Abstract
우리는 mobile and embedded vision applications 효율적인 모델 클라스 제시하며 MobileNets이라고 한다. MobileNets은 streamlined architecture을 기반으로 하고 , depthwise separable convolutions 을 사용하여 light weight deep neural networks 로 만들었다. 우리는 두가지 간단한 latency and accuracy사이에서의 global hyperparameters that efficiently trade off 를 소계한다. 이러한 hyper-parameters를 통해 model builder는 문제의 제약 조건에 따라 애플리케이션에 맞는 올바른 크기 모델을 선택할 수 있다. 또한 리소스 및 정확도 절충에 대한 저자의 광범위한 실험은 MobileNet이 ImageNet 분류 문제 및 기타 인기있는 모델에서 매우 강력한 성능을 가지고 있음을 보여준다. 그런 다음 저자는 object detection, finegrain classification, face attributes and large scale geo-localization을 포함한 광범위한 애플리케이션 시나리오에서 MobileNet의 효율성을 입증했다.
finegrain classification : 세밀하게 구분하는것
1. Introduction
AlexNet [19] popularized deep convolutional neural networks 가 ImageNet Challenge ILSVRC 2012 [24]. 에서 우승을 그듭한후 Convolutional neural network은 computer vision에서 어디에서 있는 모습을 드러냈다. 더 깊거나 더 복잡한 networks은 높은 정확도 [27, 31, 29, 8] 를 가질 수 있다 .
[27] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 1, 6
[31] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015. 1, 3, 4, 7
[29] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261, 2016. 1
[8] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015. 1
논문에서는 efficient network architecture와 mobile and embedded vision applications모델에서 아주 작고, low latency 을 만들기 위한 두가지 hyper-parameters 들을 소계한다.
Section 2 : small models을 만들기 위한 prior work
Section 3 : describes the MobileNet architecture and two hyper-parameters width multiplier and resolution multiplier to define smaller and more efficient MobileNets
Section 4 describes experiments on ImageNet as well a variety of different applications and use cases. => 경험적으로 연구 결과
Section 5 closes with a summary and conclusion. => 결론
2. Prior Work
building small and efficient neural networks in the recent literature
pretrained networks or training small networks directly
choose a small network that matches the resource restrictions (latency, size) for their application
mobilenet 기본적으로 optimnizing for latency, samll networks에 관심을 한다.
하지만 매우 많은 논문에서는 small networks에만 집중을 하고 속도에 고려 하지 않는다.
MobileNet은 주로 L. Sifre. Rigid-motion scattering for image classification. PhD 논문, Ph. D. 논문, 2014. 1, 3에서 처음 소개 된 deep separable convolutions로 구성되며, 마지막으로 Inception 모델에서 초기를 줄이기 위해 사용되었습니다. 여러 계층의 계산. 플랫 네트워크는 완전히 분해 된 네트워크를 통해 설정되어 네트워크를 분해 할 수있는 큰 잠재력을 보여줍니다. Factorized Networks는이 기사와 거의 관련이 없으며 분해 및 컨볼 루션과 유사한 방법과 topological 연결 사용을 소개합니다. 그런 다음 Xception 네트워크는 Inception V3보다 더 나은 네트워크 성능을 달성하기 위해 분리 가능한 컨볼 루션 커널 (텍스트의 필터, 이전 CNN 연구 노트에서 필터도 컨볼 루션 커널, 커널을 참조 함)의 깊이를 확장하는 방법을 시연했습니다. 또 다른 소규모 네트워크는 SqueezeNet입니다. 병목 방식을 사용하여 소규모 네트워크를 설계합니다. 계산량을 줄이는 다른 네트워크로는 structured transform networks和deep fried convents가 있습니다.
소규모 네트워크를 얻는 다른 방법은 축소하는 것입니다. 즉, 네트워크를 분해하거나 압축하고 훈련시키는 것입니다. literature의 압축 방법에는 제품 양자화, 해싱, 프 루닝, 벡터 양자화 및 Huffman 코딩이 포함됩니다. 사전 훈련 네트워크를 가속화하기 위해 제안 된 다양한 인수 분해 방법도 있습니다. 소규모 네트워크를 훈련시키는 또 다른 방법은 대규모 네트워크를 사용하여 소규모 네트워크를 가르치는 증류입니다. 증류 방법은 저자의 방법을 보완하는 것으로 섹션 4에서 예제와 함께 사용됩니다. 또 다른 새로운 방법은 low bit networks 입니다.

