Visualizing and Understanding Convolutional Networks
Large Convolutional Network models have recently demonstrated impressive classification performance on the ImageNet benchmark. However there is no clear understanding of why they perform so well, or how they might be improved. In this paper we address both
arxiv.org
Abstract
Large Convolutional Network models 은 ImageNet benchmark(AlexNet) classification에서 상당히 인상적인 성능을 주었다. 하지만 그것들은 왜 성능이 좋은지 왜 향상이 되였는지에 대한 명확한 이해가 없습니다. => 이 이유에 대해 논문에서 재기한다.
intermediate feature layer 과 operation of the classifier의 통찰력을 제공하는 새로운 시각화 기법을 소계하였다.
diagnostic role에 사용되는 이러한 시각화를 통해 ImageNet Classification benchmark AlexNe보다 성능이 뛰어난 모델 아키텍츠를 찾을수 있다.
또한 다른 모델 계층에서 성능 기여를 발견하기 위해 ablation study를 수행한다.
데이터 세트에 대해 일반화 잘됨
softmax classifier is retrained하면 Caltech-101 및 Caltech-256 sota
ablation study :의학이나 심리학 연구에서, Ablation Study는 장기, 조직, 혹은 살아있는 유기체의 어떤 부분을 수술적인 제거 후에 이것이 없을때 해당 유기체의 행동을 관찰하는 것을 통해서 장기, 조직, 혹은 살아있는 유기체의 어떤 부분의 역할이나 기능을 실험해보는 방법을 말한다. 이 방법은, experimental ablation이라고도 알려져 있는데, 프랑스의 생리학자 Maria Jean Pierre Flourens이 19세기 초에 개척했다. Flourens은 동물들에게 뇌 제거 수술을 시행하여 신경계의 다른 부분을 제거하고 그들의 행동에 미치는 영향을 관찰했다. 이러한 방법은 다양한 학문에서 사용되어왔으며, 의학이나 심리학, 신경과학의 연구에서 가장 두드러지게 사용되었다.
Machine learning에서, ablation study는 "machine learning system의 building blocks을 제거해서 전체 성능에 미치는 효과에 대한 insight를 얻기 위한 과학적 실험"으로 정의할 수 있다.
Ablation study란 무엇인가?
논문을 읽던 중, ablation study 라고 하는 단어를 종종 마주할 수 있었다. 따로 논문에 이게 어떤 것인지에 대해서 설명이 없어서, 이에 대해서 정리해보고자 한다. In the context of deep learning, what is an.
cumulu-s.tistory.com
1. Introduction
Convolution Networks(convnets) : hand-written digit classification and face detection에 우수한 성능을 보여주었다.
visual classification tasks 에서도 탁월한 성능을 제공한다.
주목말한 것은 2012년 ImageNet 2012 classification benchmark, with their convnet model achieving an error rate of 16.4%, compared to the 2nd place result of 26.1%.
convnet 모델에 대한 이러한 새로운 관심에 대한 몇 가지 요인은 다음과 같습니다.
(i) the availability of much larger training sets, with millions of labeled examples;
(ii) powerful GPU implementations, making the training of very large models practical and
(iii) better model regularization strategies, such as Dropout (Hinton et al., 2012).
visualization technique
diagnose potential problems with the model => observe
multi-layered Deconvolutional Network (deconvnet)
1.1. Related Work
네트워크에 대한 직관을 얻기 위해 기능을 시각화하는 것은 일반적인 관행이지만 대부분 픽셀 공간에 대한 투영이 가능한 첫 번째 레이어로 제한됩니다. 상위 계층에서는 그렇지 않으며 활동을 해석하는 방법이 제한적입니다.
문제는 더 높은 계층의 경우 불변성이 매우 복잡하여 간단한 2차 근사로 제대로 캡처되지 않는다는 것입니다.
top-down projections
2. Approach
standard fully supervised convnet models
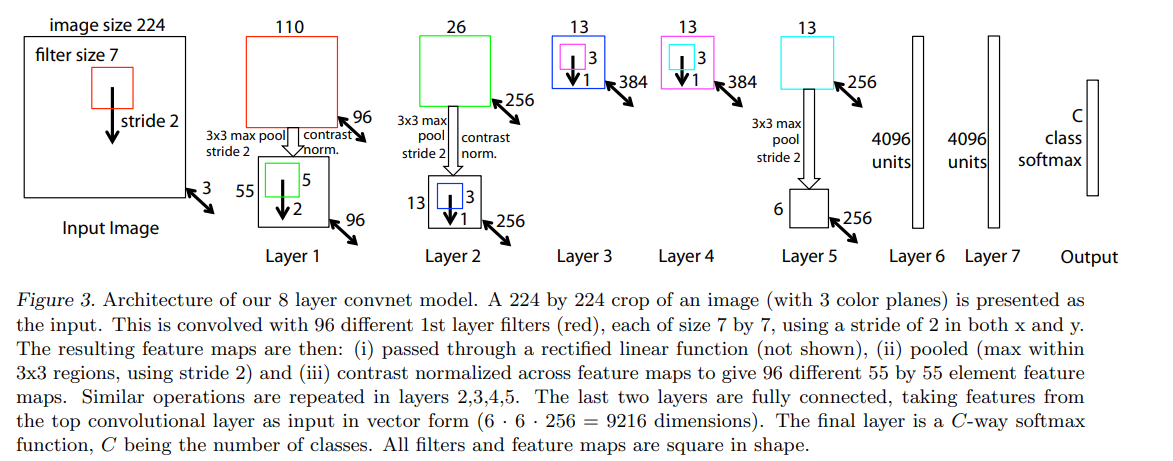
2.1. Visualization with a Deconvnet
Then we successively (i) unpool, (ii) rectify and (iii) filter to reconstruct the activity in the layer beneath that gave rise to the chosen activation.
Unpooling :
convnet에서 the max pooling operation 는 non-invertible 이지만 , 우리는 switch variables set의 각 pooling region내에서 maxima 의 위치를 기록하여 대략적인 역함수를 얻을 수 있다.
Rectification : relu non-linearities
relu 는 max(0, x) 이여서 기능 맵이 항상 양수임을 보장한다.
Filtering : deconvnet
flipping each filter vertically and horizontally
3. Training Details
One difference is that the sparse connections used in Krizhevsky’s layers 3,4,5 (due to the model being split across 2 GPUs) are replaced with dense connections in our model.
sparse connections-> dense connections
4. Convnet Visualization
Feature Visualization:
Feature Evolution during Training:
The lower layers of the model can be seen to converge within a few epochs. However, the upper layers only develop develop after a considerable number of epochs (40-50), demonstrating the need to let the models train until fully converged.
Feature Invariance:
4.1. Architecture Selection
4.2. Occlusion Sensitivity
4.3. Correspondence Analysis
5. Experiments
5.1. ImageNet 2012
Varying ImageNet Model Sizes:
5.2. Feature Generalization
Caltech-101:
Caltech-256:
PASCAL 2012:
5.3. Feature Analysis
6. Discussion
First, we presented a novel way to visualize the activity within the model.
We also showed how these visualization can be used to debug problems with the model to obtain better results, for example improving on Krizhevsky et al. ’s (Krizhevsky et al., 2012) impressive ImageNet 2012 result.
then demonstrated through a series of occlusion experiments that the model, while trained for classification, is highly sensitive to local structure in the image and is not just using broad scene context.
Finally, we showed how the ImageNet trained model can generalize well to other datasets.
참조 : 구글 번역기