Mingxing Tan 1 Quoc V. Le 1
Abstract
model scaling을 체계적으로 연구하고 network depth, width, and resolution 을 조정하여 성능 향상
a new scaling method → uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient.
EfficientNets
소스 코드 : https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
1. Introduction/2. Related Work
| depth | more layer | ResNet, VGG |
| width | channel의 개수 | Wider Residual Networks, MobileNets |
| image resolution | input image의 resolution을 키움 | Gpipe |

compound scaling method
효과적인 이유 : input image is bigger → the network needs more layer to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
3. Compound Model Scaling
3.1. Problem Formulation

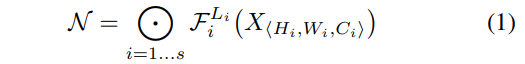

3.2. Scaling Dimensions
Depth (d): 자주 사용하는 방식
depth 를 깊이 할 경우 high level의 feature를 뽑을 수 있고 generalize 잘 되고 성능이 올라간다
하지만 어느 정도 까지 갈 경우 saturate 상태가 된다.
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks.
하지만 , networks 가 깊어지면 깊어질수록 학습하기 어렵고 vanishing gradient problem이 있다.
skip connection, batch normalization 으로 학습 문제를 완화하지만 매우 깊은 network의 정확도 이득은 감소한다. 예를 들어 ResNet-1000은 ResNet-101 비슷한 정확도를 가진다.
width(w) : small size models에 자주 사용
fine-grained features 쉽게 뽑아내고 train을 쉬운 경향이 있다.
channel을 널리면 network depth를 줄이기 때문에 higher level features이 덜 얻게 되는 문제가 있을 수 있다.
Resolution (r): capture more fine-grained patterns
| Resolution | |
| 224x224 | early ConvNets |
| 299x299 | Rethinking the inception architecture for computer vision |
| 331X331 | Learning transferable architectures for scalable image recognition. CVPR, 2018. NasNet |
| 480x480 | Gpipe: Efficient training of giant neural networks using pipeline parallelism. |
| 600x600 | Mask-RCNN, FPN |
너무 크면 정확도도 떨어지고 계산량도 많아진다.

위의 그림을 보시면 width scaling, depth scaling 은 비교적 이른 시점에 정확도가 saturation 되며 그나마 resolution scaling이 키우면 키울수록 정확도가 잘 오르는 것을 확인할 수 있다.
Observation 1 – 네트워크의 width, depth, resolution 중 어느 차원을 scale up 시켜도 성능은 향상된다. 그러나 너무 큰 모델에 있어서는 그 성능 향상이 saturate된다.
3.3. Compound Scaling
직관적으로 생각해보면 Input image가 커지면 그에 따라서 receptive field도 늘려줘야 하고 더 많은 layer가 필요하고 , resolution 이 커져서 특징들을 뽑아낼려면 더 많은 channel이 필요한 것
resolution 키우면 그것에 맞게 depth와 width도 키워야 될 것이다.

Observation 2 –성능과 효율성을 높이기 위해서 ConvNet scaling을 진행할 때, width, depth, resolution의 모든 차원의 밸런스를 맞추는게 중요하다.
compound scaling method

4. EfficientNet Architecture
MnasNet과 비슷한데 latency가 들어있지 않는다.


5. Experiments
5.1. Scaling Up MobileNets and ResNet

기존에 존재한 모델 baseline, depth, width, resolution, compound scale를 변경하여 하였지만 그중에서 compound scale의 정확도가 높았다.
5.2. ImageNet Results for EfficientNet
MnasNet: Platform-aware neural architecture search for mobile. CVPR, 2019 RMSProp optimizer with decay 0.9 and momentum 0.9 batch norm momentum 0.99 weight decay $1e^{-5}$ initial learning rate 0.256 that decays by 0.97 every 2.4 epochs SiLU (Swish-1) activation AutoAugment stochastic depth (Huang et al., 2016) with survival probability 0.8 As commonly known that bigger models need more regularization, we linearly increase dropout (Srivastava et al., 2014) ratio from 0.2 for EfficientNet-B0 to 0.5 for B7.
Table 2
정확도는 비슷하지만 parameter 수와 FLOPS수 가 적다.

parameters-accuracy and FLOPS-accuracy
our EfficientNet models are not only small, but also computational cheaper.

latency을 검증하기 위해 inference latency 도 측정 → Table 4
5.3. Transfer Learning Results for EfficientNet

Table 5 shows the transfer learning performance:
(1) Compared to public available models, such as NASNet-A (Zoph et al., 2018) and Inception-v4 (Szegedy et al., 2017),
(2) Compared to stateof-the-art models, including DAT (Ngiam et al., 2018) that dynamically synthesizes training data and GPipe (Huang et al., 2018)

Figure 6 compares the accuracy-parameters curve for a variety of models.
6. Discussion

Figure 8 Compound scaling에서 2.5%

Figure 7 class activation map (Zhou et al., 2016),
해당 통계는 Table 7에서 보여준다.
Images는 random으로 ImageNet validation set에서 선택되였다.
Figure 7에서 볼 수 있듯이 compound scaling 이 있는 model은 object details 정보가 더 많은 관련 region에 focus을 맞추는 경향이 있는 반면, 다른 models은 object details 정보가 부족하거나 이미지의 모든 objects를 capture 할 수 없다.