기존에는 pre-train된 모델을 줄였고, 주로
- compression
- quantization
- hashing
- pruning
등을 통해 모델을 줄였는데, 주로 '속도’를 위한 것이라기 보다는 네트워크 '크기’에 초점이 맞추어져 있었는데, 이 논문은 '속도’를 타겟으로 합니다.
3. MobileNet Architecture
우리는 먼저 the core layers that MobileNet is built on which are depthwise separable filters에 대해서 소계드린다. 그다음 the MobileNet network structure and conclude with descriptions of the two model shrinking hyperparameters width multiplier and resolution multiplier 에 대해서 소계르린다.
3.1. Depthwise Separable Convolution
MobileNet 모델은 표준 회선을 깊이 별 회선과 1 * 1 회선, 1 * 1 회선으로 분해하는 분해 된 회선의 한 형태 인 깊이 별 분리 가능한 회선을 기반으로합니다. pointwise convolution이라고도합니다. MobileNet의 경우 딥 컨볼 루션은 각 채널에 컨볼 루션 커널을 적용합니다. 그런 다음 점별 컨볼 루션은 1 * 1 컨볼 루션을 적용하여 출력 및 깊이 컨볼 루션을 결합합니다. 표준 컨볼 루션은 컨볼 루션 커널과 입력을 한 번에 새 출력으로 결합합니다. 깊이 분리 가능한 컨볼 루션은 필터링을위한 레이어와 결합을위한 레이어의 두 레이어로 나눕니다. 이 분해 프로세스는 계산량과 모델 크기를 크게 줄입니다.Figure 2 shows how a standard convolution 2(a) is factorized into a depthwise convolution 2(b) and a 1 × 1 pointwise convolution 2(c).
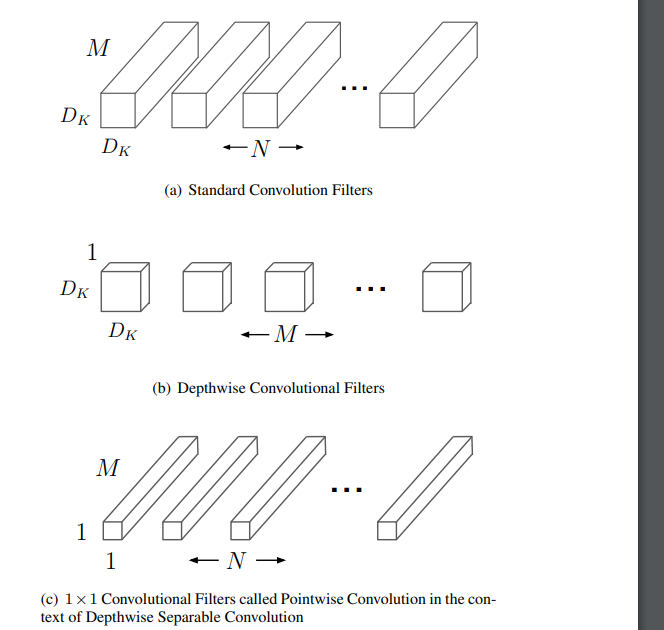
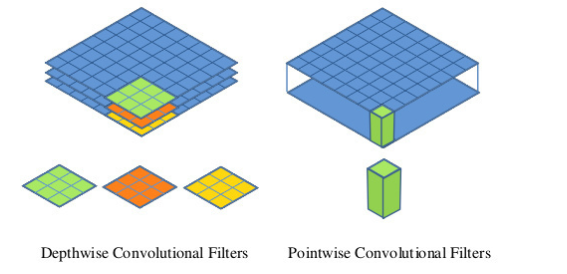
Depthwise separable convolution are made up of two layers:
depthwise convolutions and pointwise convolutions.
We use depthwise convolutions to apply a single filter per each input channel (input depth). Pointwise convolution, a simple 1×1 convolution, is then used to create a linear combination of the output of the depthwise layer. MobileNets use both batchnorm and ReLU nonlinearities for both layers.
Depthwise convolution is extremely efficient relative to standard convolution.
