저하(training accuracy의 ) 문제는, 모든 시스템의 최적화 난이도가 쉬운 것은 아님을 나타낸다. shallower architecture와 deeper model를 추가하는 더 깊은 아키텍처를 고려해보자. 이를 만족하는 deeper architecture를 위한 constructed solution이 있긴 하다. added layers 는identity mapping 이며, other layers 는 shallower architecture에서 복사된다. (기존에 학습된 shallower architecture에다가 identity mapping인 layer만 추가하여 deeper architecture를 만드는 방법이다.) 이미 존재한 constructed solution에서 ej deeper model 이 shallower counterpart 보다 더 높은 training error 를 생성해서는 안 된다는 것을 나타낸다. 하지만, 실험을 통해 현재의 solver들은 이 constructed solution이나 그 이상의 성능을 보이는 solution을 찾을 수 없다는 것을 보여준다(or unable to do so in feasible time).
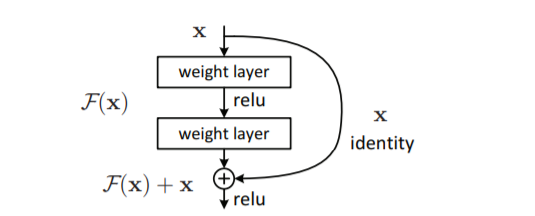
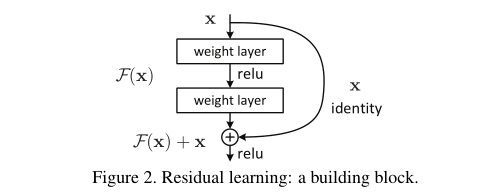
이 논문에서는 우리는 deep residual learning framework을 도입하여 성능 저하 문제를 다룬다. 이 방법은 few stacked layer를 underlying mapping을 직접 학습하지 않고, residual mapping에 맞추어 학습하도록 한다. 공식적으로, 원하는 underlying mappin을 H(x)로 나타낸다면, stacked nonlinear layer의 mapping인 F(x)는 H(x)-x 를 학습하는 것이다. F(x) := H(x)−x 따라서 original mapping은 F(x)+x 로 재구성 된다. 또한, 저자들은 unreferenced mapping인 original mapping보다, residual mapping을 optimize하는 문제가 더 쉽다고 가정한다. 극단적으로 identity mapping 이 optimal일 경우 , nonlinear layers stack에 의한 identity mapping을 맞추는 것보다 residual 0으로 밀어넣는 것이 더 쉬울 것이다. F(x)+x의 공식은 “shortcut connections” 이 있는 feedforward neural networks 으로 구현할 수 있다(Fig. 2). Shortcut connections [2, 34, 49]는 하나 이상의 계층을 건너뛴다. 우리의 예에서는 , shortcut connection은 단순한 identity mapping을 수행하고, 그 출력을 stacked layer의 출력에 더하고 있다(Fig. 2). 이와 같은 identity shortcut connection은 별도의 parameter나 computational complexity가 추가되지 않는다. 전체 네트워크는 여전히 backpropagation를 통해 SGD에 의해 end-to-end 로 학습이 가능하며, solver 수정 없이도 common library를 사용하여 쉽게 구현할 수 있다 (e.g., Caffe [19]).
우리는 degradation problem를 보여주고 방법을 평가하기 위해 , ImageNet[36]에 대한 comprehensive experiments을 제시한다.
우리는 다음과 같이 보여준다.
1). 우리의 extremely deep residual nets을 최적화하기 쉽지만, 상대적인 “plain” nets (that simply stack layers)은 깊이가 증가할때 더 높은 training error를 나타낸다.
2). deep residual nets는 훨씬 더 깊어진 깊이에서 정확도 향상을 쉽게 누릴 수 있어며 , 이전 네트워크보다 훨씬 향상된 결과를 얻을 수 있다.
CIFAR-10 set[20]에도 유사한 현상이 나타나는데, 이는 우리 방법의 최적화 어려움과 효과가 특정 데이터 세트와만 유사한 것이 아님을 시사한다.우리는 100 이상의 layers를 가진 이 데이터 세트에 대해 성공적으로 훈련된 모델을 제시하고 1000개 이상의 레이어를 가진 모델을 탐색한다.
ImageNet classification dataset [36]에서, 우리는 extremely deep residual nets를 통해 우수한 결과를 얻었다. 우리의 152-layer residual net 는 VGG nets [41]보다 complexity보다 여전히 낮으면서도 ImageNet에 제공된 네트워크 중 가장 깊다. 우리의 ensemble 모델은 ImageNet test set에서 3.57% top-5 error를 기록했으며, ILSVRC 2015 classification competition에서 1등을 차지했다. 또한 extremely deep representations은 other recognition tasks에서 탁월한 성능을 가지고 있으며, ILSVRC & COCO 2015 competitionsImageNet detection, ImageNet localization, COCO detection, and COCO segmentation 부문에서 1등을 차지했다. 이 strong evidence는 residual learning principle이 일반적이라는 것을 보여주며 , 우리는 그것이 다른 시각 및 비전 문제에 적용될 수 있을 것으로 기대한다.
2. Related Work



Residual Representations.
In image recognition에서 VLAD [18]는 dictionary에 대한 residual vectors로 encodes 하는 표현이며, Fisher Vector [30]은 VLAD의 probabilistic version [18] 으로 공식화할 수 있다. 둘 다 image retrieval and classification [4, 48] 를 위한 강력하고 얕은 표현이다. vector quantization의 경우, residual vectors [17]를 encoding 하는 것이 original vectors를 encoding하는 것보다 더 효과적이다.
low-level vision 과 computer graphics에서 Partial Differential Equations (PDEs)를 해결하기 위해, 널리 사용되는 Multigrid method [3] 은 시스템을 multiple scales에서 subproblems 로 재구성하며, 여기서 각 subproblems 는 a coarser와 a finer scale 사이의 residual solution을 담당한다. Multigrid 의 대안으로는 hierarchical basis pre-conditioning [45, 46]가 있는데 , two scales사이의 residual vectors를 나타내는 변수에 의존한다. [3,45,46] these solvers는 residual nature of the solutions을 인식하지 못하는 standard solvers보다 훨씬 빠르게 수렴하는 것으로 나타났다.
Shortcut Connections.
shortcut connections [2, 34, 49]로 이어지는 Practices and theories은 오래 동안 연구되어 왔다. multi-layer perceptrons(MLPs) 을 학습하는 초기 방법은 네트워크 입력에서 출력 [34, 49]으로 연결된 a linear layer를 추가하는 것이다. [44, 24]에서 , a few intermediate layers은 vanishing/exploding gradients를 다루기 위한 auxiliary classifiers에 연결된다. [39, 38, 31, 47]의 논문은 shortcut connections에 의해 구현되는 layer responses, gradients, and propagated errors의 중심을 맞추는 방법을 제안한다. [44]에서 “inception” layer은 a shortcut branch and a few deeper branches로 구성된다.
본 연구와 동시에 , “highway networks” [42, 43]는 gating functions [15]과의 shortcut connections를 제공한다. 이러한 gates는 data-dependent이며 parameter-free our identity shortcuts달리 parameters를 가지고 있다. gated shortcut is “closed” (approaching zero)일 때, highway networks의 layer은 non-residual functions를 나타낸다. 반대로 , 위리의 공식은 항상 residual functions를 학습한다 : 우리의 identity shortcuts가 결코 닫히지 않으며, 모든 정보는 항상 전달되며 additional residual functions 를 학습한다. 또한 high-way networks 는 극단적으로 increased depth (e.g., over 100 layers)에도 정확성을 보여주지 않았다.