MobileNet uses 3 × 3 depthwise separable convolutions which uses between 8 to 9 times less computation than standard convolutions at only a small reduction in accuracy as seen in Section 4.
MobileNets는 3 * 3 깊이 분리형 컨볼 루션을 사용하므로 표준 컨볼 루션을 사용하는 것보다 계산량이 8-9 배 감소합니다.
공간 차원의 추가 분해는 깊이 컨볼 루션의 계산량이 본질적으로 작기 때문에 계산량을 너무 많이 줄이지 않습니다.
3.2. Network Structure and Training
앞서 언급했듯이 MobileNet 구조는 첫 번째 레이어가 완전 컨볼 루션 레이어라는 점을 제외하고는 분리 가능한 깊은 컨볼 루션을 기반으로합니다. 이러한 간단한 방법으로 네트워크를 정의하면 네트워크 토폴로지를 탐색하여 좋은 네트워크를 찾을 수 있습니다. 표 1은 MobileNet의 아키텍처입니다. 비선형 활성화 함수가 없지만 분류를 위해 소프트 맥스 계층에 직접 입력되는 최종 완전 연결 계층을 제외하고 모든 계층은 batchnorm 및 ReLU 비선형 활성화 함수입니다. 그림 3은 표준 컨볼 루션과 깊이 분리 가능한 컨볼 루션을 비교하며, 둘 다 batchnorm 계층과 ReLU 비선형 활성화 함수를 따릅니다. 딥 컨볼 루션 레이어와 첫 번째 레이어 모두 다운 샘플링을 처리 할 수 있습니다. 최종 평균 풀링 계층은 완전히 연결된 계층 이전의 공간 차원을 1로 줄입니다. Deep convolution과 point-by-point convolution을 독립적 인 레이어로 생각하십시오 .MobileNet에는 (1 + 13 * 2 + 1 = 28) 레이어가 있습니다.



적은 수의 다중 추가를 통해 네트워크를 정의하는 것만으로는 충분하지 않습니다. 이러한 작업을 효율적으로 구현할 수 있는지 확인하는 것도 중요합니다. 예를 들어, 비정형 희소 행렬 연산은 일반적으로 희소 행렬의 정도가 충분하지 않으면 조밀 행렬 연산보다 빠르지 않습니다. 저자의 모델 구조는 거의 모든 계산 복잡성을 1 * 1 컨볼 루션에 넣습니다. 이는 고도로 최적화 된 GEMM (General Matrix Multiplication)을 통해 달성 할 수 있습니다. 일반적으로 회선은 GEMM에 의해 구현되지만 im2col이라는 메모리에서 초기 정렬도 필요합니다. 예를 들어,이 방법은 인기있는 Caffe 패키지에서 유용합니다. 1 * 1 컨볼 루션은 메모리에서 이러한 정렬이 필요하지 않으며 가장 최적화 된 수치 선형 대수 알고리즘 중 하나 인 GEMM에 의해 직접 구현 될 수 있습니다. MobileNet은 1 * 1 컨볼 루션에서 계산 시간의 95 %를 소비하며 매개 변수의 75 %도 포함합니다 (표 2). 거의 모든 추가 매개 변수는 완전 연결 계층에 있습니다.
MobileNet 모델은 Inception V3과 유사한 비동기 경사 하강 법 RMSprop를 사용하여 TensorFlow에서 학습됩니다. 그러나 큰 모델을 훈련하는 것과는 반대로, 작은 모델은 과적 합하기 쉽지 않기 때문에 저자는 정규화 및 데이터 증가 기술을 덜 사용합니다. MobileNet을 훈련 할 때 저자는 side heads 나 label smoothing을 사용하지 않고 이미지 왜곡을 줄이기 위해 대규모 Inception 훈련에 사용되는 작은 자르기 크기를 사용했습니다. 또한 저자는 depthwise filters에 매개 변수가 거의 없기 때문에 weight decay(L2 정규화)를 적게 또는 전혀 두지 않는 것이 중요하다는 것을 발견했습니다. 다음 섹션의 ImageNet 벤치 마크에서 모든 모델은 동일한 매개 변수로 학습되지만 모델의 크기는 고려되지 않습니다.
3.3. Width Multiplier: Thinner Models
기본 MobileNet 아키텍처는 충분히 작고 대기 시간이 충분히 낮지 만 특정 사용 사례 또는 애플리케이션은 모델을 더 작고 빠르게 만들 수 있습니다. 더 작고 계산 비용이 덜 드는 모델을 만들기 위해 저자는 폭 승수 α라는 간단한 매개 변수를 도입했습니다. 그 기능은 네트워크의 각 계층에 대한 부담을 균등하게 줄이는 것입니다. 주어진 레이어 및 폭 승수 α에 대해 입력 채널 M은 αM이되고 출력 채널은 αN이됩니다.
Width multiplier는 모든 모델 구조에서 사용되어 합리적인 정확도, 지연 및 크기로 새롭고 작은 모델을 정의 할 수 있습니다. 재교육이 필요한 새로운 단순화 된 구조를 정의하는 데 사용됩니다.
3.4. Resolution Multiplier: Reduced Representation
신경망의 계산 비용을 줄이는 두 번째 하이퍼 파라미터는 resolution multiplier ρ 입니다. 작성자는이 매개 변수를 입력 이미지에 적용하고 각 레이어의 내부 특징을 동일한 승수로 뺍니다. 실제로 저자는 입력 해상도를 설정하여 암시 적으로 ρ를 설정합니다.
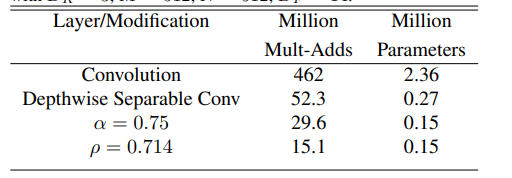
MobileNet의 일반적인 레이어를 예로 살펴보고 width multiplier 및 resolution multiplier를 사용한 깊이 분리형 컨볼 루션이 비용과 매개 변수의 양을 줄이는 방법을 확인할 수 있습니다. 표 3은 다른 프레임 워크 축소 방법이이 계층에 적용될 때 계산량과 매개 변수 수를 보여줍니다. 첫 번째 줄은 완전 연결 계층에서 Mult-Adds의 수와 매개 변수입니다. 입력 특성 맵 크기는 14 * 14 * 512이고 컨볼 루션 커널 크기는 3 * 3 * 512 * 51입니다. 다음 섹션에서는 모델 리소스와 정확성 간의 타협에 대한 세부 정보를 볼 수 있습니다.
width multiplier는 논문에서 α로 표현하였고 인풋과 아웃풋의 채널에 곱해지는 값입니다
반면 resolution multiplier는 인풋의 height와 width에 곱해지는 상수값입니다.
4. Experiments
이 섹션에서는 먼저 압축 모델을 선택하기 위해 레이어 수를 줄이는 대신 딥 컨볼 루션의 영향을 탐색하고 네트워크 폭을 줄입니다. 그런 다음 네트워크는 width multiplier와 resolution multiplier라는 두 개의 하이퍼 파라미터를 기반으로 축소되고 현재 주류 모델과 비교됩니다. 그런 다음 다양한 애플리케이션에서 MobileNet의 애플리케이션을 논의합니다
4.1. Model Choices
첫째, 깊은 분리 가능한 컨볼 루션과 완전 컨볼 루션 모델을 사용한 MobileNet의 결과를 비교합니다. 표 4는 ImageNet에서 심도 분리 가능 컨볼 루션을 사용하는 정확도가 전체 컨볼 루션에 비해 1 % 만 감소하지만 다중 추가 및 매개 변수의 수가 크게 감소 함을 보여줍니다.
그런 다음 저자는 width multiplier를 사용하는 더 얇은 모델과 더 적은 레이어를 사용하는 더 얕은 모델의 결과를 비교했습니다. MobileNet을 더 얕게 만들기 위해 표 1에서 분리 가능한 컨볼 루션 커널의 5 개 계층이 제거되었습니다 (기능 크기 : 14 * 14 * 512). 표 5는 계산 및 매개 변수의 양이 유사한 경우 Thinner의 MobileNet의 정확도가 얕은 모델보다 3 % 더 높다는 것을 보여줍니다.

4.2. Model Shrinking Hyperparameters
표 6은 width multiplier α를 사용하여 MobileNet 아키텍처를 축소 한 후 정확도, 계산량 및 크기 간의 균형을 보여줍니다. 모델이 작아지면 정확도가 떨어집니다.