3. Deep Residual Learning






3.1. Residual Learning
H(x)를 몇 개의 stacked layers(꼭 전체 네트는 아님) 에 의해 적합한 underlying mapping 으로 간주하고, x는 이러한 레이어 중 첫 번째 레이어에 대한 입력을 나타낸다. 만약 multiple nonlinear layers이 complicated functions 2에 점근적으로 근사할 수 있다는 가설이 있다면, H(x) − x (assuming that the input and output are of the same dimensions)와 같은 점근적으로 근사할 수 있다는 가설과 같다. 따라서 stacked layers 이 대략 H(x)일 으로 예상하는 대신, 우리는 이 layers들이 residual function F(x) := H(x) − x에 근접하도록 명시적으로 한다. 따라서 original function는 F(x)+x가 된다. 비록 두 형태 모두 (as hypothesized) 로 원하는 기능을 점근적으로 근사할 수 있어야 하지만, 학습의 용이성은 다를 수 있다.
이 reformulation 는 degradation problem에 대한 counterintuitive phenomena의해 자극을 받는다(Fig. 1, left). introduction에서 논의 한것과 같이 , added layers이 identity mappings으로 구성될 수 있다면, deeper model 은 shallower counter-part보다 training error를 가져야 한다. degradation problem는 solvers 가 여러 nonlinear layers에 의한 identity mappings을 근사화하는데 어려움이 있을 수 있음을 시사한다.residual learning을 통해 , identity mappings이 최적인 경우, solvers 는 단순히 identity mappings에 접근하기 위해 multiple nonlinear layers weights 를 0으로 유도할 수 있다.
실제의 경우, identity mappings이 최적일 가능성이 낮지만, 우리의 reformulation은 문제를 precondition 하는 데 도움이 될 수 있다. optimal function가 zero mapping보다 identity mapping이 더 가까울 경우, solver 는 새로우 기능으로 함수를 학습하는 것보다 identity mapping을 참조하여 perturbations 을 찾는 것이 더 쉬워야 한다.
실험에서는 학습된 residual function에서 일반적으로 작은 반응이 있다는 결과를 보여준다(Fig.7 참조). 이 결과는 identity mapping이 합리적인 preconditioning을 제공한다는 것을 시사한다. 우리는 실험(Fig.7)을 통해 , 학습된 residual functions가 일반적으로 작은 반응을 가지고 있다는 것을 보여주며, identity mappings이 합리적인 preconditioning을 제공한다는 것을 시사한다.
3.2. Identity Mapping by Shortcuts
우리는 모든 few stacked layers마다 residual learning을 사용한다. building block은 Fig.2에서 나와있다. 공식적으로 , 이 논문에서는 우리는 a bulding block 을 아래와 같이 정의했다.
y = F(x,{W i }) + x. (1)
x와 y는 각각 building block의 input와 output vector이다.
function F(x,{W_i })는 학습 해야 할 residual mapping이다.
Fig. 2 에서 two layers가 있는 예를 들면, F = W_2 σ(W_1 x)로 나타낼 수 있다.
여기서 σ는 ReLU [29]를 나타내며 간소화를 위해 biases 는 생략되었다.
F + x연산은 shortcut connection 및 element-wise addition으로 수행된다. addition 후에는 second nonlinearity로 ReLU를 적용한다. (i.e., σ(y), see Fig. 2)
Eqn.(1) 의 shortcut connection 연산은 별도의 parameter나 computational complexity가 추가되지 않는다. 이는 실제로 매력적일 뿐만 아니라 plain network와 residual network 간의 를 비교하는 데에도 중요하다.(공정한 비교를 가능하게 해준다. ) 우리는 parameters의 수, depth, width, 및 computational cost(except for the negligible element-wise addition-> element-wise addition은 무시할 정도이다. ) 동일한 plain/residual networks를 공정하게 비교할 수 있다.
Eqn.(1)에서 x와 F의 dimensin이 같아야 한다. 그렇지 않은 경우 (예: 입력/출력 채널을 변경할 때), shortcut connections을 통해 a linear projection W_s 를 수행하여 dimensions maching 시킬 수 있다.
y = F(x,{W i }) + W s x. (2)
Eqn.(1)에서 square matrix W_s를 사용할 수 있다. 하지만 우리는 실험을 통해 identity mapping이 degradation problem를 해결하기에 충분하고 경제적이므로 W_s는 dimensions maching 시킬 때만 사용하는 것을 보여줄 수 있다.
residual function F 의 형태는 유연하게 결정할 수 있다. 즉, 본문에서는 two or three layers (Fig. 5)가 function F를 사용하지만, 더 많은 layer를 포함하는 것도 가능하다. 하지만, F가 단 하나의 layer만 갖는 경우에는 Eqn.(1)은 단순 linear layer와 유사하다. y = W_1 x+x 이 layer에서는 이점을 관찰하지 못했다.
우리는 또한 위의 수식이 단순성을 위해 fully-connected layers에 대한 것이지만, convolutional layers에 적용할 수 있다는 점에 주목한다. function F(x,{W_i })는 multiple convolutional layers를 나타낼 수 있다 . element-wise addition는 channel by channel(channel 별)로 two feature maps에서 수행된다.
3.3. Network Architectures
이 논문에서는 다양한 형태의 plain/residual network에 대해 테스트 했으며, 일관된 현상을 관찰한다. instances for discussion을 증명하기 위하여 , 우리는 ImageNet dataset을 위한 두 모델을 다음과 같이 정의했다.
Plain network
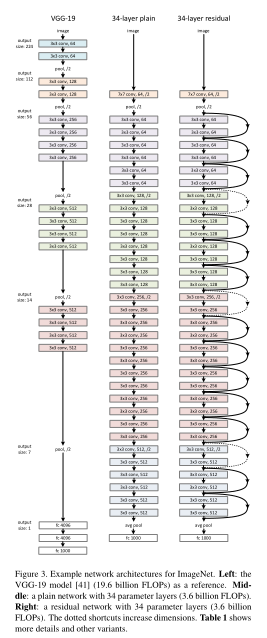
우리의 plain의 baseline(Fig.3 middle)은 주로 VGG net(Fig.3 left)의 철학에서 영감을 받았다. convolutional layers는 대부분 3x3 filter를 가지며, 다음과 같이 두 가지의 간단한 규칙에 따라 디자인 된다.
1). 동일한 output feature map size에 대해, layer의 filters수는 동일하다.
2). feature map size가 절반으로 줄어들 경우, layer 당 time complexity를 보전하기 위해 filter의 수를 2배로 한다.
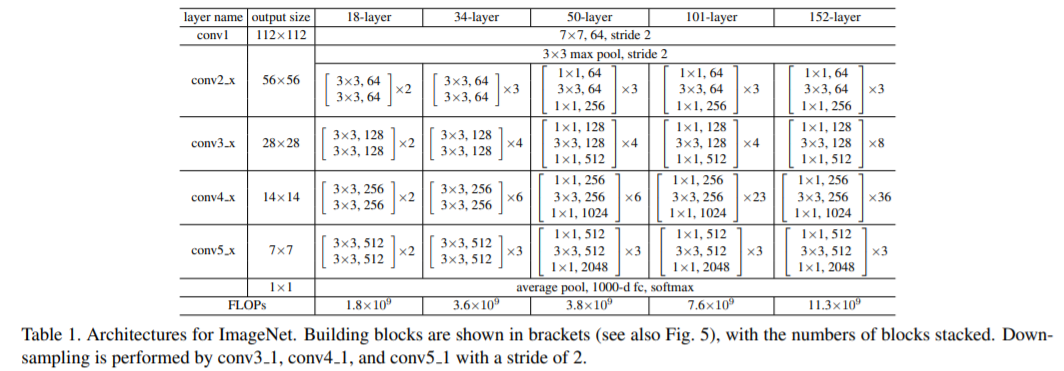
stride 2인 convolutional layers에 의해 직접 downsampling을 사용했다. 네트워크의 마지막에는 global average pooling layer 와 activation이 softmax인 1000-way fully-connected laye로 구성된다 . Fig. 3 (middle)에서 총 weighted layers 수는 34이다. 우리의 모델은 VGG nets [41] (Fig. 3, left)보다 filter수가 작고 complexity 가 lower 다는 것을 주목할 필요가 있다. 우리의 34개의 layer로 구성된 이 baseline plain network(Fig.3 가운데)는 3.6 billion FLOPs이며, 이는 VGG-19(19.6 billion FLOPs)의 18%에 불과하다.
Residual network
위의 plain network의 가반으로, 우리는 shortcut connections((Fig. 3, right) 을 삽입하여 residual version의 network를 만든다. (Fig.3 오른쪽) identity shortcut(Eqn.1)은 input과 output이 동일한 dimension인 경우(Fig.3의 solid line shortcuts)에는 직접 사용할 수 있다.
dimension이 증가하는 경우(Fig.3의 dotted line shortcuts)에는 아래의 두 옵션을 고려한다.
(A) shortcut 는 여전히 identity mapping을 수행하며,
zero entry padding 를 추가되어서 dimensions을 널린다. 이 옵션은 별도의 parameter가 추가되지 않음
(B) Eqn.2의 projection shortcut을 dimension matching에 사용한다. (done by 1x1 convolutions). shortcut connection이 다른 크기의 feature map 간에 mapping될 경우, 두 옵션 모두 strides를 2로 수행한다.
y = F(x,{W i }) + W s x. (2)
FLOPS :플롭스는 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위이다.
3.4. Implementation
논문에서 ImageNet dataset에 대한 실험은 [21, 41] 방법에 따른다. 이미지는 scale augmentation [41]를 위해 [256, 480]에서 무작위하게 샘플링 된 shorter side를 사용하여 rescaling된다. 224x224 crop은 horizontal flip with per-pixel mean subtracted [21] 이미지 또는 이미지에 무작위로 샘플링 된다. standard color augmentation in [21] 도 사용된다. 우리는 [16]에 이어 , 각 convolution 직후와 activation 전에 batch normalization (BN) [16]를 사용했다. [13] 과 같이 weights 를 초기화하고 모든 plain/residual nets를 처음부터 학습한다. 우리는 SGD 사용하고 mini-batch size는 256이다. learning rate는 0.1에서 시작하여, error plateau 나올때 rate를 10으로 나누어 적용하며, 모델은 최대 iteration은 6X10^4회이다. 우리는 weight decay는 0.0001, momentum은 0.9로 한 SGD를 사용했다. [16]의 관례에 따라 dropout[14]을 사용하지 않는다.
테스트에서 , 비교 연구를 위해 , standard 10-crop testing [21]를 채택한다.
최상의 결과를 위해 , 우리는 [41, 13] 와 같은 fully convolutional form 적용하였으며 , multiple scales를 평균화하였다 (images are resized such that the shorter side is in {224, 256, 384, 480, 640}).multiple scale은 shorter side가 {224, 256, 384, 480, 640}인 것으로 rescaling하여 사용한다.
4. Experiments













4.1. ImageNet Classification
우리는 1000 classes로 구성된 ImageNet 2012 classification dataset[36] 에서 제안하는 방법을 평가한다.
모델의 학습및 테스트 에 사용된 데이터는 아래와 같다.
training images : 1.28 million
validation images : 50k
test images images : 100k => final result
테스트 결과는 top-1 error와 top-5 error를 모두 평가한다.
Plain Networks
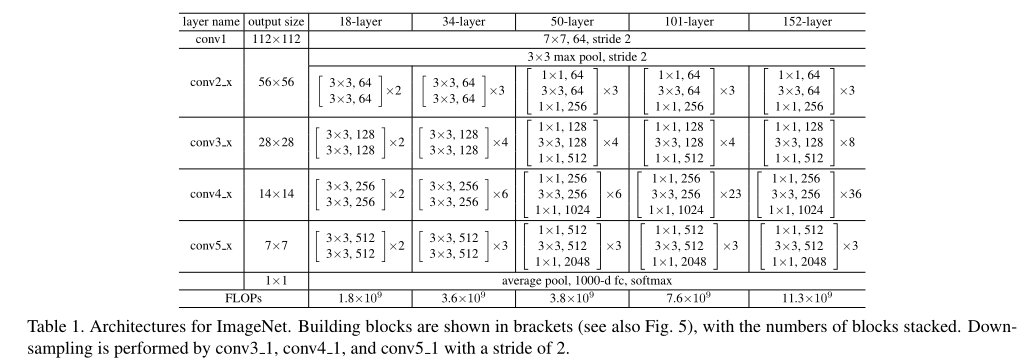
우선 우리는 18-layer and 34-layer plain nets에 대해서 평가한다. 34-layer plain net은 Fig. 3 (middle)에 있다. 18-layer plain net 는 비슷한 형태로 구성된다 . 상세한 구조는 Table 1에서 보여준다.
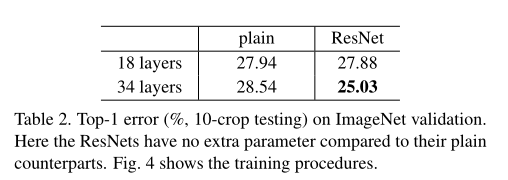
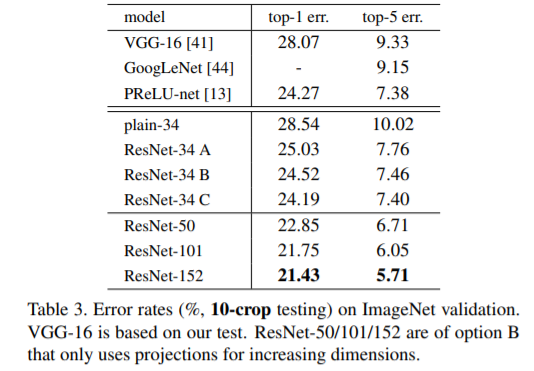
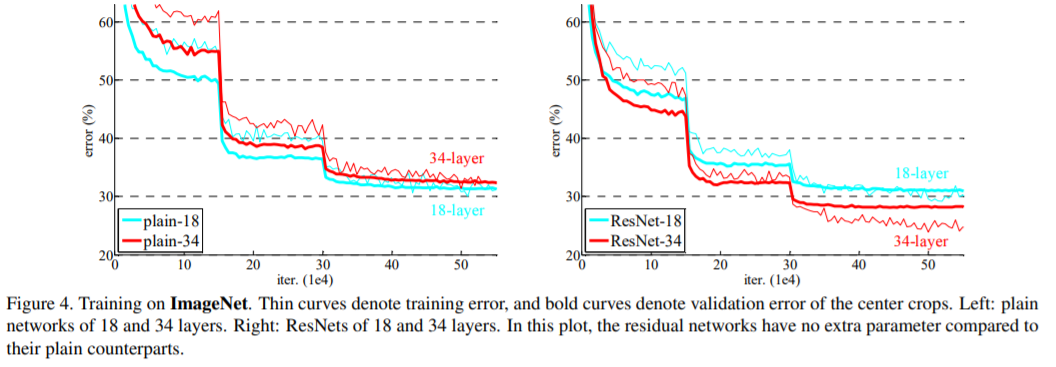
plain net = > Table 2 의 결과에서는 18-layer plain net 에 비해, deeper 34-layer plain net 의 validation error가 높다는 것이다. => deeper 34-layer plain net의 validation error가 높다 .