표 7은 reduced input resolutions로 MobileNet을 훈련 할 때 다른 resolution multiplier ρ 값의 정확도, 계산량 및 크기 사이의 절충안입니다. 해상도가 낮아지면 정확도가 감소합니다.
Figure 4 shows the trade off between ImageNet Accuracy and computation for the 16 models made from the cross product of width multiplier α ∈ {1, 0.75, 0.5, 0.25} and resolutions {224, 192, 160, 128}. Results are log linear with a jump when models get very small at α = 0.25.

Figure 5 shows the trade off between ImageNet Accuracy and number of parameters for the 16 models made from the cross product of width multiplier α ∈ {1, 0.75, 0.5, 0.25} and resolutions {224, 192, 160, 128}.

Table 8 compares full MobileNet to the original GoogleNet [30] and VGG16 [27]. MobileNet is nearly as accurate as VGG16 while being 32 times smaller and 27 times less compute intensive. It is more accurate than GoogleNet while being smaller and more than 2.5 times less computation.
Table 9 compares a reduced MobileNet with width multiplier α = 0.5 and reduced resolution 160 × 160. Reduced MobileNet is 4% better than AlexNet [19] while being 45× smaller and 9.4× less compute than AlexNet. It is also 4% better than Squeezenet [12] at about the same size and 22× less computation.

4.3. Fine Grained Recognition
fine-grained image classification은 무엇일까? 새의 종, 꽃의 종, 동물의 종 또는 자동차의 모델 같이 구분하기 어려운 클래스들을 분류하는 과제다.
image classification과 fine-grained image classification의 차이
image classification은 이미지가 개에 관한 것인지, 고양이에 관한 것인지, 사람에 관한 것인지, 자동차에 관한 것인지 분류하는 컴퓨터 비전 과제다. 그렇다면 fine-grained image classification은 무엇일까?.
bskyvision.com
4.4. Large Scale Geolocalizaton
4.5. Face Attributes
4.6. Object Detection
4.7. Face Embeddings
=>
상용화를 위하여 필요한 여러가지 제약 사항을 개선시키기 위하여 경량화 네트워크
가벼운 네트워크
small and latency
- Channel Reduction : MobileNet 적용
- Channel 숫자룰 줄여서 경량화
- Depthwise Seperable Convolution : MobileNet 적용
- 이 컨셉은 Xception에서 가져온 컨셉이고 이 방법으로 경량화를 할 수 있습니다.
- Distillation & Compression : MobileNet 적용
- Remove Fully-Connected Layers
- 파라미터의 90% 정도가 FC layer에 분포되어 있는 만큼 FC layer를 제거하면 경량화가 됩니다.
- CNN기준으로 필터(커널)들은 파라미터 쉐어링을 해서 다소 파라미터의 갯수가 작지만 FC layer에서는 파라미터 쉐어링을 하지 않기 때문에 엄청나게 많은 수의 파라미터가 존재하게 됩니다.
- Kernel Reduction (3 x 3 → 1 x 1)
- (3 x 3) 필터를 (1 x 1) 필터로 줄여서 연산량 또는 파라미터 수를 줄여보는 테크닉 입니다.
- 이 기법은 대표적으로 SqueezeNet에서 사용되었습니다.
[논문] MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications
참조사항:
gaussian37.github.io/dl-concept-mobilenet/
MobileNets - Efficient Convolutional Neural Networks for Mobile Vision Applications
gaussian37's blog
gaussian37.github.io
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
구글에서 나온 논문입니다. 모바일에서(내지는 cpu에서) realtime으로 network forward가 되는 결과를 보여줍니다. Key Idea는 Convolution Layer가 무거우니 이를 줄일건데, 일종의 Factorization을 제시합니다. Dep
openresearch.ai
blog.csdn.net/qq_31914683/article/details/79330343
【论文学习】MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications_斯丢劈德的博客-CSDN
MobileNets是谷歌公司在2017年发布的一种可以在手机等移动终端运作的神经网络结构。 论文地址:点击打开链接 作者给出了移动端和嵌入式视觉应用的MobileNets模型。MobileNets基于流线型结构设计,�
blog.csdn.net