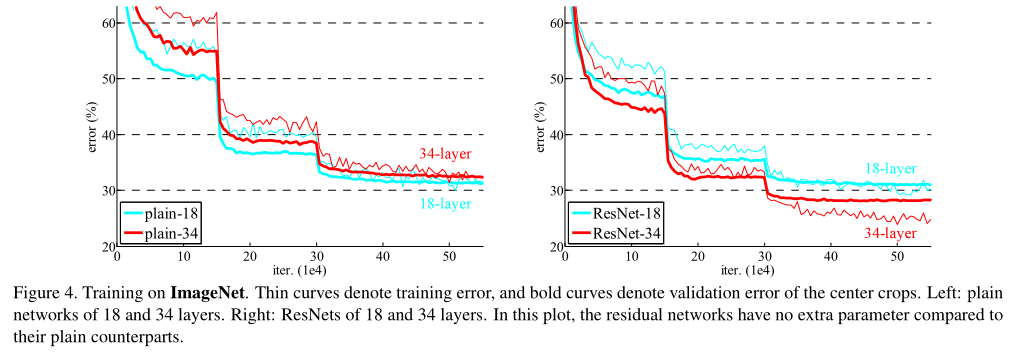
이유를 알아보기 위 Fig. 4 (left)에서 우리는 학습 중의 training/validation error를 비교한다. 우리는 degradation problem 를 관찰했다. - 18-layer plain network의 solution space는 34-layer plain network의 subspace임에도 불구하고, 오히려 34-layer plain net 인 경우 학습 과정 전반에서 더 높은 training error 를 갖는다.
논문의 저자들은 여기서 직면하는 optimization difficulty가 vanishing gradients에 의한 것과 같지 않다고 하였다. 그 이유는 plian network 가 BN [16]을 포함하여 학습하기 때문에 forward propagated signal의 분산이 0이 아니도록 보장한다. 우리는 또한 backward propagated gradients가 BN과 함께 healty norm을 보이는 것도 확인했기 때문이다. 따라서forward/backward signal은 vanishing 하지 않았다고 볼 수 있다. 실제로 , Table 3 의 결과를 따르면 34-layer plain network가 여전히 경쟁력 있는 정확도를 달성했으며, 이는 solver의 작동이 이루어지긴 한다는 것을 의미한다. 저자들은 또한, deep plain network는 exponentially low convergence rate를 가지며, 이것이 training error의 감소에 영향 끼쳤을거라 추측하고 있다. optimization difficulties의 원인에 대해서는 미래에 배울 것이다.
=> 층이 깊을 수록 training error가 낮은 것 보다 낮다. optimization difficulties가 gradient vanishing 문제가 아닌것 같고 exponentially low convergence rate를 가지고 있으서 training error의 감소에 영향 끼쳤을거라 추측하고 있다.
We have experimented with more training iterations (3×) and still observed the degradation problem, suggesting that this problem cannot be feasibly addressed by simply using more iterations. => 저자들은 더 많은 training iterations (3×) 으로 실험했지만 여전히 degradation problem를 관찰하였으며 , 이는 단순히 더 많은 반복을 사용하는 것으로 이 문제를 해결할 수 없음을 시사한다.
Residual Networks
다음으로 18-layer 및 34-layer residual network(이하 ResNet)를 평가한다. baseline architecture는 위의 plain network와 동일하며, Fig.3의 오른쪽과 같이 각 3x3 filter pair에 shortcut connection을 추가했다. In the first comparison (Table 2 and Fig. 4 right), 모든 shortcut connection은 identity mapping을 사용하며, dimension matchings (option A)을 위해서는 zero-padding을 사용한다(3.3절의 옵션 1 참조). 따라서, 대응되는 plain network에 비해 추가되는 parameter가 없다.
Table.2와 Fig.4에서 알 수 있는 3가지 주요 관찰 결과는 다음과 같다.
1. residual learning으로 인해 상황이 바뀌었다. 34-layer ResNet이 18-layer ResNet(by 2.8%)보다 우수한 성능을 보인다. 또한, 34-layer ResNet이 상당히 낮은 training error를 보였으며, 이에 따라 향상된 validation 성능이 관측됐다. 이는 성능 저하 문제가 잘 해결됐다는 것과, 증가된 depth에서도 합리적인 accuracy를 얻을 수 있다는 것을 나타낸다.
2. 34-layer ResNet은 이에 대응하는 plain network와 비교할 때, validation data에 대한 top-1 error를 3.5% 줄였다(Table.2 참조). 성공하게 training errors을 줄이는 것은 (Fig. 4 right vs. left) 결곽 있다. 이는 extremely deep systems에서 residual learning의 유효성을 입증하는 결과다.
3. 마지막으로는 , 18-layer plain/residual network 간의 정확도(Table 2) 유사한 성능을 보였지만, Fig.4에 따르면 18-layer ResNet이 더욱 빠르게 수렴한다r (Fig. 4 right vs. left). 이는 network가 “not overly deep”한 경우(18-layers의 경우), 현재의 SGD solver는 여전히 plain net에서도 좋은 solution을 찾을 수 있다는 것으로 볼 수 있다. 하지만, 이러한 경우에도 ResNet에서는 빠른 수렴속도를 기대할 수 있다.
Identity vs. Projection Shortcuts
앞에서 parameter-free한 identity shortcut이 학습에 도움 된다는 것을 보였다. 이번에는 Eqn.2의 projection shortcut에 대해 조사하자. Table.3에서는 다음 3가지 옵션에 대한 결과를 보여준다.
- zero-padding shortcut는 dimension matching에 사용되며, 모든 shortcut는 parameter-free하다(Table.2 및 Fig.4의 결과 비교에 사용됨).
- projection shortcut는 dimension을 늘릴 때만 사용되며, 다른 shortcut은 모두 identity다.
- 모든 shortcut은 projection이다.
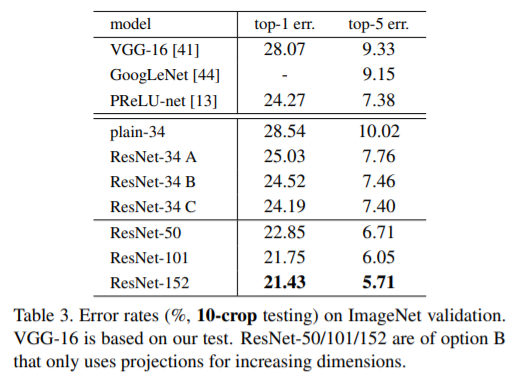
Table.3에서는 3가지 옵션 모두 plain network보다 훨씬 우수함을 보여준다. 우리는 이것이 A의 zero-padded dimensions이 실제로 esidual learning이 없기 때문이라고 주장한다. C에 비해서 B보다 약간 낫고 , 우리는 이것을 많은 (thirteen) projection shortcuts에 의해 도입된 추가 parameters 때문이라고 본다. 그러나 A/B/C 간의 작은 차이는 projection shortcuts가 degradation problem를 해결하는데 필수적이지 않다는 것을 나타냅니다. 따라머 memory/time complexity와 model size를 줄이기 위해 이 논문의 나머지 부분에서는 옵션 C를 사용하지 않느다. Identity shortcuts은 아래에 소개된 bottleneck architecture의 complexity를 증가시키지 않는데 특히 중요하다.
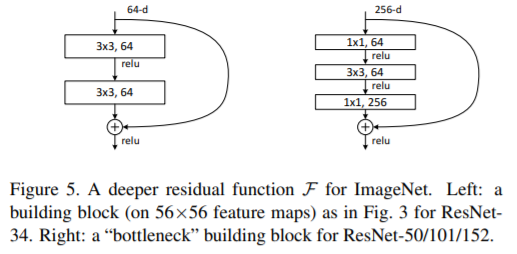
Deeper Bottleneck Architectures.
다음으로 mageNet을 위한 deeper nets에 대해 설명한다. 학습 시간에 대한 우려로 인해 building block as a bottleneck desig으로 설계한다.
Deeper non-bottleneck ResNets (e.g., Fig. 5 left) also gain accuracy from increased depth (as shown on CIFAR-10), but are not as economical as the bottleneck ResNets. So the usage of bottleneck designs is mainly due to practical considerations. We further note that the degradation problem of plain nets is also witnessed for the bottleneck designs. =>Deeper non-bottleneck ResNets (예: Fig. 5 lef ) 도 증가된 depth (CIFAR-10에 표시된 대로)에서 정롹도를 얻지만 bottleneck ResNets만큼 경제적이지는 않는다. 그래서 bottleneck designs의 사용은 주로 실용적인 고려 사항 때문이다. 우리는 또한 bottleneck designs에서도 plain nets의 degradation problem 가 목격된다는 것을 주목한다.
각 residual function F 에 대해, 우리는 2 layers 대신 3 layers의 stack을 사용한다(Fig.5 참조). three layers는 1×1, 3×3, and 1×1 convolutions이며 , 여기서
1×1 layers는 (restoring) dimensions 크기 를 을 줄이거나 증가시키는 용도로 사용하며 ,
3×3 layer의 input/output의 dimentsion을 줄인 bottleneck 으로 둔다. Fig.5에서는 2-layer stack과 3-layer stack가 유사한 디자인과 유사한 time complexity을 갖는 예를 보여준다 . 둘은 유사한 time complexity를 갖는다.
여기서 parameter-free는 identity shortcuts는 bottleneck architectures에서 특히 중요하다. 만약 Fig. 5 (right) 의 identity shortcut가 projection으로 대체된다면, shortcut이 두 개의 high-dimensional 출력과 연결되므로 time complexity와 model size가 두 배로 늘어난다. 따라서 identity shortcut은 이 bottleneck design을 보다 효율적인 모델로 만들어준다.
50-layer ResNet:
우리는 34-layer ResNet의 2-layer block들을 3-layer bottleneck block으로 대체하여 50-layer ResNet(Table 1)을 구성했다. 우리는 크기를 늘리기 위해 option B 를 사용한다. 이 모델은 3.8 billion FLOPs 를 가지고 있다.
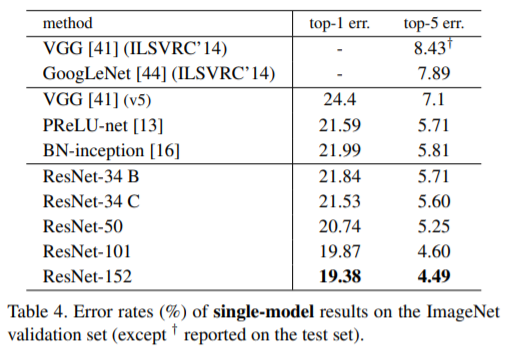
101-layer and 152-layer ResNets: 우리는 더 많은 3-layer bottleneck block을 사용하여 101-layer 및 152-layer ResNet을 (Table 1) 구성했다. depth가 상당히 증가했음에도 상당히 높은 정확도가 결과로 나왔다. 152-layer ResNet (11.3 billion FLOPs)은 VGG-16/19 nets (15.3/19.6 billion FLOPs)보다 복잡성이 낮다.
50/101/152-layer ResNets는 34-layer ResNets 보다 상당한 margins 으로 정확하다 (Table 3 and 4).
Comparisons with State-of-the-art Methods
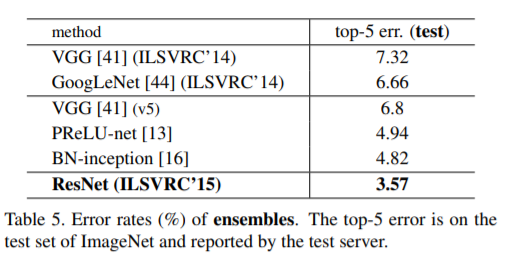
Table.4에서는 previous best single-model 결과와 비교한다. 우리의 baseline인 34-layer ResNet은 previous best에 비준하는 정확도를 달성했다. 152-layer ResNet의 single-model top-5 error는 4.49%를 달성했다. 이 single-model result 결과는 이전의 모든 ensemble result를 능가하는 성능이다(Table.5 참조). 또한, 우리는 서로 다른 depth의 ResNet을 6개 모델을 (ensemble)을 형성한다. (submitting시 152-layer 모델 2개만 있음)이로 하여 tes set에서 top-5 test error를 3.57%까지 달성했다(Table 5). 이는 ILSVRC 2015 classification task에서 1위를 차지했다.
4.2. CIFAR-10 and Analysis
논문에서는 CIFAR-10 dataset[20]에 대한 더 많은 연구를 수행했다.
CIFAR-10 dataset :
10개의 classes
training images가 50 k
testing images 10k
우리는 training set에서 학습되고 test set에서 평가된 실험을 제시한다. 우리는 extremely deep networks의 동작에 초점을 맞추고 있지만 state-of-the-art results를 추진하는 데는 초점을 맞추지 않기 때문에 의도적으로 다음과 같은 간단한 architecture를 사용했다.
plain/residual architectures는 Fig. 3 (middle/right)의 양식을 따른다.
network의 input은 per-pixel mean subtracted 32x32 이미지이다.
첫 번째 layer는 3x3 cconvolutions이다.그런 다음 sizes {32, 16, 8} respectively feature maps 에서 각각3×3 convolutions을 가진 stack of 6n layers를 사용하고 각 feature map size에 대해 2n layers를 사용한다. filters 수는 각각 {16, 32, 64}개이다. 그 subsampling 은 stride 2으로 convolutions 을 수행된다. network의 ends는 global average pooling, a 10-way fully-connected layer, and softmax로 구성된다. 총 6n+2 stacked weighted layers가 있다. 다음 표는 아키텍처가 요약되어 있다.
shortcut connections가 사용될 때 , 3×3 layers 쌍 (totally 3n shortcuts) 에 연결된다. 이 dataset에서 우리는 모든 경우(즉 option A) 에 identity shortcuts를 사용하므로 우리의 residual models은 plain counterparts와 정확히 동일한 depth, width, and number of parameters수를 갖는다.
학습 진행 방법은 다음과 같다.
weight decay : 0.0001
momentum : 0.9
weight initialization in [13] and BN [16]수렴하고 but with no dropout.
2개의 GPU에서 mini-batch size를 128로 학습했다.
learning rate는 0.1부터 시작하여 , 32000/48000번 째 iteration에서 10으로 나누고, 45k/5k train/val split 결정되는 64k iterations에서 학습을 종료한다.
학습을 위해 [24]의 간단한 data augmentation을 따른다 :
4개의 pixel이 각 side에 padded 있으며 32×32 crop이 padded 된 이미지 또는 horizontal flip에서 무작위로 샘플링된다.
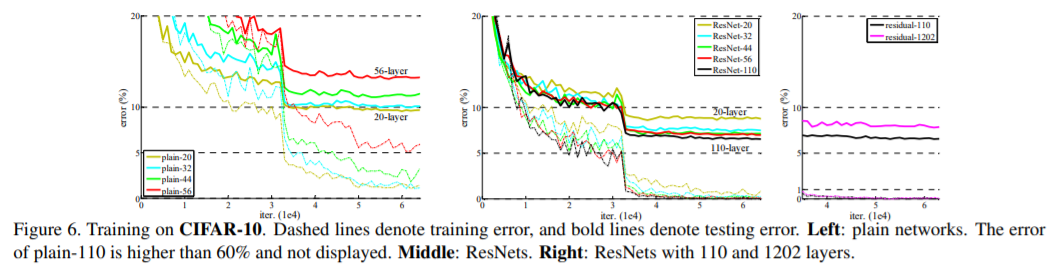
테스트를 위하여 우리는 original 32×32 image의 single view만 평가한다. 우리는n = {3, 5, 7, 9}에서는 20, 32, 44, and 56-layer networks를 비교한다. Fig. 6 (left)은 plain network의 결과를 보여준다. deep plain nets 은 depth가 증가하여 , going deeper수록 training error 가 커진다. 이 현상은 ImageNet (Fig. 4, left) 및 MNIST (see [42])의 현상과 유사하며 , 이는 이러한 최적화 어려움이 근본적인 문제임을 시사한다.
Fig. 6 (middle) 는 ResNets의 학습 결과를 보여준다. 또한 ImageNet cases (Fig. 4, right)와 유사하게 ResNets은 optimization 어려움을 극복하고 깊이가 커질 때 정확도가 향상됨을 입증한다.
110-layer ResNet으로 이어지는 n = 18에 대해서 자세히 살펴본다. 이 경우 initial learning rate가 0.1인 것이 수렴을 시작하기에는 약간 너무 크다는 것을 알 수 있다.
With an initial learning rate of 0.1, it starts converging (<90% error) after several epochs, but still reaches similar accuracy. => initial learning rate of 0.1으로 , 몇 epoches후 수렴(<90% error)을 시작하지만 여전히 유사한 정확도에 도달한다.
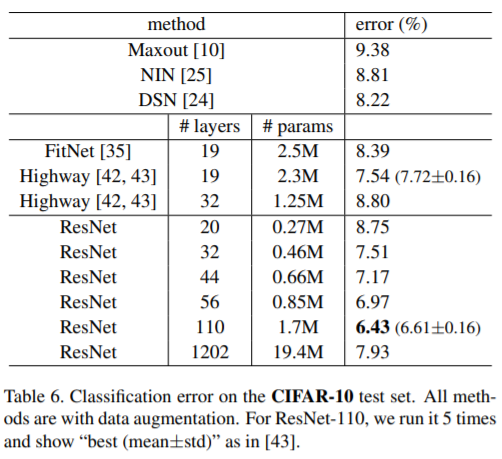
따라서 0.01을 사용하고 training error가 80% (약 400 iterations)미만으로 떨어질 때까지 학습 warm up을 수행한 다음 0.1로 다시 돌아가서 학습을 계속 한다. 나머지 learning schedule은 이전과 같다. 110-layer network 는 잘 수렴된다(Fig. 6, middle). FitNet [35] 및 Highway [42](Table 6)와 같은 다른 deep and thin networks 보다 parameters가 적지만 state-of-the-art results (6.43%, Table 6)을 달성했다 .
Analysis of Layer Responses.
Analysis of Layer Responses.
Fig.7은 layer response의 std(standard deviation)를 보여준다. response는 BN 이후와 다른 nonlinearity(ReLU/addition) 이전의 각 3x3 conv layer의 output이다. ResNets의 경우, 이 분서을 통해 residual functions의 response strength 를 확인할 수 있다. Fig.7에서는 ResNet이 일반적으로 plain counterparts보다 반응이 적다는 것을 보여준다. 이러한 결과는 residual function이 non-residual function보다 0에 가까울 수 있다는 우리의 basic motivation (Sec.3.1)를 뒷받침한다. 우리는 또한 Fig.7의 ResNet-20, 56 및 110 사이의 비교에서 증명된 바와 같이 더 깊은 ResNet의 Response가 더 작다는 것을 알 수 있다. layers가 많을 수록 ResNets 의 개별 layer은 신호를 덜 수정하는 경향이 있다.
Exploring Over 1000 layers.
우리는 100개 이상의 layer로 구성된
aggressively deep model을 탐구한다. 위에서 설명한 대로 학습되는 1202-layer network로 이어지는 n = 200을 설정한다. 우리의 방법은 optimization 어려움이 없으며, 이 103-layer network 는 training error <0.1% (Fig. 6, right). test error는 여전히 상당히 양호한 결과를 보였다. (7.93%, Table 6)
그러나 그러한 aggressively deep models에 대해서는 아직 해결되지 않은 문제들이 있다. 1202-layer network의 test 결과는 110-layer ResNet의 test결과보다 더 나쁘다. 우리는 이것이 과적합 때문이라고 주장한다. 1202-layer network는 CIFAR-10 작은 dataset에 test용으로 불필요하게 클 수 있다. (19.4M) maxout [10] 또는 dropout [14]와 같은 강력한 regularization 를 적용하여 이 dataset에 대한 최상의 결과([10, 25, 24, 35]) 를 얻는다. 이 논문에서 우리는 maxout/dropout을 사용하지 않고, optimization의 어려움에 집중하는 것을 방해하지 않고 설계상 deep and thin architectures를 통해 regularization 만 시행한다. 하지만 더 강력한
regularization 와 결합하면 결과가 향성될 수 있는데, 앞으로 우리가 연구할 것이다.
4.3. Object Detection on PASCAL and MS COCO
우리의 방법은 다른 recognition tasks에서 좋은 generalization performance 가지고 있다.
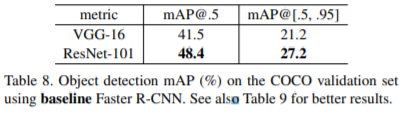
Table 7 and 8에는 PASCAL VOC 2007 and 2012 [5] and COCO [26]의 object detection baseline results가 표시된다. detection method으로 Faster R-CNN [32]을 채택한다. 여기서는 VGG-16 [41] with ResNet-101로 교체하는 개선 사항에 대해 살펴봅시다. 두 모델을 사용하는 detection implementation (see appendix) 은 동일하므로 이득은 더 나은 networks에만 얻을 수 있다. 가장 주목할 만한 점은 까다로운 COCO 데이터 세트에서 COCO 의 standard metric (mAP@[.5,.95])이 6.0%증가하여 상대적으로 28% 향상되었다. 이 이득은 오로지 학습된 표현에 기인한다.
deep residual nets 기반으로 , ILSVRC & COCO 2015 competitions에서 , 여러 tracks에서 1위를 차지 했다: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation. 자세한 내용은 appendix에 있다.











A. Object Detection Baselines
이 section에서는 baseline Faster R-CNN [32] 시스템을 기반으로 detection method을 소개한다. 모델은 ImageNet classification models에 의해 초기화된 다음 bject detection data에서 fine-tuned 된다. 우리는 ILSVRC & COCO 2015 detection competitions 당시 ResNet-50/101으로 실험했다.
[32]에서 사용 되는 VGG-16과 달리 ResNet에는 hidden fc layers이 없다 . 우리는이 문제를 해결하기 위해“Networks on Conv feature maps”(NoC) [33]라는 아이디어를 채택했다. 이미지에 대한 strides 이 16 pixels (i.e., conv1, conv2 x, conv3 x, and conv4 x, totally 91 conv layers in ResNet-101; Table 1)를 사용하여 전체 이미지 shared conv feature maps을 계산한다. 우리는 이러한 레이어가 VGG-16의 13 개 conv 레이어와 유사하다고 간주하며, 그렇게 함으로써 ResNet과 VGG-16은 모두 동일한 총 stide (16 pixels) conv feature maps을 갖게 된다. 이러한 layer은 egion proposal network (RPN, generating 300 proposals) [32]와 Fast R-CNN detection network [7]에 의해 공유된다. RoI pooling [7] 은 conv5-1 이전에 수행된다. 이 RoI-pooled feature에서는 VGG-16’s fc layers역할을 수행하는 모든 conv5 x 이상의 계층이 각 지역에 채택된다. 마지막 classification layer은 두개의 sibling layers (classification and box regression [7])으로 대체된다.
BN layer를 사용하기 위해 pre-training 후 ImageNet training set에서 각 layer에 대한 BN statistics(means and variances)를 계산한다. 그런 다음 object detectoin를 위한 fine-tuning 에 BN layer가 고정된다. 따라서 BN layer는 일정한 offsets and scales로 linear activations 가 되며 , BN statistics 은 fine-tuning 할때 업데이터되지 하지 않는다. 우리는 주로 Faster R-CNN training에서 메모리 소비를 줄이기 위해 BN layer를 고정한다.
PASCAL VOC
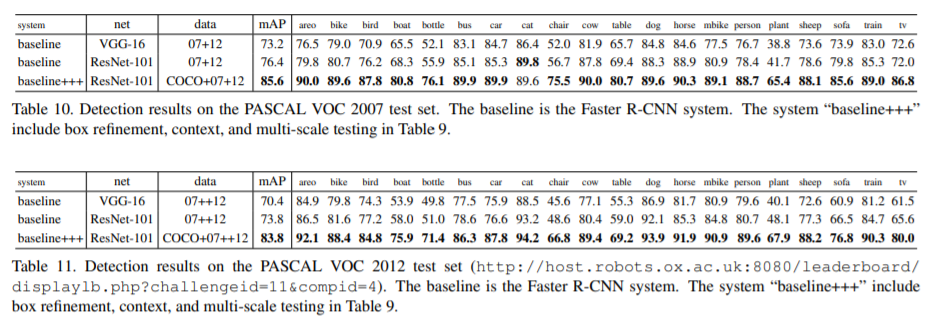
[7, 32]에 따라 ASCAL VOC 2007 test set의 경우 , VOC 2007의 5k trainval 이미지와 VOC 2012의 16k trainval 이미지를 학습에 사용한다(“07+12”). PASCAL VOC 2012 test set의 경우, VOC 2007의 10k trainval+test images와 VOC 2012의 16k trainval images를 학습에 사용한다. Faster R-CNN 학습을 위한 hyper-parameters는 [32]와 동일하다. Table 7은 결과를 보여준다. ResNet-101 은 VGG-16에 비해 mAP를 3% 이상 향상시켰다. 러한 이점은 전적으로 ResNet에서 학습한 향상된 기능 때문이다.
MS COCO
MS COCO dataset [26]는 80개의 object categories로 포함한다. PASCAL VOC metric (mAP @IoU = 0.5)과 standard COCO metric (mAP @ IoU =.5:.05:.95)을 평가한다. 학습을 위해 train set의 80k 이미지를 사용하고 평가를 위해 val set 의 40k를 사용한다. 우리의 detection system은 PASCAL VOC와 유사하다. 우리는 8-GPU implementation으로 COCO 모델을 교육하므로 RPN단계는 8 images (i.e., 1 per GPU) 의 mini-batch size를 가지며 Fast R-CNN step은 16 images mini-batch size를 갖는다. RPN step 와 Fast RCNN step는 모두 learning rate가 0.001인 240k iterations 과 0.0001인 80k iterations 에 대해 훈련 된다.
Table 8 은 MS COCO validation set의 결과를 보여준다. ResNet-101은 VGG-16에 비해 mAP@[.5, .95]가 6% 증가했으며, 이는 더 나은 네트워크에 의해 학습된 기능에 대해서만 28%의 상대적 개선이다. 놀랍게도, mAP@[.5,.95]의 absolute increase (6.0%)은 mAP@.5’s (6.9%)와 거의 같다. 이것은 network가 더 깊어질수록 ecognition and localization과 모두 향상될 수 있음을 시사한다.
B. Object Detection Improvements
completeness를 위해 competitions 개선사항을 보고 드린다. 이러한 개선 사항은 deep features을 기반으로 하므로 residual learning에서 이득을 얻을 수 있다.
MS COCO
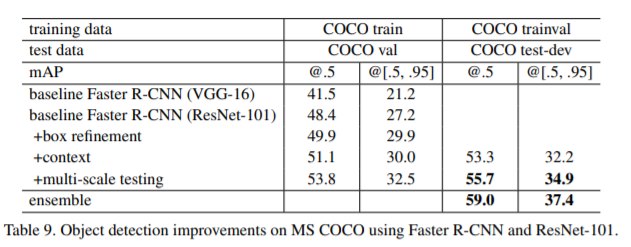
Box refinement. box refinement은 부분적으로 [6]의 iterative localization 파악을 따른다. Faster R-CNN에서 final output은 proposal box와 다른 regressed box이다. 그래서 추론을 위해, 우리는 regressed box 에서 새로운 기능을 pool 하고 새로운 classification score와 새로운 regressed box를 얻는다. 우리는 이 300 new predictions 과 original 300 predictions을 결합한다. Non-maximum suppression (NMS)는 0.3 [8]의 IoU threshold을 사용한 다음 box voting [6]를 사용하여 predicted boxes의 union set에 적용된다. Box refinement 는 mAP 를 2 points (Table 9) 개선한다.
Global context. Fast R-CNN step에서 global context를 결합한다. full-image conv feature map이 주어지면 전체 이미지의 bounding box를 ROI로 사용하여 “RoI” pooling으로 구현할 수 있는 global Spatial Pyramid Pooling [12] (with a “single-level” pyramid) 에 의해 feature를 pooling한다. 이 pooled feature 은 global context feature을 얻기 위해 post-RoI layers 에 공급된다. 이 global feature는 original per-region feature와 연결된 다음 sibling classification and box regression layers 과 연결된다. 이 new structure는end-to-end로 학습된다. Global context는 mAP@.5를 약 1 point (Table 9)향상시킨다.
Multi-scale testing. 위에서 모든 결과는 [32]와 같이 single-scale training/testing을 통해 얻을 수 있으며, 여기서 영상의 더 짧은 면은 s = 600 pixels입니다. Multi-scale training/testing 는 feature pyramid에서 scale 을 선택하여 [12, 7]에서 개발되었으며 [33] 에서는 maxout layers를 사용하여 개발되었다. 현재 구현에서는 [33]에 따라 multi-scale testing 를 수행했지만 시간이 제한되어 multi-scale training 을 수행하지 않았다. 또한 Fast R-CNN step (but not yet for the RPN(region proposal network) step)에 대해서만 multi-scale testing을 수행했다.
Using validation data. 다음으로 우리는 학습에 80k+40k trainval set 와 평가에 20k test-dev set를 사용한다. testdev set에서 공개적으로 사용할 수 있는 ground truth가 없으며 결과는 evaluation server에 의해 보고된다. 이 설정 하에서 결과는 mAP@.5 of 55.7% and an mAP@[.5, .95] of 34.9% (Table 9)이다. 이것은 우리의 single-model result이다.
Ensemble. Faster R-CNN에서 시스템은 region proposals과 object classifiers를 학습하도록 설계되어 있으므로 ensemble 을 사용하여 두 작업을 모두 향상시킬 수 있다. 우리는 regions을 제안하기 위해 앙상블을 사용하고 , 제안의 union set는 per-region classifiers 에 의해 처리된다. Table 9는 3개의 networks의 ensemble을 기반으로 한 우리의 결과를 보여준다. mAP 는 test-dev set에서 59.0% and 37.4%이다. 이 결과는 2015년 COCO detection task에서 1위를 차지했다.
PASCAL VOC
위의 모델을 기반으로 PASCAL VOC dataset를 다시 살펴본다. COCO dataset의 single model(55.7% mAP@.5 in Table 9) 를 사용하여 PASCAL VOC sets에서 이 모델을 fine-tune한다. box refinement, context, and multi-scale testing의 개선 사항도 채택되었다. 이를 통해 PASCAL VOC 2007 (Table 10) 85.6%를 달성하고 and PASCAL VOC 2012 (Table 11)에서 83.8% 를 달성했다. ASCAL VOC 2012에서의 결과는 이전의 state-of-the-art result [6] 보다 더 높다.
ImageNet Detection
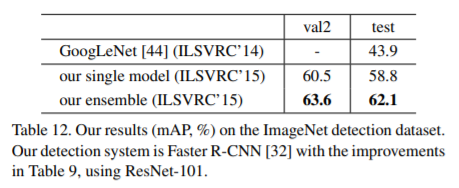
ImageNet Detection (DET) 작업은 200개의 object categories를 포함한다. 정확도는 mAP@.5로 평가된다. ImageNet DET 에 대한 우리의 object detection algorithm은 Table 9의 MS COCO와 동일하다. 이 networks 들은 1000-class ImageNet classification set에서 pretrained 되며 DET data에서 fine-tuned 된다. validation set 를 [8]에 이어 두 부분 (val1/val2)으로 분할했다. DET training set와 val1 set를 사용하여 detection models 을 fine-tune한다. val2 set 가 검증에 사용된다. ILSVRC 2015 data에서 사용하지 않는다. ResNet-101을 사용하는 single model 은 58.8%의 mAP를 가지며 3 models의 ensemble은 DET test set (Table 12)에서 2.1%의 mAP를 가진다(Table 12). 이 결과는 ILSVRC 2015에서 ImageNet detection task 1위를 차지해 2위를 8.5 points (absolute) 앞섰다.
C. ImageNet Localization
ImageNet Localization (LOC) task [36] 에서는 objects를 classify and localize를 요구한다. [40, 41]에 이어 , 우리는 image-level classifiers가 image의 class label을 예측하기 이해 먼저 채택되고 , localization algorithm 은 예측된 class를 기반으로 bounding boxes 예측만 설명한다고 가정한다. 우리는 각 class에 대한 bounding box regressor 를 학습하는 “per-class regression” (PCR) strategy [40, 41]을 채택한다. 우리는 ImageNet classification 를 위해 network를 pre-train 한 다음 localization을 위해 fine-tune한다. 제공된 1000-class ImageNet training set에서 network를 학습한다. 우리의 localization algorithm은 몇 가지 수정을 거친 [32] 의 RPN(Region proposal network) framework 를 기반으로 한다. category-agnostic [32]의 방식과 달리, localization 에 대한 RPN 은 per-class form으로 설계되었다. 이 RPN 은 [32]에서와 같이 binary classification (cls) and box regression (reg)를 two sibling 1×1 convolutional layers로 끝난다. [32]와 대조적으로 , cls와 reg layers은 둘 다 per-class에 있다. 특히 cls layer는 1000-d output를 가지며 , 각 차원은 object class 유무를 예측하기 위한 binary logistic regression이다 ; [32]에서와 같이 bounding box regression는 각 위치에 있는 multiple translation-invariant “anchor” boxes 를 참조한다.
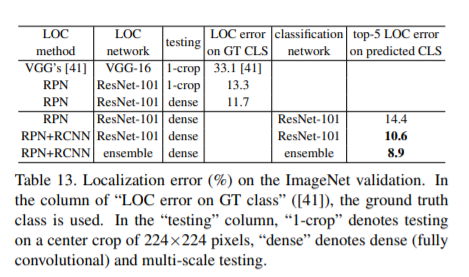
ImageNet classification training (Sec. 3.4)에서 처럼 data augmentation를 위해 224×224 crops 을 무작위로 샘플링한다. fine-tuning을 위해 256 images 의 mini-batch size를 사용한다. negative samples이 지배되는 것을 방지하기 위해 각 이미지에 대해 8개의 anchors 를 샘플링하며 , 여기서 샘플링된 positive and negative anchors의 비율은 1:1 [32]이다. 테스트를 위해 network는 image fully-convolutionally 적용된다. Table 13은 localization results를 비교한다. [41]에 이어 먼저 classification prediction으로 ground truth class를 사용하여 “oracle” testing를 수행한다. VGG’s paper [41]은 ground truth classes를 사용하여 33.1% (Table 13) 의 center-crop error를 보고한다. 동일한 설정에서 , ResNet-101 net을 사용하는 RPN method은 center-crop error를 13.3 %로 크게 줄인다. 이 비교는 우리 framework의 우수한 성능을 입증한다. dense (fully convolutional)및 multi-scale testing에서 ResNet-101은 ground truth classes를 사용하여 11.7%의 error를 가진다. classes 예측에 ResNet-101사용할 경우 (4.6% top-5 classification error, Table 4) , top-5 localization error is 14.4%이다.
위의 결과는 Faster R-CNN [32]의 roposal network (RPN)에만 기반한다. 결과를 개선하기 위해 Faster R-CNN의 detection network (Fast R-CNN [7])를 사용할 수 있다. 그러나 이 dataset에서는 일반적으로 하나의 이미지가 하나의 dominate object를 포함하고 proposal regions 이 서러 매우 겹쳐서 매우 유사한 ROI 풀 기능을 가지고 있다는 것을 알 수 있다. 결과적으로 , Fast R-CNN [7]의 image-centric training은 stochastic training에는 바람직하지 않을 수 있는 작은 변화의 샘플을 생성하다. 이에 자극을 받아 current experiment에서는 Fast R-CNN 대신 RoI-centric의 original RCNN [8]을 사용한다.
우리의 R-CNN 구현은 다음과 같다. 우리는 training images 에 위에서 학습된 per-class RPN을 적용하여 ground truth class에 대한 경계 상자를 예측한다. 이러한 predicted boxes는 class-dependent proposals의 역할을 한다. 각 training image에 대해 가장 높은 점수를 받은 200 proposals이 R-CNN classifier를 학습하기 이한 학습 샘플로 추출된다. image region은 proposal에서 cropped내어 224×224 pixels로 뒤틀린 다음 R-CNN [8]에서와 같이 classification network에 공급된다. 이 network의 출력은 cls와 reg에 대한 두개의 sibling fc layers으로 구성되며 , per-class form로도 구성된다. 이 R-CNN network 는 RoI-centric fashion의 방식으로 256개의 mini batch size를 사용하여 training set에서 fine-tuned 된다. testing를 위해 RPN은 각 예측 클래스에 대해 가장 높은 점수를 200 proposals 을 생성하고 , R-CNN network를 사용하여 이러한 proposals’ scores and box positions을 업데이터한다.
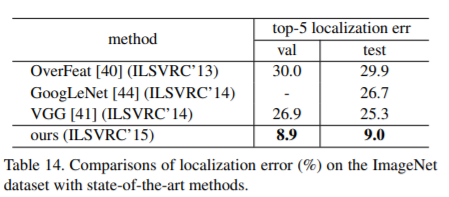
이 방법은 top-5 localization error를 10.6% (Table 13) 줄였다. 이것은 validation set에 대한 우리의 single-model result 이다. lassification and localization에 network ensemble 을 사용하여 test set에서 top-5 localization error of 9.0%에 이른다. 이 수치는 ILSVRC 14 results (Table 14)를 크게 능가하며, 상대적인 error 감소를 보여준다. 이 결과는 ILSVRC 2015에서 ImageNet localization task에서 1위를 차지했다.
[출처] Deep Residual Learning for Image Recognition
[참조]
https://sike6054.github.io/blog/paper/first-post/
(ResNet) Deep residual learning for image recognition 번역 및 추가 설명과 Keras 구현
Paper Information
sike6054.github.io
파파고 번역을 많이 사용하였다.